
오늘날의 데이터는 예측하지 못하는 데이터가 다양한 스트림으로부터 발생하며 , 이로 인해 생산과 소비처리의 성능차이가 나기시작하면서 다양한 문제가 발생합니다.
빠른생산자와 느린 소비자(API호출)의 문제를 심플하게 풀수 있는 BackPresure 컨셉을 그림과 함께 알아보겠습니다.
API호출에서 빠른생산과 느린소비

- 빠른생산 : API를 이용해야하는곳은 불규칙적으로 동시 요청을 보냄
- 느린소비 : API를 제공하는곳은 정보를 제공하며 응답을 받아 최종처리하는 요청속도를 따라가지못해 소비지점은 점점 느려지는 상황발생~
API호출에서 외부제공 API를 호출하기 위해 느린소비를 해결하기 위해 다음과 같이 문의하거나 요청할수 있습니다.
- 우리가 가장 빠르게 이용할수 있는 TPS를 알려주세요?
- TPS 를 높여주세요?
또는 다른 개발사가 우리 API를 사용하고 있다고 가정해봅시다. 해당 개발사는 유사한 질문을 합니다.
- 호출가능한 최고 TPS는 몇인가요?
- 어떻게 호출을 해야 가장 빠르고 안전하게 정보를 획득할수 있나요?
단순하게 TPS를 맞추는것만으로 빠른생산과 느린소비의 차이를 메꿀수 없습니다.
항상 안정적으로 작동하는 TPS를 맞추기위해서는 최소또는 중간값을 이용하는게 일반적입니다.
시스템이 안정적이여도 네트워크 경로라는 예측불가한 지연시간이 존재하며
내부 개발팀간에는 안정적인 최고의 TPS를 찾아가며 성능개선 활동을 함께 할수 있지만
우리가 사용하는 API가 OHS(Open Host Service) 인경우 최고성능을 내는 TPS를 이용할수는 없음은 명확합니다.
이러한 관계를 표현하고 제약을 표현하는 OHS는 무엇이고 ACL이 무엇인지 먼저 살펴보겠습니다.
DDD에서 Bounded Context 관계를 그리는방법
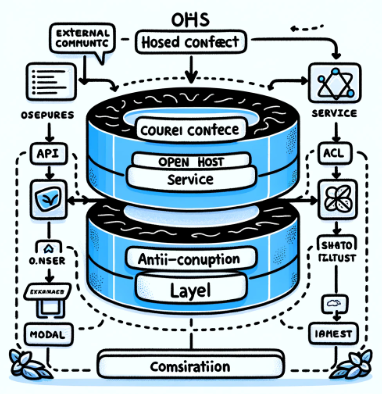
Open Host Service (OHS):
- 목적: OHS는 특정 Bounded Context의 기능을 외부에 제공하기 위한 표준화된 인터페이스입니다. 이를 통해 다른 Bounded Context 또는 외부 시스템이 이 컨텍스트의 기능을 쉽게 사용할 수 있습니다.
- 사용 사례: OHS는 일반적으로 RESTful API, SOAP 서비스, RPC와 같은 웹 서비스로 구현됩니다. 다른 시스템이 이 서비스를 통해 해당 Bounded Context와 통신할 수 있습니다.
- 역할: 내부 구현을 숨기면서 표준화된 방식으로 서비스를 제공합니다.
Anti-Corruption Layer (ACL):
- 목적: ACL의 주요 목적은 한 Bounded Context가 다른 Context의 모델이나 로직에 '오염되지 않도록' 보호하는 것입니다. 이를 통해 내부 모델을 외부 모델의 변화로부터 보호하고, 컨텍스트 간의 의존성을 줄입니다.
- 사용 사례: 다른 시스템이나 컨텍스트와 통합할 때, ACL은 외부 시스템의 데이터나 요청을 내부 모델로 변환하는 역할을 합니다. 예를 들어, 외부 시스템에서 온 데이터를 내부 도메인 객체로 매핑하거나, 내부 비즈니스 규칙에 맞게 요청을 조정합니다.
- 역할: 외부의 영향으로부터 내부 모델을 보호하고, 필요한 데이터 변환을 수행합니다.
우리가 대부분 이용해야하는 외부API Context는 Open Host Service로 이루어져 있습니다.
이 특징은 이것을 이용하는측에서의 요청이 대부분 수용되지 않을 가능성이 있으며, OpenHost가 제공하는것을 그대로 이용해야합니다.
사소한 모델 개선도 특정 개발팀을 위해 적용해주는것은 수용되기 어려운 특징이 있으며 주로 다양한 OHS를 이용하고
정리된 모델을 하위스트림에 제공해야하는 경우 도메인 모델이 오염되지 않도록 ACL이라는 반부패계층을 만들게 됩니다.
당연히 OHS에게 성능을 늘리거나 TPS를 보장하는것을 요구하기는 어려울수 있으며
성능차이로 시스템이 중지되거나 유실이 발생한다고 하면 도메인 모델이 부패가 되기도 전에 , 부패할 이벤트 자체가 발생하지 않는 더 큰 이슈가 생길수 있습니다.
우리의 도메인 모델이 안전하게 생성되기위해 OHS → ACL 구간의 생산과 소비의 속도 조절은 중요합니다.
하지만 그 구간의 성능에 차이가 난다란것을 측정하지 않고 어떻게 알수 있을까?
측정하지 못하면 개선할수 없다.

오늘날의 분산처리 에서 성능개선은 처리량을 단순하게 늘려 가는 것만을 이야기하지 않습니다.
이 분야에서는 한때~ 멀티스레드 vs 단일스레드 동시성 처리 누가 더 빠른지 자체만을 대결하는 벤치마크 활동이 활발할때가 있었지만
분산환경에서 전체 처리 성능을 높이기 위해서는 단일지점 병목현상을 잘 다뤄야하며, 이 지점이 대부분 마지막 소비를 처리하는 어플리케이션 지점이 될 가능성이 높습니다.
그래서 오늘날의 성능개선의 주요주제는 단순하게 처리량을 높이기보다는 소비의 속도를 고려 생산의 속도를 조절할수 있어야하는 전략도 필요하게 되었습니다.
이러한 관점에서 이벤트가 흘러가는 파이프라인 기준으로 각지점을 모니터링할수 있어야하고 측정해야하는것은 중요해졌습니다.
