Spring BOOT에서 AkkaCluster를 이용 , Spring Boot Application을 클러스터화하는것을 시도해보겠습니다.
최초 클러스터화 하는것은 어렵게 보일수 있지만, 한번 클러스터 구성이 된이후에는 분산처리 필요한 복잡한 도메인 처리를
메일박스를 가진 액터모델을 이용해 간단하게 할수있습니다. AKKACluster(이하 클러스터)의 개념을 먼저 살펴보고
Spring Boot에 탑재하여 클러스터로 작동시키는 구현 코드까지 알아보겠습니다.
목차
클러스터화 앱의 특징
| 주제 | 클러스터 | 클러스터가 아님 |
|---|---|---|
| 고성능 이벤트 분산처리 |
|
|
| TPS 분배 |
|
|
| Role기반 처리 |
|
|
| 라우터기반 분산 |
|
|
| BackPresure |
|
|
분산처리를위해 이미 클러스터화된 카프카와같은 외부 큐시스템만 할용할수도 있겠지만
우리가 설계한 클러스터는 외부시스템과도 연동할수 있으며 주로 내부앱에서 발생하는 분산처리 문제를 다룰 있으며
단독 어플리케이션이 어떻게 상호 연결되는 클러스터화가 되는지 AkkaCluster Flow를 살펴보겠습니다.
Cluster gossip
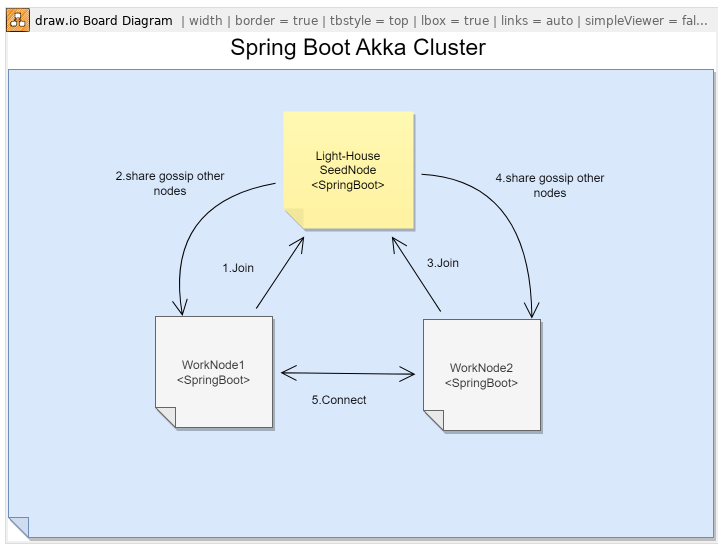
- LightHouse : 아파치의 주키퍼와 유사한 역할을 하며~ SeedNode로 불리며 이중화가 필요하면 복수개 운영할수 있습니다.
- Seed 역할은 클러스터 구성원이면 누구나 할수 있지만 도메인 로직없이 클러스터내 등대(클러스터 노드를 감시) 역할을 수행하며 업데이트 필요없이 최초 구동후 먼저 작동합니다.
- Join : 클러스터내에서 어플리케이션이 구동되면 SeedNode에 Join을 합니다.
- Gossip : Seed노드는 자신에게 연결된 모든 노드와 이야기를 하며 모든 클러스터 시스템이 상호연결될수 있도록 Discovery역할을 하게됩니다.
- Connect : Gossip을 통해 클러스터내 노드들은 서로의 위치를 발견하고 상호 연결이됩니다.
- P2P : Gossip이후 노드가 상호연결이되기때문에 단일지점 병목없이 특정 Role을 가진 노드에게 이벤트를 분산 전송할수 있습니다.
- 이러한 클러스터 컨셉은 .net core 환경에서도 유사 컨셉으로 CoreAPI를 클러스터화 할수 있습니다.
- NetCoreCluster
- 닷넷/자바 균형적발전을 위해 함께 연구하고 있으며~ 유사컨셉을 비교하거나 상대컨셉을 살펴보는것은 자신의 메인스펙을 올리는것에 도움을 줄수 있습니다.
- NetCoreCluster
클러스터에 작동하는 앱은 모두 Role기반으로 작동이되며~ 설계자에 의해 필요한 Role과 구성을 어플리케이션 레벨에서
개발자가 직접 할수 있으며 여기서 구현및 설계된 구성과 Role을 살펴보겠습니다.
