책임이 분리된 팀이 생성한 데이터를 이용해야할때 일반적으로 카프카 연결기를 두고 필요한 데이터를 소비함으로 데이터를 재구성할수 있습니다.
하지만 팀을 넘어 이것이 외부 공급사의 데이터인 경우 다음과 같은 정책적인 문제로 DB를 포함 Kafka를 활용하는것에 제약이 있을수 있습니다.
- DB를 상호간 공유하는것은 책임이 분리된 팀간 서비스에서도 가급적 공유 안하는것이 좋지만, 다른 회사간 DB공유는 통상적으로 금기사항입니다.
- 카프카와 같은 큐를 연동하여 스트림으로 제공받을수 있으면 좋겠지만 타 회사간의 데이터 제공을 스트림으로 제공하는것 역시기술적문제보다는 보안정책적 문제로 진행되기 어렵습니다.
카프카는 데이터를 제공하는 좋은 기술임에도 불구 양사간 데이터 협약을 한다고 해도 이것을 이용하기는 정책상 어려울수 있습니다.
그래서 여전히 데이터를 제공하는 쪽은 API를 이용할수 있는 접근보안기능과 함께 , API의 이용제약및 이용료가 포함된 API형태로 제공하고 이용하는것이 일반적입니다.
협약된 API를 통해 조회권한 내에서만 이용하여 새로운 서비스에 필요한 데이터를 재 구성할수 있습니다.
이것은 공개된 API라고 할지라도 이용량이 높을시 과금및 호출 제약이 있을수 있습니다.
대용량의 데이터를 일반적인 Rest-API를 이용하여 제약내에서 대용량 분산 처리할수 있는 기술적 주제를 다루어 보겠습니다.
API를 통해 수집해야할 종류는 다음과 같은 것이 될수 있습니다.
- 상품정보
- 주문정보
- 고객정보
- 예약정보(항공,숙박)
- 구매정보(패션,생황용품)
API의 한계와 안전한 수집전략
대량의 데이터를 수집하기위해 API방식은 다음과 같은 한계가 존재합니다.
- 호출한번으로 대량의 데이터를 획득하기 어렵습니다.
- API는 폴링방식이며 실시간 이벤트를 획득하기 어렵습니다.
- API에는 호출제약이 존재하며 공급사가 제공하는 TPS이내에서만 호출해야합니다.
이러한 제약을 해결하기위해서는 다음과 같은 전략이 추가로 필요하게됩니다.
- 채널별(논리구성별)로 TPS를 제약할수 있는 방법
- 호출량을 최소화해서 스마트하게 스캔하는 방법과 증분처리하는 방법
- 상품 정보 : 상품 생성일 단위
- 항공예약 : 공항코드 + 출발날짜
- 업데이트 된 정보를 갱신하는방법
- 회원정보 : 최근 로그인 날짜를 스캐닝하여 정보업데이트
- 삭제된 정보를 갱신하는방법
- 삭제처리 조회 API를 추가로 활용하거나 Webhook이용
수집명령단위
API를 호출해야하는 수집기가 분산처리 되기위해서 수집명령 단위는 너무 크지도 않고 너무작지도 않은 적절한 수준이여야 하며
이 명령은 실행되는 위치만 고려해야하는것이 아닌 수행되는 시간고려되어 분산처리를 고민해야합니다.
이 단위가 너무 크면 분산처리로 보기 어려우며, 너무 작으면 수집 명령 이벤트 자체의 빈도가 비대해질수도 있습니다.
커피주문기의 간단한 예를 들면 커피주문 명령을 내릴수 있지만~ 세부적인 커피 제조명령(얼음을 3개까지 타)까지 할 필요가 없음을 의미합니다.
제조명령까지 내리게되면 수집스케줄러는 커피를 타는 공정을 모두 알아야하며 너무 많은 명령을 관리하게 됩니다.
수집을 처리하는 목적및 효율에 따라 수집명령의 세부명령 수준이 각각 다르게 설계될수 있습니다.
수집분산 단위
작동 위치 분산설명을 위해 채널 A/B로 구분하였으나 수집을 처리하는 수집기는 유연하게 스케일 in/out이 되어야 하기 때문에 위치 투명성을 지원해야합니다.
이것은 어디에 작동되어도 상관없이 수행되어야함을 의미하며 카프카 파티션 구성과 연동되어 유연한 분산처리가 가능을 의미하게 됩니다.
즉 작업의 A/B의 분산룰은 작업량이 적은 노드에게 자동 분배가 될수 있습니다.