- CPU / 메모리 / 네트워크량 등을 볼수 있는것은 시스템 모니터링으로 기본입니다.
- 어플리케이션이 발생시키는 내부 상태및 이벤트처리량을 시스템 모니터링과 함께 볼때 개선지점을 찾을수 있으며~ APM(Application Performance Monitor) 이라고 불립니다.
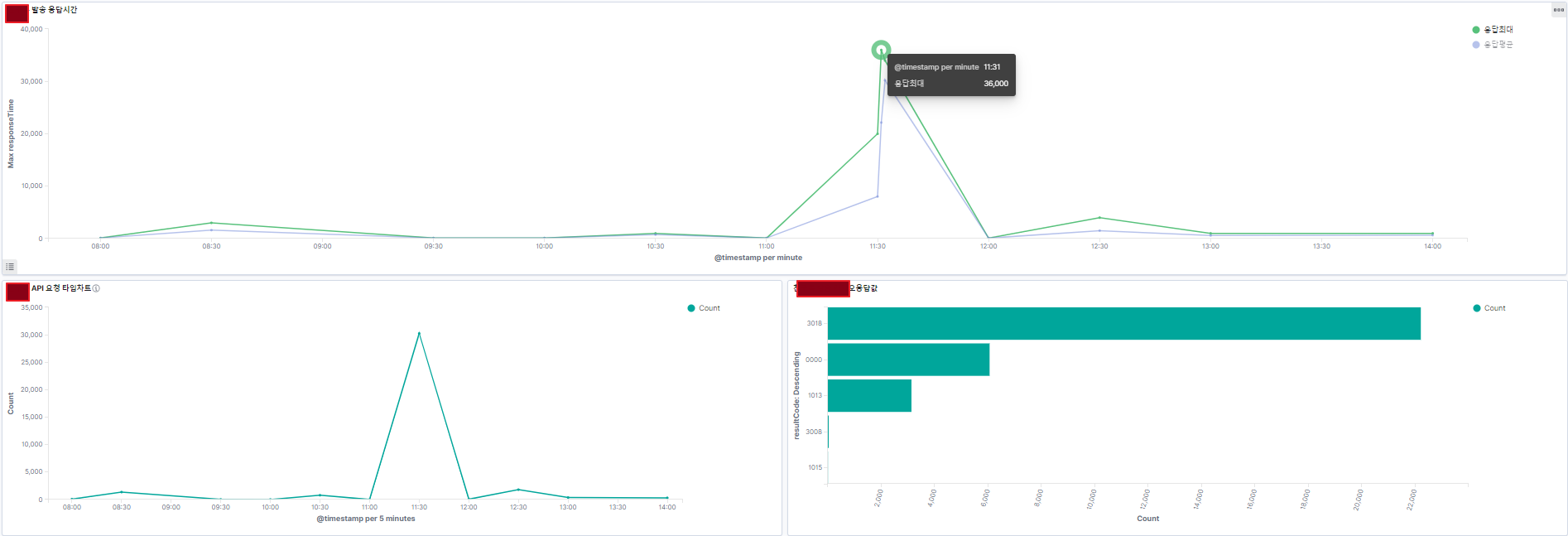
로그 트래픽을 측정할수 있는 대시보드 샘플
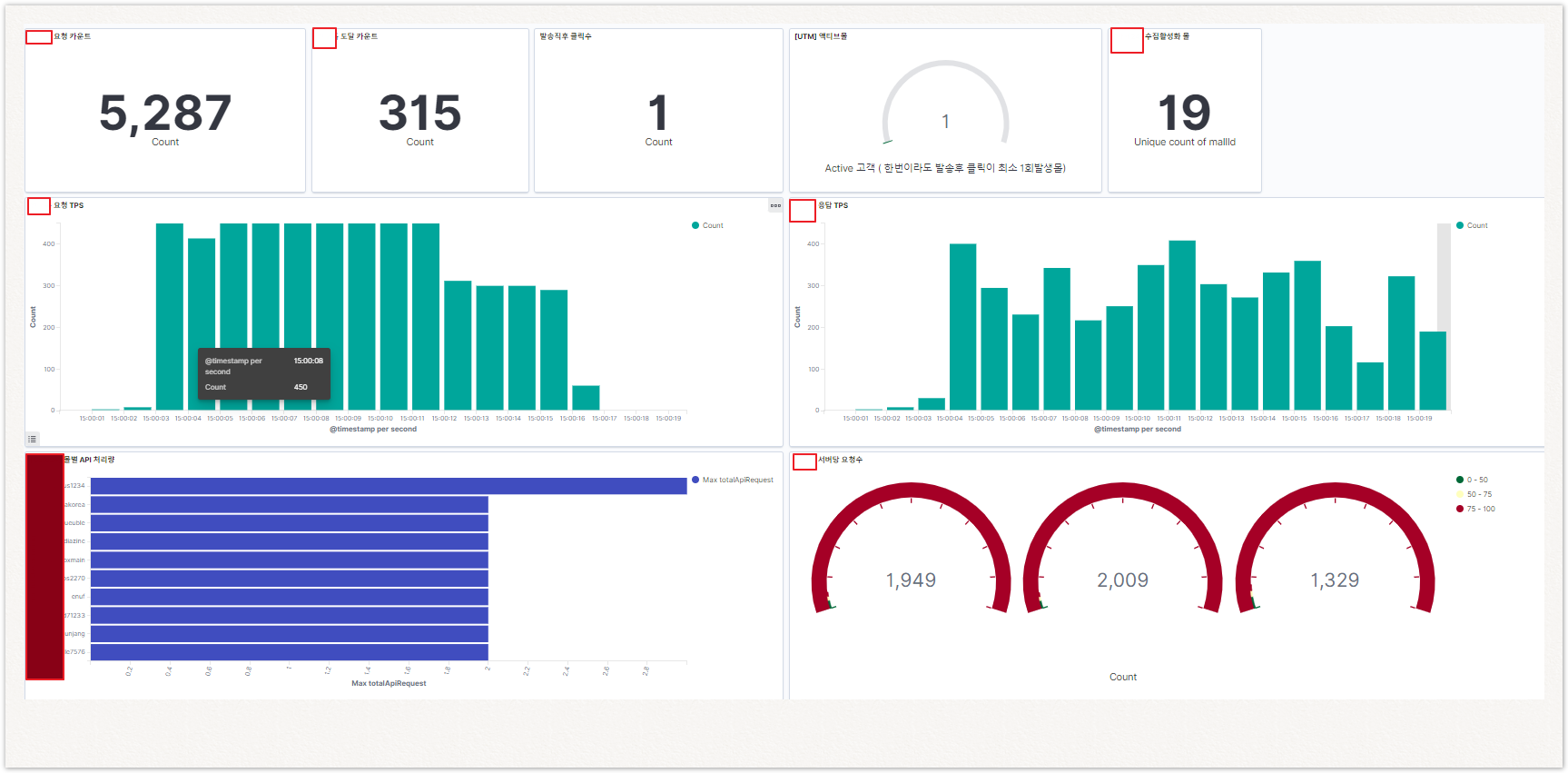
API 요청/응답 TPS를 포함~ 이 호출과 연관있는 지표를 함께 볼수있는 구성을 대시보드화해서 성능개선 지점을 찾을수 있습니다.