Cluster Role
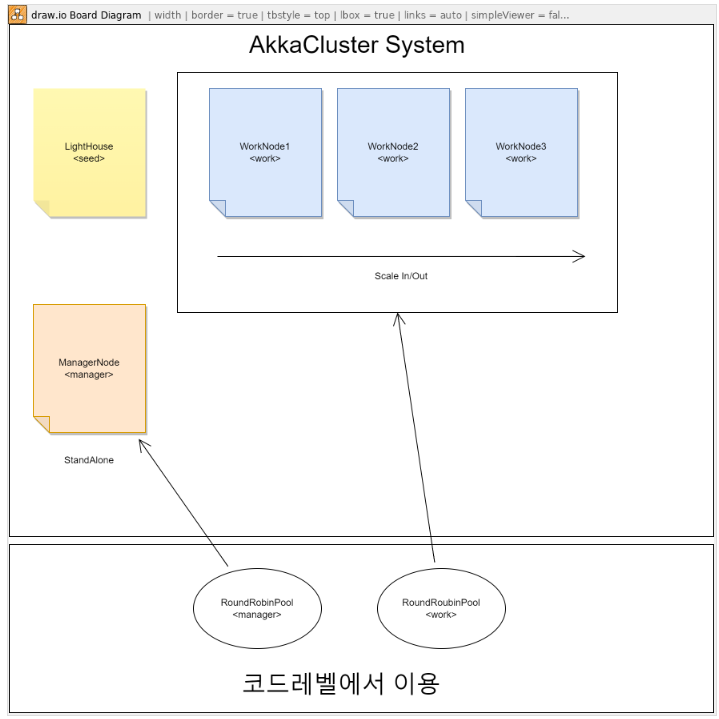
- LightHouse(Seed) : Cluster내 역할을 가진 노드들이 클러스터링 연결될수 있도록 Discovery역할을 하게됩니다.
- Role-Work : work 롤이 부여된 로드는 스케일아웃이 가능하며 최종 분산처리된 이벤트의 작업을 수행하게 되며, 작업완료는 이 작업완료를 필요로하는 Role에게 완료보고를 선택적으로 할수도 있습니다.
- Role-Manager : 클러스터내에 단하나만 작동하도록 구성하여 단일배치및 클러스터 이벤트 종합집계등 특수한 역할을 부여할수 있습니다.
- AkkaCluster에서는 SingleTone Cluster를 이용하여~ 이중화구성하여 스탠바이모드로 두개가 구성되어있지만 단 하나만 활성 작동하도록 구성할수도 있습니다.
클러스터내에 액세스하려는 실제 위치를 알필요없이 접근 가능한것을 위치 투명성(Location Transparency)이라고 불리며 클러스터 앱의 특징중 하나입니다.
WorkNode의 위치및 개수를 알필요없이~ 분산배치된 노드에 이벤트를 보내려면 액터참조자만 알고 있으면 충분합니다.
for(int i=0;i<testCount;i++){
clusterActor.tell(testMessage + i , ActorRef.noSender());
}
Nginnx와 같이 LB를 일반적으로 이용하는경우 라운드로빈과 같은 비교적 간단한 방식만 채택할수 있지만.
클러스터(AKKA)가 구성되고 나면 다음 제공되는 다양한 라우터를 사용할수 있으며
메시지 우선순위 역전과같이 필요한경우 라우터로직만 교체할수도 있습니다.
- 라우터 : 분배의 방식
- 라우팅 : 분배가 발생하는 실제 장치
- 라우티 : 분배가 도착하는 도착지
클러스터에서 이용할수 있는 라우터의 종류
이름 | 특징 |
|---|---|
|
|
|
|
| 랜덤 메시지 전송 |
|
특정 처리에 대해 해시값기반 베이스로 노드의 변경의 가능성을 최소화할때 웹소켓의 경우 hanshake를 위해 LB-l7 레이에서도 이용하는 전력으로 AKKA에서는 특정 해시이벤트가 특정노드에 작동처리 보장됨으로 네트워크로 이용해야하는 Redis보다 수십배 빠른 인 메모리 캐시를 이용할수 있습니다. |
| 기본적으로 랜덤이나, 느린놈을 제외하고 특정시간이 지나야 다시 합류시킴(일반적으로 빠른 응답속도 보장용) 옵션: |
|
|
|
|
|
성능을 위해 다중노드로 구성하였으며, 가장 빠르게 처리한 녀석의 결과를 사용할시 옵션: |
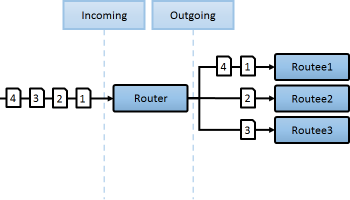
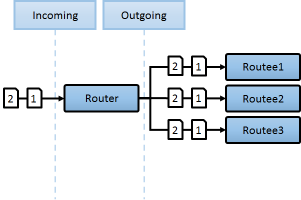
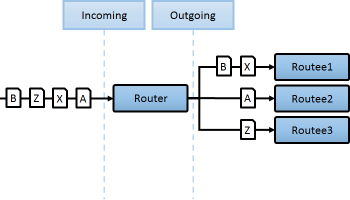
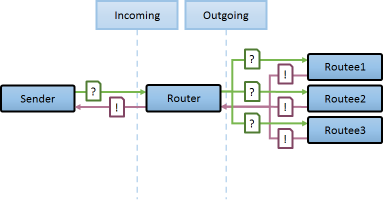
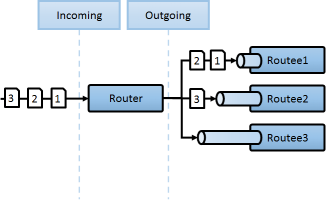
클러스터 앱에서 AKKA에서 제공하는 Router/Stream장치를 함께 이용함으로 복잡성이 높은 분산처리 문제를 간단하게 해결할수 있습니다.
