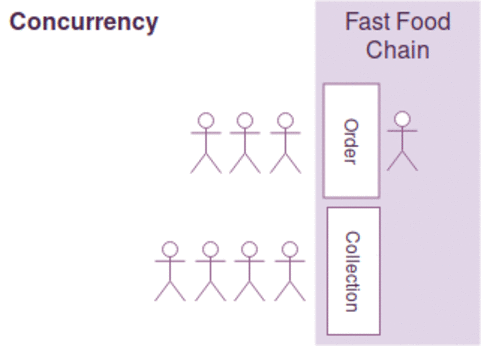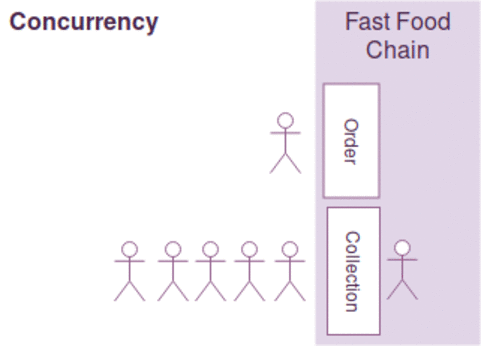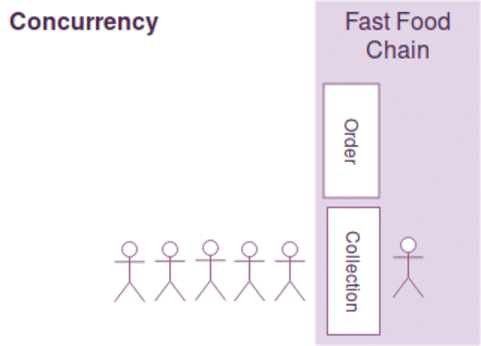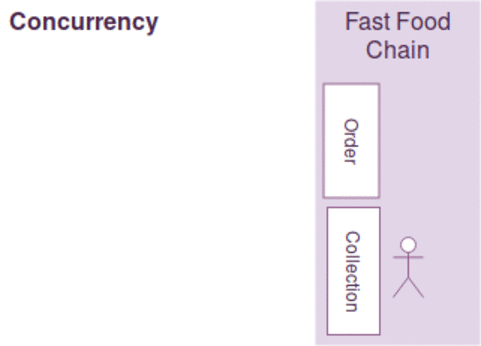
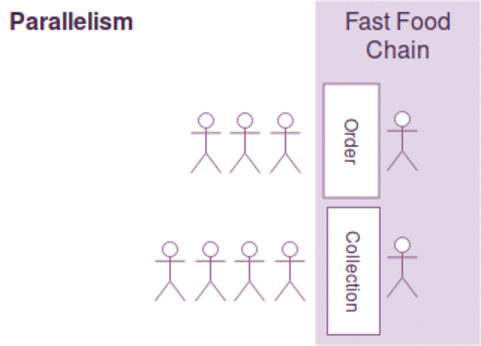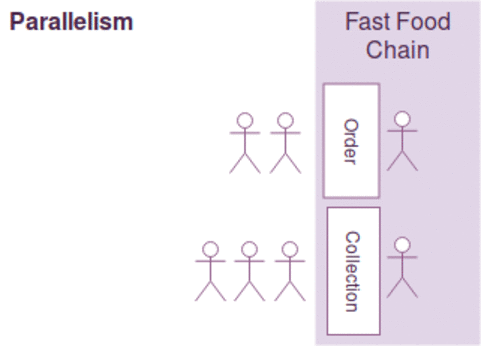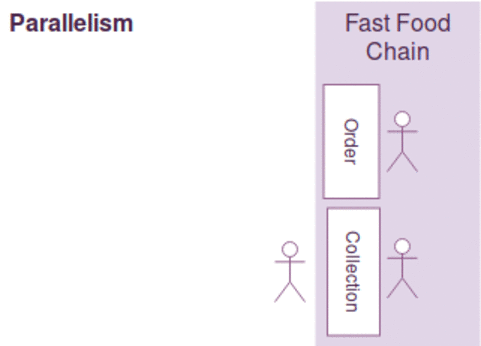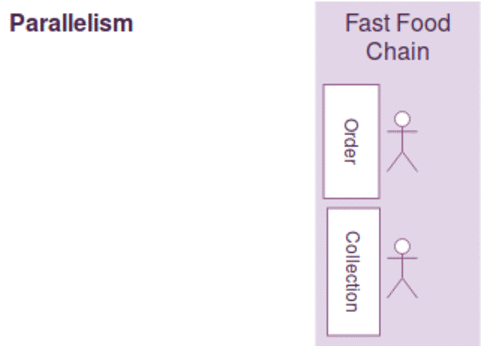
동시성과 병렬성은 약간의 차이가 있지만, 다음과 같이 간략하게 설명될수 있습니다.