여기서는 로그데이터가 이용된 키바나 대시보드의 샘플이며~ 다양한 APM은 다양한 성능 매트릭스 오픈스택을 함께 이용 시스템모니터링이 하지 못하는 유용한 성능측정을 할수 있습니다.
위 그래프를 통해 요청한 TPS만큼 응답 TPS가 성능을 내지 못해, 응답속도가 점점 밀리고 있다란것을 파악할수가 있습니다.
현재 QA가 있게한 품질론의 아버지 데밍및 경영학에서도 개선하려면 측정가능해야한단것은 기본이며 중요합니다.
- 측정 가능한 모든 것을 측정하라, 그리고 측정이 힘든 모든 것을 측정가능하게 만들어라 - 데밍
- 측정할수 없는 것은 관리(개서)할수 없다. -피터 드러커
BackPressure In reactive Streams

최종 소비처리능력에 따라 생산량을 조절하는 아이디어는 사실 간단합니다.
이 아이디어는 불규칙으로 발생하는 데이터자체를 유체의 흐름으로 보고
실세계 존재하는 배압장치의 아이디어를 활용하는 것입니다. 이러한 장치가 잘작동하기 때문에 우리의 수도관이 터지질 않고 높은 수압으로 제공됩니다.
이것은 다음과 심플한 아이디어입니다.
- 최종 파이프에서 물이 방출되지 못하면 물이 역류하는 압력이 발생
- 압력이 발생하면 조절기를 압력만큼 닫아서 생산속도를 늦춤
여기까지가 이론이며, 이 이론을 바탕으로 실제 작동하는 코드를 유닛테스트를 통해 만들고 검증을 시도해보겠습니다.
JAVA AKKA 버전으로 작성되었으며~
Reactive Stream을 통핸 대용량처리에 관심 있는 개발자이거나
이러한 컨셉을 AKKA가 아닌 더 심플한 패턴으로 해결하는것에 관심이 있으면 계속 살펴보면 되겠습니다.
TPS측정기

이 실험을 위해 간단한 TPS측정기를 액터모델로 먼저 만들었습니다. 꼭 액터모델일 필요는 없으며 순수 OOP모델로도 작성시도할수 있습니다.
이 측정기는 단지 로우단위로 이벤트를 수신받아~ 초당처리량을 Log로 반복 알려주는 기능을 합니다.
- 측정이 필요한 이벤트 발생시 비동기적으로 TPS액터에게 로우단위로 메시지를 전송합니다.
- 호출코드의 성능 영향없이 작동되어야 하며 블락킹없이 작동합니다.
- TPS액터는 수신이벤트를 기반으로 초당 TPS를 알려준다.
- 이벤트가 없어도 TPS가 바로 0이되는것이 아닌~ 50% 감소를 한뒤 0으로 만든다.
TPS계산을 위해 별도의 연산이 필요없으며 단지 측정이 필요한 이벤트 발생시 Just Tell을 합니다.
for(int i=0;i<1200;i++){
tpsActor.tell("some Event", getRef());
}
sleep(1500); // 1초구간을 정확하게 확인하기위해 delay 1.5초
for(int i=0;i<600;i++){
tpsActor.tell("some Event", getRef());
}
sleep(1500);
for(int i=0;i<300;i++){
tpsActor.tell("some Event", getRef());
}
sleep(1500);
for(int i=0;i<500;i++){
tpsActor.tell("some Event", getRef());
}
TPS액터는 수신받은 측정이벤트를 기반으로, 초당 TPS를 알려줍니다.
[INFO ] [2023-12-10 11:47:13,575] [ClusterSystem-akka.actor.default-dispatcher-5] [TPS:1200.0] [INFO ] [2023-12-10 11:47:14,574] [ClusterSystem-akka.actor.default-dispatcher-10] [TPS:600.0] [INFO ] [2023-12-10 11:47:15,580] [ClusterSystem-akka.actor.default-dispatcher-10] [TPS:300.0] [INFO ] [2023-12-10 11:47:16,562] [ClusterSystem-akka.actor.default-dispatcher-10] [TPS:150.0] [INFO ] [2023-12-10 11:47:17,574] [ClusterSystem-akka.actor.default-dispatcher-9] [TPS:500.0] [INFO ] [2023-12-10 11:47:18,572] [ClusterSystem-akka.actor.default-dispatcher-9] [TPS:250.0] [INFO ] [2023-12-10 11:47:19,581] [ClusterSystem-akka.actor.default-dispatcher-6] [TPS:0.0] [INFO ] [2023-12-10 11:47:20,559] [ClusterSystem-akka.actor.default-dispatcher-9] [TPS:0.0] [INFO ] [2023-12-10 11:47:21,555] [ClusterSystem-akka.actor.default-dispatcher-9] [TPS:0.0]
측정기가 잘못되면 ~ 검증방식이 모두 잘못될수 있습니다. 위와같이 측정기가 우리 의도대로 작동하는지? 로그를 통해 알수 있습니다.
느린 소비자(SlowConsumerActor) 액터
느린소비자를 만들기위해 TPS측정기를 탑재하고, TPS가 400이상일때 tps만큼 지연하는 코드를 임의 생성하였습니다.
이 시나리오는 TPS의 측정구간이 정확하게 1초이내에 떨어지지 않는 네트워크의 불확실성도 포함하고 있습니다.