Akka Stream은 다음과 같은 특징을 가지고 있습니다.
백프레셔(Back Pressure) 자동 관리: 데이터 생산자와 소비자 간의 처리 속도 차이를 자동으로 조정하여 시스템의 안정성을 유지하고 데이터 손실을 방지합니다.
모듈식 구성: 소스(Source), 플로우(Flow), 싱크(Sink) 등의 재사용 가능한 구성 요소를 통해 복잡한 데이터 처리 파이프라인을 쉽게 구축할 수 있습니다.
비동기 및 논블로킹 처리: Akka 액터 모델을 기반으로 하여 리소스를 효율적으로 활용하며, 대규모 데이터 스트림의 비동기 처리를 지원합니다.
확장성: 분산 시스템 설계를 고려하여 클러스터 환경에서의 확장성이 용이합니다.
유연한 에러 핸들링: 스트림 내 예외 상황을 세밀하게 처리할 수 있는 메커니즘을 제공합니다.
리액티브 스트림스 통합: 다른 리액티브 스트림스 구현체와의 호환성을 보장하여 상호 운용성을 제공합니다.
Throttle 메커니즘: 특정 시간 단위로 데이터 처리 속도를 조절할 수 있는 기능을 제공하여, 리소스 사용량을 제어하고 네트워크 트래픽이나 서버 부하 등을 관리할 수 있습니다. 이를 통해 시스템의 과부하를 방지하고, 스트림의 처리 속도를 세밀하게 제어할 수 있습니다.
Akka Stream은 이러한 기능들을 통해 개발자들이 복잡한 데이터 스트림 처리 문제를 더 쉽고 효율적으로 해결할 수 있도록 지원합니다. Throttle 기능은 특히, 리소스 사용을 최적화하고 시스템의 성능을 향상시키는 데 중요한 역할을 합니다.
이제 실제 작동하는 실습모드로 클러스터를 전체 구동하는것은 아파치의 주키퍼와 같은 클러스터를 띄우는 방식이 크게 다르지 않으며
Spring Boot Cluster를 다음 DockerCompose를 이용하여 여기서 소개되는 클러스터 앱을 로컬에서 모두 구동하여 테스트 해볼수 있습니다.
DockerCompose로 클러스터 전체를 구동하기
version: '3.5'
services:
light-house:
image: registry.webnori.com/javalabs-lighthouse:dev
ports:
- "8081:8080"
environment:
TZ: Asia/Seoul
akka.role: seed
akka.seed: akka://ClusterSystem@light-house:12000
akka.hostname: light-house
akka.hostport: 12000
akka.cluster-config: cluster.conf
networks:
- mynet
work-node1:
image: registry.webnori.com/javalabs-api:dev
ports:
- "8082:8080"
depends_on:
- light-house
environment:
TZ: Asia/Seoul
akka.role: work
akka.seed: akka://ClusterSystem@light-house:12000
akka.hostname: work-node1
akka.hostport: 12000
akka.cluster-config: cluster.conf
networks:
- mynet
work-node2:
image: registry.webnori.com/javalabs-api:dev
ports:
- "8083:8080"
depends_on:
- light-house
environment:
TZ: Asia/Seoul
akka.role: work
akka.seed: akka://ClusterSystem@light-house:12000
akka.hostname: work-node2
akka.hostport: 12000
akka.cluster-config: cluster.conf
networks:
- mynet
manager-node:
image: registry.webnori.com/javalabs-api:dev
ports:
- "8084:8080"
depends_on:
- light-house
environment:
TZ: Asia/Seoul
akka.role: manager
akka.seed: akka://ClusterSystem@light-house:12000
akka.hostname: manager-node
akka.hostport: 12000
akka.cluster-config: cluster.conf
networks:
- mynet
networks:
mynet:
driver: bridge
- 8080 : spring boot의 web api 포트입니다.