작동시간 분배는 자동이아닌 계획을 할수 있으며 더 우선으로 진행되어야 할 채널이 있는 경우 작동시간 조정을 통해 우선순위를 조정할수도 있습니다.
더 세부적인 Task단위는 수집명령을 받은 수집기에서 명령을 분해해 단일장비를 통해 동시처리를 진행할수 있어야하며
단일장비내에서 동시성과 제약을 고려 복잡한 도메인 처리과정을 액터모델을 통해 다시 세부적으로 표현을 해보겠습니다.
노드 분산처리는 일반적인 카프카의 파티션 분산 전략을 이용하고 있고 카프카의 일반적인 전략이기 때문에 생략을 하며
이것을 카프카가 발생한 메시지의 단일장비 병렬,동시성 처리라고 정의를 해보겠습니다.
단일 시스템에서 액터의 논리적 구성
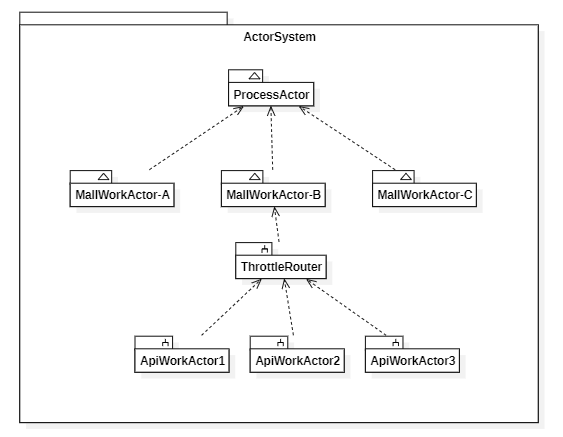
- ProcessActor : 발생하는 수집명령은 이곳에 최초 도달하며 채널(여기서는 Mall로표현)액터단위로 분기 전달 처리가됩니다. 하나의 액터는 순차성을 보장합니다.
- MallWorkActor : 수집명령은 최근1개월을 수집해와 같은것이지만, API호출은 N개가 될수 있습니다. 작업을 더 작은 단위로 나누어 Apiwork에게 작업위임을 합니다.
- API의 호출량이 제약적이기 떄문에 조절지가 앞단에 탑재되어 작업량을 조절합니다.
- Worker가 꼭 TPS개수와 동일할 필요는 없습니다. RoundRobinRouter를 이용하여 작업자를 확보할수 있습니다.
- 만약 API호출후 후속적인 동기화 작업이 필요하다고 하면 이 작업자를 늘려 Throttle에 적용된 TPS를 준수할수 있습니다.
- ApiWork : 순수하게 명령받은 API을 호출한후 그 결과를 부모액터(MallWOrkActor)에게 비동기적으로 보고합니다.
이제 수집처리기의 액터 구성 설계를 했고 수집처리를 위한 액터메시지 의 흐름을 설계를 해보겠습니다.
액터 메시지 Flow
액터의 이벤트 메시지흐름은 UML_Sequence Diagram을 통해 설명할수 있으며 여기서 작성한 모델과 액터의 작동을 일치시킬수 있습니다.
액터는 각각 순차처리 보장되는 메일박스를 가지고 있으며 참조를 통해 비동기적으로 이벤트를 전송할수 받을수도 있기떄문입니다.
멀티스레드의 동시성 문제를 해결하기위해 메시지큐를 가지고 꺼내어 처리하는 방식이 액티브오브젝트 패턴이며
액터의 작동방식은 액티브오브젝트 패턴과 동일합니다.
카프카 작동방식 역시 액티브오브젝트 패턴으로 분류될수 있으며 이 액티브오브젝트 패턴은 액터모델과 상관없이 게임서버에서는 일반적으로
직접 구현해서 사용하며, 카프카는 웹진영에서 그것을 구현없이 쉽게 이용할수 있는 큐시스템입니다.