- TPS가 상승한뒤 바로뒤에~ 이벤트가 없어도 TPS가 바로 0이되는것이 아닌~ 0.5초이내에 50% 감소를 한뒤 그래도 없으면 0됩니다. ( 가속이 포함된 TPS 측정기 로직 )
- 이러한 컨셉은 N개를 처리하고 Xms 쉬게해서 서버사용률을 제한하는 LogStash의 배치단위 처리 튜닝에도 적용된 컨셉으로 성능제약용 TPS가 이벤트가 없다고 바로줄이는것이 아닌 가속을 적용해 조금씩 줄이는 아이디어입니다.
private int tpsLimit = 400;
if( result.tps > tpsLimit ){
sleepValue =(long)result.tps;
sleep(sleepValue);
log.info("World Slow - Total:{} Sleep:{}", totalProcessCount, sleepValue);
}
- API호출에서 일정하게 호출을 해도 최종 수신자는 네트워크의 경로에따라 불규칙한 TPS로 수신받습니다.
- 이것을 이해하는것이 가장 중요합니다.
- 지연이 없고 전송시간이 0에 가까울수록 요청 TPS와 수신 TPS는 일치합니다.
- 전송과정 여러 OSI계층및 다양한 ISP를 지나며 지연이 꼭 TPS이하로 수신됨만을 의미하지 않습니다.
- 생산은 일정하게 작동되며 전송과정중 특정 지점지연과정은 최종 수신자에게 오히려 한꺼번에 도달될수 있습니다.
- 이것을 이해하는것이 가장 중요합니다.
일정하게 요청 보내기 코드
int testCount = 50000;
int bufferSize = 100000;
int processCouuntPerSec = 400;
final ActorRef throttler =
Source.actorRef(bufferSize, OverflowStrategy.dropNew())
.throttle(processCouuntPerSec, FiniteDuration.create(1, TimeUnit.SECONDS),
processCouuntPerSec, ThrottleMode.shaping())
.to(Sink.actorRef(slowConsumerActor, akka.NotUsed.getInstance()))
.run(materializer);
느린 소비자에게 일정한 TPS(400)로 요청을 보내는 코드입니다. Block없이 AkkaStream의 조절기를 이용해 일정한 량을 방출합니다.
- testCount : 동시에 요청되는 수
- bufferSize : 최대 버퍼수를 지정합니다. 메모리 보호를 위해 이 수에따라 이벤트 드롭전략을 채택할수 있습니다.
- processCouuntPerSec : 버퍼를 지정된 TPS만큼 흘려보냅니다.
고정 TPS 400일때
[INFO ] [2023-12-10 14:18:58,052] [ClusterSystem-akka.actor.default-dispatcher-7] [First Tick] [INFO ] [2023-12-10 14:18:59,091] [ClusterSystem-akka.actor.default-dispatcher-7] [TPS:928.0] [INFO ] [2023-12-10 14:19:00,021] [ClusterSystem-akka.actor.default-dispatcher-8] [World Slow - Total:928 Sleep:928] [INFO ] [2023-12-10 14:19:00,077] [ClusterSystem-akka.actor.default-dispatcher-8] [TPS:2.0] [INFO ] [2023-12-10 14:19:00,486] [ClusterSystem-akka.actor.default-dispatcher-7] [World Slow - Total:929 Sleep:464] [INFO ] [2023-12-10 14:19:01,073] [ClusterSystem-akka.actor.default-dispatcher-7] [TPS:800.0] [INFO ] [2023-12-10 14:19:01,879] [ClusterSystem-akka.actor.default-dispatcher-7] [World Slow - Total:1730 Sleep:800] [INFO ] [2023-12-10 14:19:02,081] [ClusterSystem-akka.actor.default-dispatcher-4] [TPS:403.0] [INFO ] [2023-12-10 14:19:02,501] [ClusterSystem-akka.actor.default-dispatcher-8] [World Slow - Total:2133 Sleep:403] [INFO ] [2023-12-10 14:19:02,904] [ClusterSystem-akka.actor.default-dispatcher-8] [World Slow - Total:2134 Sleep:403] [INFO ] [2023-12-10 14:19:03,059] [ClusterSystem-akka.actor.default-dispatcher-9] [TPS:391.0] [INFO ] [2023-12-10 14:19:04,052] [ClusterSystem-akka.actor.default-dispatcher-5] [TPS:397.0] [INFO ] [2023-12-10 14:19:05,078] [ClusterSystem-akka.actor.default-dispatcher-9] [TPS:404.0] [INFO ] [2023-12-10 14:19:05,482] [ClusterSystem-akka.actor.default-dispatcher-9] [World Slow - Total:3325 Sleep:404] [INFO ] [2023-12-10 14:19:05,888] [ClusterSystem-akka.actor.default-dispatcher-9] [World Slow - Total:3326 Sleep:404] [INFO ] [2023-12-10 14:19:06,089] [ClusterSystem-akka.actor.default-dispatcher-7] [TPS:404.0]
서버는 400TPS가 넘을때 서버성능 이슈가 발생하며~ 400TPS로만 보내어도 아래와같은 처리량의 불규칙 현상이 발생합니다.
- 400 / 800 / 2 등 불규칙하게 작동되어 응답이 밀림
- Hello를 보내는경우 World로 응답하는 로그이며~ 제약에의한 지연발생시 Sleep:지연시간 로그가 발생합니다.
- 이 지연 응답이 15초이상 증가하면 ApiTimeOut을 유발할수가 있습니다.
이러한 현상이 발생하는 요인으로는 우리가 아무리 TPS를 일정하게 패킷을 통해 요청을 해도 최종 수신자에게는
측정방법에 따라 2배가 될 가능성이 있습니다.
다음은 초당 동시 요청이 아무리 일정하더라도 처리하는 과정과 처리하는 방버에 따라 최종 수신처는 2배의 데이터가 유입될수 있습니다.
네트워크 지연: 네트워크에 지연이 발생하면, 요청들이 서버에 도달하는 데 시간이 걸릴 수 있습니다. 이 지연이 해소되면, 서버는 밀린 요청들을 빠르게 처리하게 되고, 이로 인해 짧은 시간 동안 TPS가 상승합니다.
서버 처리 지연: 서버 자체에서 처리 지연이 발생할 수 있습니다. 예를 들어, 서버가 일시적으로 과부하 상태에 빠지거나, 유지보수 등으로 일시적으로 요청 처리를 중단한 후 재개했을 때, 밀린 요청들을 빠르게 처리하여 TPS가 일시적으로 증가합니다.