- 12000 : akka cluster의 listen 포트입니다.
- akka cluster 설정주입
- role : 자신의 role입니다. 동일 작동코드에서 환경을 주입하여 해당 role로 작동됩니다. 단일코드로 작동되지만 분산배치가 되어 저장소가 분리되어 작동되어야하는 코드대비 도메인 응집도를 높일수 있습니다.
- seed : seed노드인 light-house를 지정합니다.
- hostname : 자신의 hostname을 지정합니다. ip지정도 가능하지만 클러스터 간 연결및 인식가능한 별칭명칭을 사용합니다.
- hostport :
- cluster-config : 튜닝/스플릿브레인해결전력/클러스터 매트릭스등 클러스터 구동에 필요한 고급 옵션을 설정할수 있으며 파일로 분리 정의 되어 있습니다.
cluster의 고급설정을 cluster.conf에서 할수 있으며 이 파일을 base로 추가 클러스터별 필요한 설정주입을 구동단계에서 각각 조절할수 있습니다.
Cluster 설정 - cluster.conf
akka{
actor {
provider = cluster
}
remote.artery {
canonical {
hostname = "127.0.0.1"
port = 12551
}
}
cluster {
seed-nodes = [
"akka://ClusterSystem@127.0.0.1:12551"
]
role{
seed.min-nr-of-members=1
}
# auto downing is NOT safe for production deployments.
# you may want to use it during development, read more about it in the docs.
#
auto-down-unreachable-after = 10s
downing-provider-class = "akka.cluster.sbr.SplitBrainResolverProvider"
}
extensions=["akka.cluster.metrics.ClusterMetricsExtension"]
}
클러스터 내에서 일반 노드에 장애가 발생했을때 해당 노드만 빠르게 제거하고 클러스터를 문제없이 가동시키는 것은 중요합니다.
클러스터내 장애감내(허용) 를 위한 컨셉은 꼭 AKKA가 아니여도 클러스터를 단지 이용하게 되는경우도 도움될수 있습니다.
Cluster 내 Split Brain 해결전략
SplitBrain은 좌뇌/우뇌가 따로작동되어 장애가 발생하는 의학적 용어이며, 클러스터내에서 이러한 현상이 발생하게되면 심각한 문제가 발생할수 있으며 방지전략을 채택할수 있습니다.
Akka Cluster는 분산 시스템을 구축할 때 발생할 수 있는 여러 문제 중 하나인 "split brain" 현상을 해결하기 위한 다양한 전략을 제공합니다.
Split brain은 네트워크 파티셔닝(network partitioning) 때문에 클러스터가 서로 다른 분리된 하위 클러스터(sub-clusters)로 나뉘어져 서로가 나머지 부분과 통신할 수 없는 상태를 말합니다. 이러한 상황은 데이터 불일치, 중복 처리 등 여러 문제를 일으킬 수 있습니다.
아래와 같은 전략이 포함됩니다.
Static Quorum
- 특징: 정해진 수의 노드가 온라인 상태여야 클러스터가 작동하도록 요구하는 전략입니다. 이는 특히 클러스터 노드 수가 비교적 작을 때 유용합니다.
- 적용 시나리오: 클러스터가 비교적 작고, 정해진 수의 노드가 항상 온라인이어야 하는 경우.
Keep Majority
- 특징: 네트워크 분할이 발생했을 때, 가장 많은 노드를 포함하고 있는 파티션을 유지하고 나머지는 종료합니다. 이는 가장 큰 세그먼트가 클러스터의 '진짜' 상태를 가지고 있다고 가정합니다.
- 적용 시나리오: 클러스터의 가용성을 최대화하려는 경우, 특히 클러스터 크기가 크고 노드 분포가 균일한 환경에서 유용합니다.
Keep Oldest
- 특징: 클러스터 내 가장 오래된 노드가 포함된 세그먼트를 유지합니다. 이 전략은 오래된 노드가 중요한 역할을 하거나 상태 정보를 가지고 있다고 가정합니다.