이러한 초기 개념은 언랭의 창시자 무려 40년 전인 1973년에 칼 휴이트라는 사람이 제안했던 개념이다. 휴이트의 개념은 얼랭(Erlang)이라는 언어로 구체화되었고
스웨덴 통신회사인 에릭슨(Ericsson)에서 고도의 동시성 프로그램을 구현할 때 실제로 사용되었습니다. - 액티브오브젝트 패턴의 기원
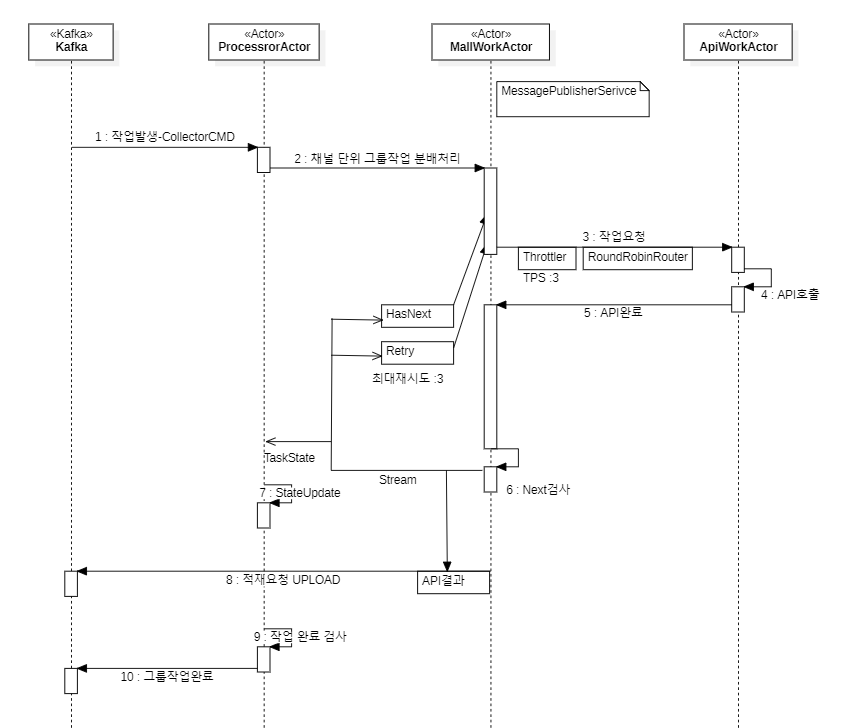
우리의 도메인 이벤트의 흐름에 따라 작동 플로우를 시퀀스 다이어그램을 통해 구현전 설계를 할수 있으며
여기서 만든 모델은 액터구현을 통해 해당 적용할수 있습니다.
우선 액터모델이 표현하려는 중요 이벤트는 다음과 같이 표현될수 있습니다.
- 분산처리되는 최소 수집명령은 카프카를 통해 전달되며 CollectCMD 토픽을 통해 시작합니다.
- 이 커멘드 명령에는 수집에 필요한 최소정보가 포함되어있습니다.
- 수집대상 채널
- 날짜범위
- 수집대상
- 최초생성 or 증분업데이트
- ProcessActor는 작업자를 채널단위로 실시간 생성하고 유지할수 있습니다.
- 채널(Mall)을 담당하는 작업자는 API를 얼만큼 호출해야하는것을 결정하고 스캔범위를 조정해가며 완료까지 도달합니다.
- 부모와 자식구조로 구성된 액터는 상호간 이벤트 전송을 할수 있으며 자식액터는 작업완료를 실시간 비동기로 보고할수 있습니다.
- API결과는 작은단위 지속적으로 업로드요청을 할수 있습니다. 전체가 다 완료되고 적재하는것보다 부분적으로 발생한 데이터를 지속 정크처리하는것이 DB의 부하역시 시간으로 분산할수 있습니다.
- 루트 액터인 ProcessActor는 하위 작업을 모두 감시할수 있으며 수집명령이 모두완료되면 이것을 검사하여 완료 통보를 할수 있습니다.
- 완료 통보를 할수 있기때문에 완료가 되지 않은 상태를 수집명령기가 알기때문에 중복작업 요청을 하지 않을수 있으며 다음 수집 스케줄을 계산할수 있습니다.
코드속에 설계가 녹아들어 실제 작동되는것을 만드는 실천형 아키텍트를 지향하며 마지막으로 위 설계요소중 중요 구현요소를 살펴보겠습니다.
주요 구현코드
유닛테스트
@Test
@DisplayName("TPS 분배테스트")
public void TPSTest() throws Exception{
new TestKit(system){{
final TestKit probe = new TestKit(system);
processorActor = system.actorOf(SPRING_EXTENSION_PROVIDER.get(system).props("processorActor"), "processor");
for(int i=0 ; i < 100 ; i++){
processorActor.tell(new TestCollectWorkEvent("MallA","test1", 1, probe.getRef()), ActorRef.noSender());
processorActor.tell(new TestCollectWorkEvent("MallB","test1", 1, probe.getRef()), ActorRef.noSender());
processorActor.tell(new TestCollectWorkEvent("MallC","test1", 1, probe.getRef()), ActorRef.noSender());
processorActor.tell(new TestCollectWorkEvent("MallE","test1", 1, probe.getRef()), ActorRef.noSender());
}
int testCount = 100 *4;
within(
Duration.ofSeconds(100),
() -> {
for (int i = 0; i < testCount; i++) {
// check that the probe we injected earlier got the msg
probe.expectMsg(Duration.ofSeconds(5), "done");
}
// Will wait for the rest of the 3 seconds
expectNoMessage();
return null;
});
}};
}
- 채널(Mall)단위로 TPS3으로 실제작동하고 유실없이 전달되었는지 수신이벤트를 검증하는 코드입니다.