버퍼링과 배치 처리: 일부 시스템은 요청을 버퍼링 한 후, 배치로 처리하는 방식을 사용합니다. 이 경우, 버퍼에 쌓인 요청들이 배치로 처리될 때, 짧은 시간 동안 높은 TPS를 경험할 수 있습니다.
네트워크 장비의 처리: 네트워크 장비나 프록시 서버에서 요청을 일시적으로 보류한 후, 한꺼번에 전달하는 경우도 있을 수 있으며, 이는 마찬가지로 수신자 측에서 TPS의 증가로 이어질 수 있습니다.
다음 그래프는 최대 고정 TPS를 아슬하게 사용하는도중 네트워크 지연이 발생한다고하면 2배이상 급격한
TPS증가를 유발할수 있습니다. 초당 처리량의 수신측과 오차는 지연과 별도로 다양한 요소로 발생할수 있습니다.
이것은 요청받은 서버및 응답을 받아 처리하는 지점에서도 처리량이 급증해~ 문제의 지점이 모두 될수 있습니다.
이 그래프를 잘못해석해서 80만큼 응답하였으니, TPS가 80으로 오해하면 안되며
처음 요청의 지연이 생겨서 첫 요청의 응답시간이 오래걸렸다라고 이해해야합니다.
이러한 증상이 지속될때~ TimeOut에 쉽게 도달하여 데이터 유실의 가능성이 발생합니다.
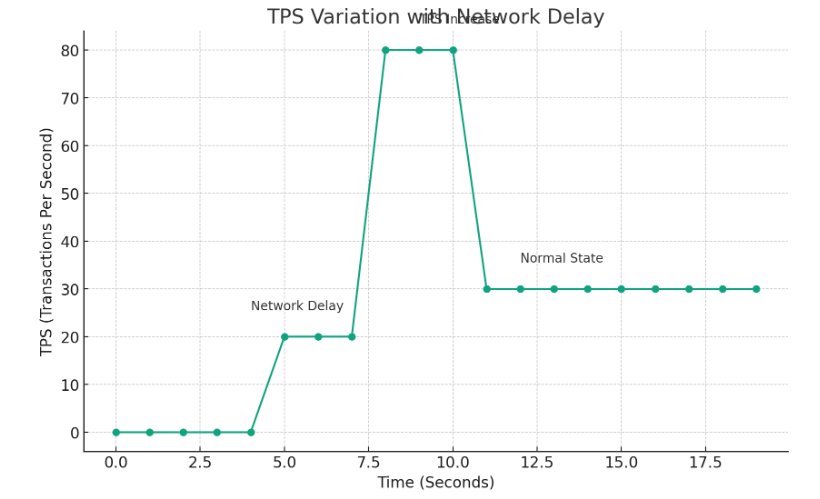
위 다이어그램은 네트워크 지연으로 인해 TPS가 어떻게 증가할 수 있는지 보여줍니다. 시간 경과에 따른 TPS의 변화를 나타내고 있습니다:
- 네트워크 지연 발생 구간 (5-8초): 이 구간에서는 네트워크 지연이 발생하여 TPS가 낮습니다.
- TPS 증가 구간 (8-11초): 지연된 요청들이 처리되면서 TPS가 급격히 증가합니다.
- 정상 상태 복귀 구간 (11초 이후): 이 구간에서는 시스템이 정상 상태로 돌아와 TPS가 안정화됩니다.
이 다이어그램은 네트워크 지연과 같은 외부 요인이 시스템의 성능 지표에 미치는 영향을 시각적으로 잘 보여줍니다. 이러한 지표의 변화를 이해하는 것은 시스템의 성능을 평가하고 관리하는 데 중요한 부분입니다.
위 그래프는 GPT를 통해 상황을 설명하고 지연에따른 응답 TPS가 어떻게 증가할수 있는가? 이며 운영모니터링을 탑재하고 응답시간이 느린구간을 아래와같이 실제 이벤트기반 측정을 하였습니다.
응답동시성이 좋다고 응답이 빠른것이 아닌 응답지연을 유발하게 되며 GPT의 이론은 측정기반으로 일어날수 있는 가능성을 확인하였습니다.
여기서 응답속도를 안정적으로 할수 있는방법은 요청 TPS를 낮추는것입니다.
고정 TPS 200일때
[INFO ] [2023-12-10 14:38:55,256] [ClusterSystem-akka.actor.default-dispatcher-9] [TPS:198.0] [INFO ] [2023-12-10 14:38:56,282] [ClusterSystem-akka.actor.default-dispatcher-6] [TPS:209.0] [INFO ] [2023-12-10 14:38:57,261] [ClusterSystem-akka.actor.default-dispatcher-6] [TPS:195.0] [INFO ] [2023-12-10 14:38:58,258] [ClusterSystem-akka.actor.default-dispatcher-8] [TPS:200.0] [INFO ] [2023-12-10 14:38:59,284] [ClusterSystem-akka.actor.default-dispatcher-9] [TPS:202.0] [INFO ] [2023-12-10 14:39:00,281] [ClusterSystem-akka.actor.default-dispatcher-6] [TPS:202.0] [INFO ] [2023-12-10 14:39:01,260] [ClusterSystem-akka.actor.default-dispatcher-9] [TPS:193.0] [INFO ] [2023-12-10 14:39:02,264] [ClusterSystem-akka.actor.default-dispatcher-8] [TPS:206.0] [INFO ] [2023-12-10 14:39:03,274] [ClusterSystem-akka.actor.default-dispatcher-4] [TPS:202.0] [INFO ] [2023-12-10 14:39:04,278] [ClusterSystem-akka.actor.default-dispatcher-6] [TPS:196.0] [INFO ] [2023-12-10 14:39:05,275] [ClusterSystem-akka.actor.default-dispatcher-7] [TPS:199.0] [INFO ] [2023-12-10 14:39:06,274] [ClusterSystem-akka.actor.default-dispatcher-7] [TPS:200.0] [INFO ] [2023-12-10 14:39:07,281] [ClusterSystem-akka.actor.default-dispatcher-7] [TPS:204.0]
느린소비자에서 셋팅된 제약인 400TPS의 반값을 이용하면 위와같이 생산과 소비 속도가 안정적으로 200으로 맞추어집니다.