- 적용 시나리오: 클러스터 내 특정 노드(예: 가장 오래된 노드)가 중요한 역할을 할 때 유용합니다.
Down All
- 특징: 네트워크 분할 상황이 발생하면 클러스터의 모든 세그먼트를 종료시킵니다. 이는 데이터의 일관성을 최우선으로 고려할 때 선택할 수 있는 극단적인 전략입니다.
- 적용 시나리오: 데이터 일관성이 매우 중요하고, 네트워크 분할 상황에서 어떠한 데이터 손실도 허용되지 않는 경우.
Lease Majority
- 특징: 외부 리소스(예: 데이터베이스)에 'lease'(임대) 개념을 사용하여 클러스터의 한 세그먼트만이 리소스를 '임대'할 수 있도록 합니다. 다른 세그먼트는 이 리소스를 사용할 수 없게 됩니다.
- 적용 시나리오: 외부 시스템이나 리소스와의 일관성을 유지해야 하고, 해당 리소스에 대한 접근을 제어할 수 있는 경우.
클러시스템을 설계하고 개발하는경우 개발 테스트를 위해 로컬에 클러스터를 유사하게 구성하는것은 중요하며
Docker + Swagger 조합으로 여기서 소개한 클러스터를 TEST할수 있습니다.
클러스터 TEST by Docker
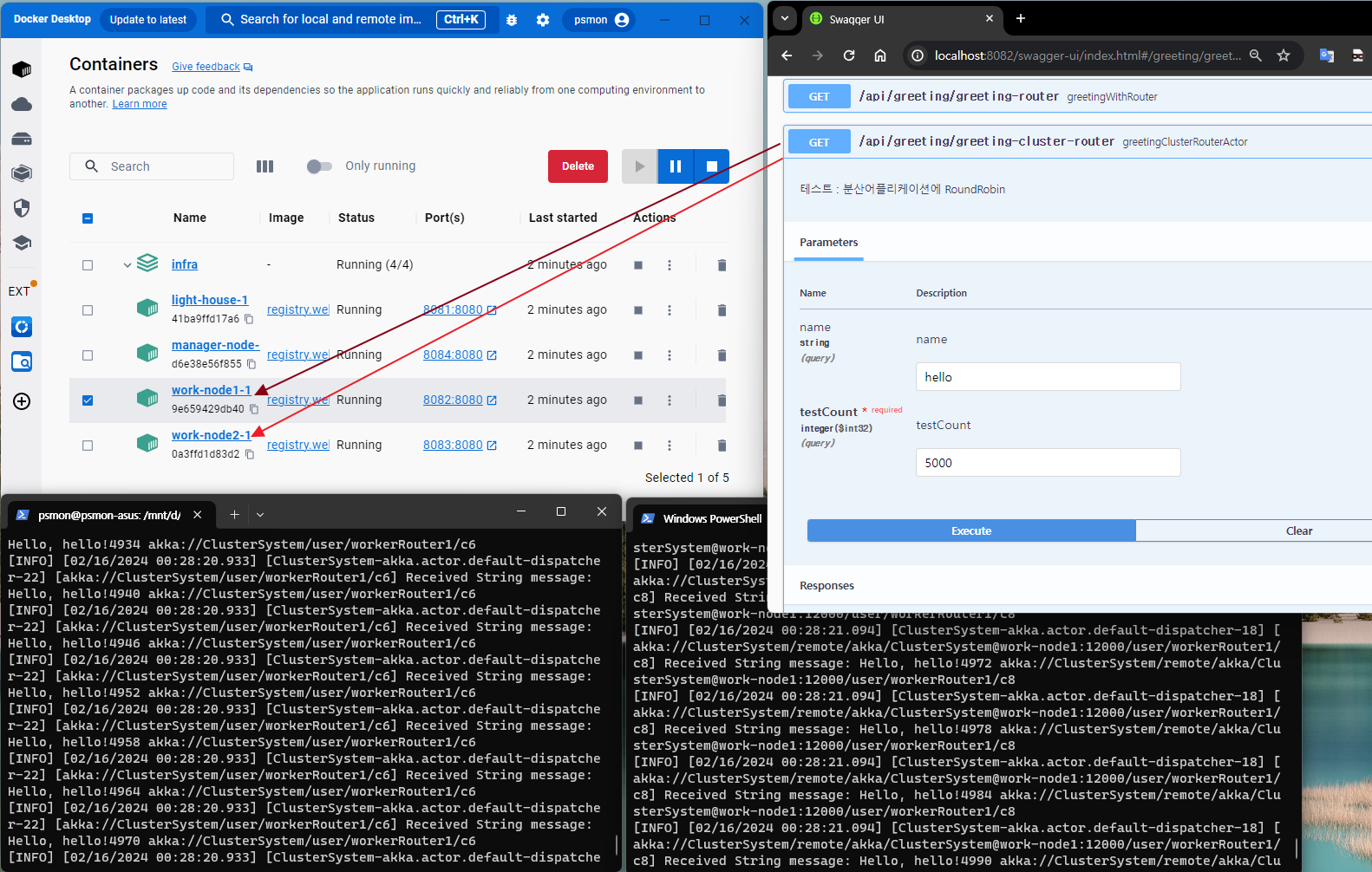
- 클러스터앱 빌드및 실행
- https://github.com/psmon/java-labs/blob/master/infra/docker-compose-cluster-local.yml
- 실험코드를 내려받고 아래 명령을 통해 로컬빌드및 클러스터 app 구동이 원큐에 가능합니다.