- 도메인로직을 다 작성하고 중요한 장치를 마지막에 탑재를 한후 의도대로 작동되지 않는다면 우리의 설계가 잘못됨을 뒤늦게 알게되어 작성코드의 설계를 모두 변경해야할수도 있습니다.
- 런칭 직전 이 문제를 발견하고 이 문제를 안고 운영한다고하면 우리는 엄청난 운영고통을 겪을수 있습니다.
- 기능단위 수준의 검증활동이 구조변경으로 모두 헛수고가 될수 있습니다.
- 중요한 장치는 유닛테스트화해 해당 구조적 설계를 이용할수 있게 도메인 로직 구성전 먼저 작성하는것이 중요합니다.
- 도메인로직을 다 작성하고 중요한 장치를 마지막에 탑재를 한후 의도대로 작동되지 않는다면 우리의 설계가 잘못됨을 뒤늦게 알게되어 작성코드의 설계를 모두 변경해야할수도 있습니다.
논리적 단위로 액터모델 동적생성
.match(CollectorMessage.class, event -> {
ActorRef workActor = mallWorkActors.get(event.getMallId());
if(workActor == null){
workActor = context().actorOf(SPRING_EXTENSION_PROVIDER.get(getContext().getSystem()).props(
"mallWorkActor"), "MallWorkActor-" + event.getMallId());
mallWorkActors.put(event.getMallId(), workActor);
}
workActor.tell(event, ActorRef.noSender());
})
- 채널(Mall) 단위처리를 동적으로 생성하게 됩니다. 액터는 스레드와 비교 다음과 같은 장점이 있습니다.
- 200백만개의 액터가 사용하는 메모리는 1GB이면 충분하며 스레드 생성보다 비용이 훨씬저렴합니다. - 스레드 1은 1mb의 비용이 높은 스택메모리를 사용합니다.
- 동적으로 생성하는 스레드대비 , 생성후 최초메시지 수신처리되는 시간역시 스레드모델에 비해 훨씬 짧습니다.
- 추가적으로 액터로 설계된 모델은 , 리모트또는 클러스터로 도메인로직 코드의 수정없이 최소한의 설정으로 전환이 가능합니다.
- 스레드를 원격으로 제어할수 있는방법은 존재하지 않으며 있다고해도 OS레벨의 수준을 획득하는것은 보안의 원칙에도 어긋나게됩니다.
작업자 개수와 속도조절기 탑재
// API Work Node -5
List<String> paths = new ArrayList<>();
for (int i = 0; i < 5; i++) {
ActorRef r = context().actorOf(SPRING_EXTENSION_PROVIDER.get(getContext().getSystem()).props("apiWorkActor"), "apiWorkActor-" + i);
paths.add( "/user/" + context().parent().path().name() + "/" + context().self().path().name()+ "/" + r.path().name() );
}
apiWorkRouter = getContext().actorOf(new RoundRobinGroup(paths).props(), "apiWorkRouter");
// Api TPS2 per MALL
int processCouuntPerSec = 2;
throttler =
Source.actorRef(50000, OverflowStrategy.dropNew())
.throttle(processCouuntPerSec, FiniteDuration.create(1, TimeUnit.SECONDS),
processCouuntPerSec, (ThrottleMode) ThrottleMode.shaping())
.to(Sink.actorRef(apiWorkRouter, akka.NotUsed.getInstance()))
.run(materializer);
- 채널에 작업자를 충분히 설정할수 있으며 이것은 병렬적으로 실행될수도 있습니다.
- RoundRobinGroup을 통해 순차 분배기를 탑재합니다.
- Akka의 조절 스트림기를 전방에 탑재하여 TPS를 제어할수 있습니다.
- 작업명령을 throttler에게만 할수있으며 이 조절기는 TPS를 제어하여 apiWorkRouter가 안정적으로 일을할수 있게 흐름을 제어합니다.
연관 참고자료
NEXT
- 분산처리를 다루는 개발자가 AKKA를 학습하면 도움되는 이유
- Akka Cluster with Spring BOOT - 분산처리 개념을 클러스터로 확장하는 방법
Add Comment