반토막이 난값을 사용한경우 전체처리 성능을 제대로 활용을 못하는 상황으로 오로지 안정적인 호출만 고려하는 전략입니다. 하지만 이렇게 요청처리량을 중간값 이하로 사용하는것은 우리가 원하는 최상의 결과는 아닙니다.
모니터링을 통한 TPS결정
위와같이 모니터링을 통해 생산/소비의 안정적인 TPS속도를 찾아내 규칙적으로 작동된다고 하면 일반적으로 가장 심플하고 단순하게 이용할수 있습니다.
우리의 요청이 1시간이상이나 쉬지 않고 요청하는 경우는 없기때문에~ 발생할수 있는 최대 요청량 대비 성능적으로 안정적인 TPS구간을
모니터링을 통해 200~400 사이에서 찾아나갈수도 있습니다.
int testCount = 50000;
int bufferSize = 100000;
int processCouuntPerSec = 400; // 최적의 TSP 찾기
final ActorRef throttler =
Source.actorRef(bufferSize, OverflowStrategy.dropNew())
.throttle(processCouuntPerSec, FiniteDuration.create(1, TimeUnit.SECONDS),
processCouuntPerSec, ThrottleMode.shaping())
.to(Sink.actorRef(slowConsumerActor, akka.NotUsed.getInstance()))
.run(materializer);
외부 배치 폴링 ( 스케줄러,또는 Kafka폴링)에 의해 규칙적으로 TPS만큼 작동될수도 있지만 이 코드는 외부폴링이 불규칙적으로 작동을 해도 큐에 우선담은후 안정적 TPS로 흘려보내기때문에
생산이 불규칙적 일때도 이용할수 있습니다.
이 방식의 단점은 지속적 운영 모니터링을 통해 최적 TPS를 찾아내어야한다란것입니다. 최적 TPS를 찾아내었다고 해도~ API응답은 서버응답/네트워크상황등 다양한 변수가 있습니다.
효율적인 고정값을 찾아서 항상 사용하는것이아닌~ 동시호출 수준을 어느정도 유지하고 안정적 흐름을 만들어내는 BackPressure 기능 구현에 대해 살펴보겠습니다.
최고성능을 내기보다는 응답성능이 느려졌을때 호출량을 동적으로 줄일수 있는 조절기능을 가지고 있습니다.
이렇게 함으로 총량의 처리를 동일한 시간에 안정적으로 더 많이하고 여기서 안정적 호출은~ ApiTimeOut의 유발을 최소화할수 있는것입니다.
우리가 할당받은 자원에서 호출대상 서버가 느려졌다라고 판단하면 조금 쉬는시간을 줌으로 안정화를 할수 있습니다.
BackPressure

여기서 생산과 소비는 초콜릿을 생산한다란 의미가 아니며 다음과 같이 해석하며 항상 상대적인 관점 으로 왼쪽이 생산 오른쪽이 소비이다.
초콜릿 원액을 공급해줌 → 초콜릿을 원형으로 만들어줌 → 초콜릿을 포장함
최종 이벤트를 소비하는 포장하는 쪽의 속도가 느리며 생산과 소비의 속도를 맞추는 장치가 없으면 초콜릿은 계속 만들어지며 초콜릿이 라인에 쌓여 생산라인을 결국 고장나게 할수 있으며
BackPresure의 아이디어는~ 생산라인(버퍼)가 가득차가는 경우 초콜릿 생산속도를 늦춤으로 전체 처리량을 안정적으로 처리하는데 목적이 있습니다.
느린소비자 - API호출
private static String callApi(Integer param) {
// API 호출을 시뮬레이션
try {
Thread.sleep(100); // API 응답 시간을 시뮬레이션하기 위한 지연
tpsActor.tell("CompletedEvent", ActorRef.noSender());
} catch (InterruptedException e) {
e.printStackTrace();
}
return "Response for " + param;
}
느린 API를 설명하기위해, 서버가 단일스레드에서 항상 100(0.1초) 의 지연시간이 있는경우라는 시나리오를 작성했습니다.
- 우리는 이 숨겨진 제한값을 대부분 공유받기 어렵습니다.
- 반대로 우리는 우리가 만든기능이 일정한 TPS로 작동할것이다라고 보장하기 역시 어렵습니다.
기능이 밀리지 않고 작동하는 예상 TPS는 10입니다. 이 값을 어떻게 자동으로 찾는지 알아보겠습니다.
AkkaStream의 BackPressure
@Test
@DisplayName("BackPressureTest")
public void BackPressureTest() {
new TestKit(actorSystem) {
{
final Materializer materializer = ActorMaterializer.create(actorSystem);
final TestKit probe = new TestKit(actorSystem);
// Source 생성
Source<Integer, NotUsed> source = Source.range(1, 1000);
// Flow 정의 (API 호출을 시뮬레이션하는 로직)
Flow<Integer, String, NotUsed> flow = Flow.fromFunction(BackPressureTest::callApi);
// Buffer 설정 및 OverflowStrategy.backpressure 적용
int bufferSize = 100;
Flow<Integer, Integer, NotUsed> backpressureFlow = Flow.<Integer>create()
.buffer(bufferSize, OverflowStrategy.backpressure());
// Sink 정의
Sink<String, CompletionStage<Done>> sink = Sink.foreach(System.out::println);
// RunnableGraph 생성 및 실행
source.via(backpressureFlow).via(flow).to(sink).run(materializer);
within(
Duration.ofSeconds(15),
() -> {
// Will wait for the rest of the 10 seconds
expectNoMessage(Duration.ofSeconds(10));
return null;
});
}
};
}
위 코드에서는 BackPressure 전략만 정의되어 있으며 TPS정의는 없습니다. 전략은 단순합니다. 생산보다 소비가 점점 늦어지면 결국 큐에 처리 대기하는 데이터가 쌓이게되며
이 수가 넘어서면 생산의 속도를 늦추는것입니다.
Response for 13 Response for 14 Response for 15 Response for 16 Response for 17 Response for 18 Response for 19 Response for 20 Response for 21 [INFO ] [2023-12-10 15:02:58,844] [ClusterSystem-akka.actor.default-dispatcher-6] [TPS:9.0] Response for 22 Response for 23 Response for 24 Response for 25 Response for 26 Response for 27 Response for 28 Response for 29 Response for 30 Response for 31 [INFO ] [2023-12-10 15:02:59,845] [ClusterSystem-akka.actor.default-dispatcher-4] [TPS:10.0]
동시성 병렬처리 고려 BackPresure
샘플은 Flow에서 API가 순차적 작동이여서 동시성이 1이며 단일 장비에서 최대 동시 호출량을 찾으려면
RestClient의 커넥션풀과 장비에서 동시요청 능력만큼 시도될수 있습니다.