- javalabs\infra>docker-compose -f docker-compose-cluster-local.yml up -d
- https://github.com/psmon/java-labs/blob/master/infra/docker-compose-cluster-local.yml
주요코드 구현코드 살펴보기
Spring Boot내 AkkaSystem 탑재
@Component
public class ApplicationStartup implements ApplicationListener<ApplicationReadyEvent> {
/**
* This event is executed as late as conceivably possible to indicate that
* the application is ready to service requests.
*/
@SneakyThrows
@Override
public void onApplicationEvent(final ApplicationReadyEvent event) {
AkkaManager.getInstance();
}
}
- 싱글톤으로 수현된 사용자정의 AkkaManager를 생성함으로 SpringBoot이 시작될때 AkksSystem을 생성합니다.
Actor시스템 생성및 사용자정의 액터모델 초기 생성
// 클래스 목적 :
// Actor시스템을 생성하고, 액터관리 Spring 디펜던시 없이 로우코드로 구현
// Spring Bean 활용시 참조 : https://www.baeldung.com/akka-with-spring
public final class AkkaManager {
private static AkkaManager INSTANCE;
@Getter
private final ActorSystem actorSystem;
private String akkaConfig;
private String role;
private String hostname;
private String hostport;
private String seed;
@Getter
private ActorRef greetActor;
@Getter
private ActorRef routerActor;
@Getter
private ActorRef clusterActor;
@Getter
private ActorRef clusterManagerActor;
private AkkaManager() {
akkaConfig = System.getenv("akka.cluster-config");
role = System.getenv("akka.role");
hostname = System.getenv("akka.hostname");
hostport = System.getenv("akka.hostport");
seed = System.getenv("akka.seed");
actorSystem = serverStart("ClusterSystem", akkaConfig, role);
InitActor();
}
public static AkkaManager getInstance() {
if (INSTANCE == null) {
INSTANCE = new AkkaManager();
}
return INSTANCE;
}
boolean isEmptyString(String string) {
return string == null || string.isEmpty();
}
private ActorSystem serverStart(String sysName, String clusterConfig, String role) {
Config regularConfig = ConfigFactory.load();
Config combined;
Boolean isCluster = !isEmptyString(clusterConfig) || !isEmptyString(role) || !isEmptyString(hostname)
|| !isEmptyString(hostport) || !isEmptyString(seed);
if (isCluster) {
Config newConfig = ConfigFactory.parseString(
String.format("akka.cluster.roles = [%s]", role)).withFallback(
ConfigFactory.load(clusterConfig));
newConfig = ConfigFactory.parseString(
String.format("akka.cluster.seed-nodes = [\"%s\"] ", seed)).withFallback(
ConfigFactory.load(newConfig));
newConfig = ConfigFactory.parseString(
String.format("akka.remote.artery.canonical.hostname = \"%s\" ", hostname)).withFallback(
ConfigFactory.load(newConfig));
newConfig = ConfigFactory.parseString(
String.format("akka.remote.artery.canonical.port = %s ", hostport)).withFallback(
ConfigFactory.load(newConfig));
combined = newConfig
.withFallback(regularConfig);
} else {
final Config newConfig = ConfigFactory.parseString(
String.format("akka.cluster.roles = [%s]", "seed")).withFallback(
ConfigFactory.load("cluster"));
combined = newConfig
.withFallback(regularConfig);
}
ActorSystem serverSystem = ActorSystem.create(sysName, combined);
serverSystem.actorOf(Props.create(ClusterListener.class), "clusterListener");
return serverSystem;
}
private void InitActor() {
// Create Some Actor
greetActor = actorSystem.actorOf(HelloWorld.Props()
.withDispatcher("my-dispatcher"), "HelloWorld");
// Create Router Actor
routerActor = actorSystem.actorOf(new RoundRobinPool(5)
.props(HelloWorld.Props()), "roundRobinPool");
actorSystem.actorOf(TimerActor.Props()
.withDispatcher("my-blocking-dispatcher"), "TimerActor");
// Cluster Actor
int totalInstances = 100;
int maxInstancesPerNode = 3;
boolean allowLocalRoutees = true;
Set<String> useRoles = new HashSet<>(Arrays.asList("work"));
clusterActor =
actorSystem
.actorOf(
new ClusterRouterPool(
new RoundRobinPool(0),
new ClusterRouterPoolSettings(
totalInstances, maxInstancesPerNode, allowLocalRoutees, useRoles))
.props(Props.create(ClusterHelloWorld.class)),
"workerRouter1");
Set<String> useManagerRoles = new HashSet<>(Arrays.asList("manager"));
clusterManagerActor =
actorSystem
.actorOf(
new ClusterRouterPool(
new RoundRobinPool(0),
new ClusterRouterPoolSettings(
totalInstances, maxInstancesPerNode, allowLocalRoutees, useManagerRoles))
.props(Props.create(ClusterHelloWorld.class)),
"workerRouter2");
}
}
- Spring Boot에서 지원하는 DI를 활용해도 되지면 여기서는 SpringBoot이외에서도 이용될수 있게 의존없이 구현되었습니다.
- serverStart() : AkkaSystem을 생성합니다.
- InitActor : 사용자정의 로컬액터를 포함 사용자정의 구현된 클러스터 액터를 생성합니다.
클러스터 기능을 가진 사용자 정의 액터모델구현
public class ClusterHelloWorld extends AbstractActor {
private final LoggingAdapter log = Logging.getLogger(getContext().getSystem(), this);
Cluster cluster = Cluster.get(getContext().system());
public static Props Props() {
return Props.create(ClusterHelloWorld.class);
}
//subscribe to cluster changes
@Override
public void preStart() {
cluster.subscribe(self(), (ClusterEvent.SubscriptionInitialStateMode) ClusterEvent.initialStateAsEvents(),
ClusterEvent.MemberEvent.class, ClusterEvent.UnreachableMember.class);
}
@Override
public void postStop() {
cluster.unsubscribe(self());
}
@Override
public Receive createReceive() {
return receiveBuilder().match(ClusterEvent.MemberUp.class, mUp -> {
log.info("Member is Up: {}", mUp.member());
}).match(ClusterEvent.UnreachableMember.class, mUnreachable -> {
log.info("Member detected as unreachable: {}", mUnreachable.member());
}).match(ClusterEvent.MemberRemoved.class, mRemoved -> {
log.info("Member is Removed: {}", mRemoved.member());
}).match(ClusterEvent.MemberEvent.class, message -> {
// 구현가능 분산처리 메시지 사용자 정의부분
}).match(String.class, s -> {
log.info("Received String message: {} {}", s, context().self().path());
})
.match(TestClusterMessages.Ping.class, s -> {
log.info("Received Ping message: {}", context().self().path());
})
.build();
}
}
- 로컬액터를 클러스터화 : Cluster 객체를 가지고 구독/구독중지 코드만으로 로컬액터가 클러스터화가됩니다. 로컬액터만 이용후 리모트가필요한 클러스터로 전환시 코드변경이 최소화 할수 있는 장점이 있습니다.
- 클러스터 이벤트 수신 : 클러스터에 발생하는 Meber 이벤트를 모니터링용으로 수신받을수 있습니다. 그 이외에는 메일박스를 통해 자바객체별로 수신가능한점은 로컬액터와 동일합니다.
클러스터를 통해 분산처리 TPS제어 복잡성을 단순화하기
지금까지 클러스터툴을 통해 다음과 같은 툴이 제공됨을 알게되었습니다.
- 단일지점 Role 액터처리
- 동적으로 도메인 생성및 , 도메인단위처리
- TPS 측정장치 탑재가능
- Round Robind 기반 분산처리
이러한 장치를 조합해다음과같이 분산처리 시스템에서의 문제를 단순화할수 있습니다.
- 클러스터내에 가입만되어 있으면 도메인단위로 발생하는 어떠한 유형의 트래픽이던지 도메인단위로 TPS제어를 할수있습니다.

클러스터로 확장되어 단일장비가 아닌 클러스터에 가입한 전체 노드내에서 TPS 제어가가능해집니다.