Akka의 Stream은 Java 9 StreamAPI및 닷넷의 Linq(+TPL)과 유사하지만 조금더 유연하게 각 요소를 조립할수 있는 장점이 있으며 코드 그자체를 그래프로 표현할수 있습니다.

- Source → Flow → Sink
- 실행 소스가 있으며, 병렬처리 Flow로 진행되며 완료가 되면 Sink로 아웃이됩니다.
- BackPresure는 Sink의 속도에 따라 처리속도를 알수 있으며 버퍼수를 관리하면서 생산산도를 자동 제어합니다.
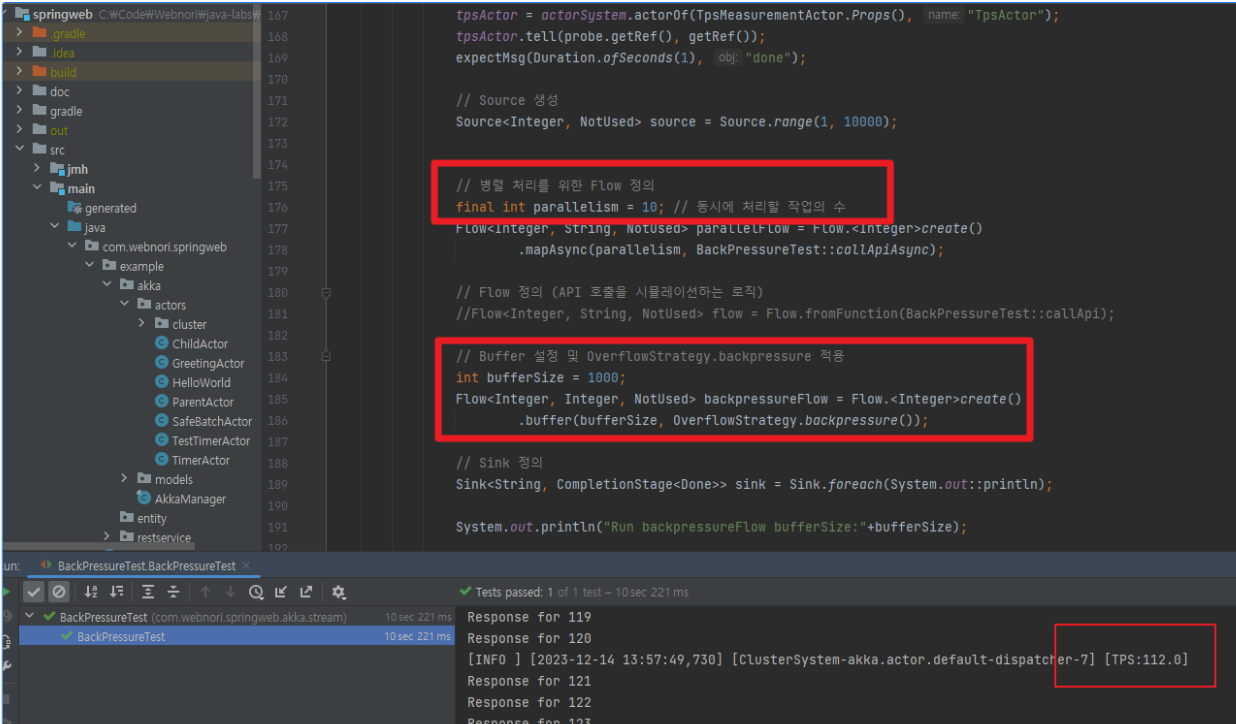
여기서 더 유용한 코드가 되려면 Flow 단계에서 병렬처리가 되어야하며 다음과 같은 코드로 Flow를 병렬처리로 변경하였습니다.
// Source 생성
Source<Integer, NotUsed> source = Source.range(1, 10000);
// 병렬 처리를 위한 Flow 정의
final int parallelism = 10; // 동시에 처리할 작업의 수
Flow<Integer, String, NotUsed> parallelFlow = Flow.<Integer>create()
.mapAsync(parallelism, BackPressureTest::callApiAsync);
// Flow 정의 (API 호출을 시뮬레이션하는 로직)
//Flow<Integer, String, NotUsed> flow = Flow.fromFunction(BackPressureTest::callApi);
// Buffer 설정 및 OverflowStrategy.backpressure 적용
int bufferSize = 1000;
Flow<Integer, Integer, NotUsed> backpressureFlow = Flow.<Integer>create()
.buffer(bufferSize, OverflowStrategy.backpressure());
// Sink 정의
Sink<String, CompletionStage<Done>> sink = Sink.foreach(System.out::println);
System.out.println("Run backpressureFlow bufferSize:"+bufferSize);
// RunnableGraph 생성 및 실행
source.via(backpressureFlow).via(parallelFlow).to(sink).run(materializer);
private static CompletionStage<String> callApiAsync(Integer param) {
// CompletableFuture를 사용하여 비동기 처리 구현
return CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(100); // API 응답 시간을 시뮬레이션하기 위한 지연
tpsActor.tell("CompletedEvent", ActorRef.noSender());
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
return "Response for " + param;
});
이제 Buffer설정및 동시호출 가능(parallelism) 옵션을 조절하여~ 안정적인 호출흐름을 만들어내는 BackPresure를 이용할수 있습니다.
고정된 TPS를 반복 요청하는것보다. 더 안정적인 처리를 할수 있으며 응답이 느린경우 버퍼가 증가하기때문에 이 개수가 압력이여서 생산을 늦추게됩니다.
BackPresure의 아이디어는 이와 같이 간단하며~ 속도를 늦추어야하는 압력값이 커스텀한 수치라고 이 수치를 설계에 반영할수도 있습니다.
Backpresure 최종완성된 유닛테스트기
- 성능제약이 걸린 함수를 유닛테스트를 통해 동시성 Backpresure를 테스트할수 있으며 측정할수 있습니다.