다음은 클러스터가 없는 분산처리 컨셉으로 아래의 개념이 위와같은 형태로 확장이될수 있습니다.
클러스터 유닛테스트
@SpringBootTest
public class FactorialTest {
private static Logger logger = LoggerFactory.getLogger(FactorialTest.class);
private static ActorSystem clusterSystem1;
private static ActorSystem clusterSystem2;
private static ActorSystem clusterSystem3;
private int maxServerUptime = 20;
private static ActorSystem serverStart(String sysName, String config, String role) {
final Config newConfig = ConfigFactory.parseString(
String.format("akka.cluster.roles = [%s]", role)).withFallback(
ConfigFactory.load(config));
ActorSystem serverSystem = ActorSystem.create(sysName, newConfig);
serverSystem.actorOf(Props.create(ClusterListener.class), "clusterListener");
return serverSystem;
}
@BeforeClass
public static void setup() {
// Seed
clusterSystem1 = serverStart("ClusterSystem", "server", "seed");
// Works Nodes
clusterSystem2 = serverStart("ClusterSystem", "factorial", "backend");
clusterSystem2.actorOf(Props.create(FactorialBackend.class), "factorialBackend");
clusterSystem3 = serverStart("ClusterSystem", "factorial", "backend");
clusterSystem3.actorOf(Props.create(FactorialBackend.class), "factorialBackend");
logger.info("========= sever loaded =========");
}
@AfterClass
public static void gracefulDown() {
clusterSystem3.terminate();
clusterSystem2.terminate();
clusterSystem1.terminate();
logger.info("========= sever down =========");
}
@Test
public void clusterTest() {
logger.info("========= client start =========");
final int upToN = 200;
final Config config = ConfigFactory.parseString(
"akka.cluster.roles = [client]").withFallback(
ConfigFactory.load("factorial"));
final ActorSystem system = ActorSystem.create("ClusterSystem", config);
system.log().info("Factorials will start when 2 backend members in the cluster.");
new TestKit(system) {
{
ActorRef probe = getRef();
Cluster.get(system).registerOnMemberUp(new Runnable() {
@Override
public void run() {
ActorRef frontActor = system.actorOf(Props.create(FactorialClient.class, upToN, false),
"factorialClient");
frontActor.tell(new FactorialRequest(upToN), probe);
}
});
expectMsgClass(Duration.ofSeconds(maxServerUptime), FactorialResult.class);
}
};
}
}
N개의 시스템을 구성하고 구현된 클러스터 시스템 자체를 유닛테스트할수 있게만드는것은 클러스터 개발속도를 가속화 할수 있습니다.
이러한것이 준비되지 않으면 복잡한 클러스터 시스템을 항상 띄우고 개발중 기능확인을 매번해야하기 때문입니다.
Spring Boot 클러스터 셋업및 실행 요약
- Seed역할을 하는 도메인코드가 없는 LightHouse 구현
- 도메인 로직을 처리하는 Spring BOOT 어플리케이션을 생성하고 ActorSystem 탑재
- 분산처리가 필요한 로직을 클러스터 액터로 구성하고 구현
- 클러스터 구성및 성능과관련한 설정을 파일로 분리하고 정의
- 클러스터 설계가 완료되면 빌드를 포함 로컬에서 클러스터 시스템 전체를 구동
- 클러스터 기능확인을 위한 유닛테스트 구성
추가 연관 컨텐츠
다음 컨텐츠는 클러스터 모드가 아니여도 Akka가 제공하는 유용한 실제 이용사례를 조금더 살펴볼수 있습니다.
클러스터화 함께 이용하는 경우 복잡성이 높은 분산처리 문제를 조금더 쉽게 풀어갈수가 있습니다.
Next
로컬및 개발환경에서는 비교적 구성이 쉬운 docker-compose를 이용할수 있으나 운영환경에서는 이제 사실상 배포운영에 표준이된 쿠버 인프라환경을 이용하게 됩니다.
Spring 환경에서 AkkaCluster를 직접 설계하고 구성한것을 RKE-쿠버를 이용해 쿠버 클러스터내에서 작동을 준비예정에 있습니다.
일반적으로 RestAPI와 같이 StateLess한 서비스를 POD로 작동하고 LB를 Ingress화 하는 쿠버의 기본요소를 이용하는것보다
Discovery기능을 이용해야하는 클러스터화된 스택을 쿠버에 구성하는것은 일반적으로 조금더 난이도가 있을수 있으며
쿠버는 클러스터화된 스택자체를 구성하고 안정적으로 운영하는 기능자체도 제공하게 됩니다.
Add Comment