- Backpresure에서 중요 튜닝요소는 TPS가 아닌~ 동시처리능력(병렬) 지정과 함께~ 응답이 느릴때 버퍼에 쌓이는 점을 이용 버퍼값이 증가하면 속도를 늦추는 단순한 아이디어입니다.
- 이것은 일반적으로 지정된 성능값으로 작동하지만~ 응답이 느려지면 소비자에게 쉴 시간을 줘서 다시 최고 성능으로 복원하는것이 컨셉입니다.
여기서 설명된 코드는 전체코드로도 살펴볼수 있습니다.
전체코드
여기서 설명한 전체 코드는 GitHub을 통해서 알수 있으며 로컬에서 유닛테스트 기반 작동됩니다.
다음 최종생성한 코드를 GPT가 분석한 내용입니다.
이 Java 코드는 Akka 프레임워크를 사용한 단위 테스트입니다. 주요 기능과 목적을 요약하면 다음과 같습니다:
테스트 설계:
BackPressureTest라는 이름의 유닛 테스트입니다. 이 테스트는 Akka의TestKit클래스를 사용하여 작성되었습니다.TestKit은 Akka 액터 시스템을 테스트하기 위한 유틸리티입니다.액터 시스템 및 자료 흐름 설정:
Materializer와TestKit인스턴스를 생성합니다. 이들은 스트림 처리와 테스트 실행에 사용됩니다.TpsMeasurementActor액터를 생성하고, 이 액터에게 메시지를 보냅니다. 이는 아마도 스트림 처리의 성능 측정을 위한 것으로 보입니다.
Akka Streams 사용:
- 소스 생성:
Source.range(1, 10000)을 사용하여 1부터 10,000까지의 숫자를 생성합니다. - Flow 정의: 비동기 API 호출을 시뮬레이션하기 위해
mapAsync와buffer를 사용한Flow를 정의합니다.mapAsync를 사용하여 병렬 처리를 구현하고,buffer를 통해 백프레셔(Back Pressure) 전략을 적용합니다. - 싱크(Sink) 정의: 결과를 출력하기 위한
Sink를 정의합니다.
- 소스 생성:
백프레셔 전략: 스트림 처리 중에 백프레셔를 관리하기 위해
bufferSize를 설정하고,OverflowStrategy.backpressure()를 사용합니다. 이는 시스템이 과부하 상태가 되지 않도록 하기 위함입니다.RunnableGraph 실행: 정의된 소스, 플로우, 싱크를 연결하여 스트림 처리 파이프라인을 구축하고 실행합니다.
비동기 API 호출 시뮬레이션:
callApiAsync메서드는CompletableFuture를 사용하여 비동기적으로 API 호출을 시뮬레이션합니다. 각 호출은 100ms의 지연 후에 완료되며,tpsActor에 완료 이벤트를 보냅니다.테스트 검증:
within메서드를 사용하여 15초 동안 아무 메시지도 수신되지 않는 것을 확인함으로써, 스트림 처리가 예상대로 작동하는지 검증합니다.
이 테스트는 Akka Streams의 백프레셔 메커니즘과 비동기 처리 기능을 검증하는 데 중점을 두고 있습니다.
안정적 TPS를 찾는것도 중요하지면~ Backpresure의 아이디어를 함께 이용하는경우 생산과 소비의 성능차이가 발생할때 시스템이 중단되지 않고 안정적으로 작동할수 있습니다.
BackPresure를 이용하여 생산과 소비 , 발행과 구독에서 발생하는 성능차이를 동적으로 조절할수 있는 간단한 아이디어는 다양한곳에서 쉽게 찾을수 있으며 이용할수 있습니다.
AKKA가 아니여도 됩니다.
JAVA7인 시절 이러한 스펙이 없었지만, AKKA의 영향을 받아 기본언어스펙에서도 지원하며 AKKA가 아니여도 됩니다. Backpresure를 활용할수 있는 대표적인 개발방법을 몇가지 알아보고 마무리합니다.
Java (Reactive Streams 라이브러리 사용)
- Java에서는 Reactive Streams API를 이용해 BackPressure를 구현할 수 있습니다. 예를 들어,
Flow인터페이스와Publisher,Subscriber클래스를 사용하여 데이터 스트림을 제어할 수 있습니다.
- Java에서는 Reactive Streams API를 이용해 BackPressure를 구현할 수 있습니다. 예를 들어,
JavaScript (RxJS 라이브러리 사용)
- JavaScript에서는 RxJS 라이브러리를 활용하여 리액티브 프로그래밍과 BackPressure를 구현할 수 있습니다. RxJS의
Observable과BackPressure전략을 사용하여 이벤트 스트림을 관리합니다.
- JavaScript에서는 RxJS 라이브러리를 활용하여 리액티브 프로그래밍과 BackPressure를 구현할 수 있습니다. RxJS의
Python (RxPy 라이브러리 사용)
- Python에서는 RxPy(ReactiveX for Python)를 사용하여 리액티브 프로그래밍과 BackPressure를 구현할 수 있습니다. 이 라이브러리는 스트림 데이터의 비동기 처리와 이벤트 기반 프로그래밍을 지원합니다.
C# (System.Reactive 라이브러리 사용)
- C#에서는 System.Reactive 라이브러리를 통해 리액티브 프로그래밍을 구현할 수 있으며, 이를 통해 BackPressure 메커니즘을 적용할 수 있습니다.
IObservable<T>과IObserver<T>인터페이스를 중심으로 데이터 스트림을 관리합니다.
- C#에서는 System.Reactive 라이브러리를 통해 리액티브 프로그래밍을 구현할 수 있으며, 이를 통해 BackPressure 메커니즘을 적용할 수 있습니다.
Scala (Akka Streams 라이브러리 사용)
- Scala에서는 Akka Streams 라이브러리를 사용하여 BackPressure를 구현할 수 있습니다. Akka Streams는 Akka 액터 모델을 기반으로 비동기 스트림 처리를 쉽게 구현할 수 있게 해줍니다.
각 언어에 맞는 라이브러리를 사용하여 BackPressure를 구현하는 것은 데이터 스트림의 흐름을 효율적으로 관리하고 시스템의 안정성을 유지하는 데 도움이 됩니다. 이러한 구현은 각 언어의 특성과 라이브러리의 API에 익숙해지는 것이 중요합니다.
DB/API응답을 기다려야하는 블락킹코드가 포함된 코드에서 병렬처리를 활용하여 TPS보장하기및 AKKA 소개편
Add Comment