- 동시성 : 한사람이 커피주문 받고 만들기를 동시에한다. ( 커피머신을 이용하면서도 주문을 받음)
- 병렬성 : 커피주문을 받는사람과 만드는 사람이 각각 따로 있다.
- 순차성 : 한사람이 커피주문을 받고 커피를 만들지만~ 커피가 완성될때까지 다음손님 주문을 받지 못한다.
동시처리및 병렬처리방식을 자바/닷넷에서 대표되는 방식을 각각 알아보고 마지막으로 비동기 이벤트기반에 유용한 Stream 처리방식도 알아보자~
비동기 처리 PART
자바(Java)와 닷넷(.NET)에서 비동기 처리를 구현하는 방법은 다음과 같습니다.
자바(Java)에서의 비동기 처리
자바에서 비동기 처리를 구현하는 주요 방법은 다음과 같습니다:
Future와 Callable 인터페이스 사용:
Callable인터페이스를 구현하여 비동기로 실행할 태스크를 정의합니다.ExecutorService를 사용하여Callable객체를 제출(submit)하고, 반환된Future객체를 통해 결과를 얻거나 태스크의 상태를 확인할 수 있습니다.
CompletableFuture 사용:
- Java 8 이후,
CompletableFuture는 더 유연하고 강력한 비동기 프로그래밍을 지원합니다. - 비동기 연산의 결과를 나타내며, 결과가 준비되면 콜백을 통해 처리할 수 있습니다.
- 연산을 파이프라인화하고, 여러 비동기 연산을 조합하고, 에러를 처리하는 등의 기능을 제공합니다.
- Java 8 이후,
Reactive Programming (예: Reactor, RxJava):
- 반응형 프로그래밍은 데이터 플로우와 전파 변경에 중점을 둔 비동기 프로그래밍 패러다임입니다.
- RxJava나 Project Reactor 같은 라이브러리를 사용하여 이벤트 기반의 비동기 데이터 스트림을 처리할 수 있습니다.
닷넷(.NET)에서의 비동기 처리
닷넷에서 비동기 처리를 구현하는 주요 방법은 다음과 같습니다:
async와 await 키워드 사용:
- C# 5.0부터 도입된
async와await키워드를 사용하여 간결하고 직관적인 비동기 코드를 작성할 수 있습니다. async메소드는Task나Task<T>를 반환하며,await를 사용하여 비동기적으로 실행되는 작업의 결과를 기다립니다.
- C# 5.0부터 도입된
Task Parallel Library (TPL):
- 병렬 처리와 비동기 프로그래밍을 위한
Task와Task<T>클래스를 제공합니다. - 복잡한 비동기 로직과 병렬 처리를 구현하는데 사용됩니다.
- 병렬 처리와 비동기 프로그래밍을 위한
Event-based Asynchronous Pattern (EAP):
- 이벤트 기반의 비동기 패턴으로, 비동기 작업을 시작하고 완료 시 이벤트를 통해 결과를 반환합니다.
- .NET Framework의 많은 구성 요소에서 사용되지만,
async와await의 도입으로 점차 사용이 줄어들고 있습니다.
I/O Completion Ports:
- 고성능 I/O 작업에 최적화된 저수준 비동기 패턴입니다.
- 주로 네트워크 작업이나 대용량 파일 처리에 사용됩니다.
각 플랫폼과 언어의 특성에 맞게 비동기 처리를 구현할 때, 해당 플랫폼의 최신 기능과 라이브러리를 활용하는 것이 중요합니다. Java와 .NET 모두 강력한 비동기 처리 기능을 제공하여 개발자가 효율적이고 성능이 우수한 애플리케이션을 구축할 수 있도록 지원합니다.
자바에서는 CompletableFuture 를 이용하고 닷넷에서는 Task Parallel Library을 이용하고 List에는 랜덤한 문자 100개가 있으며 이것을 동시에 2개씩 출력하는 코드를 각각 작성해죠
import java.util.List;
import java.util.ArrayList;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ExecutionException;
public class AsyncExample {
public static void main(String[] args) {
// 100개의 랜덤 문자를 생성하여 리스트에 저장
List<Character> charList = new ArrayList<>();
for (int i = 0; i < 100; i++) {
charList.add((char) ('A' + (int) (Math.random() * 26)));
}
// 리스트의 문자를 2개씩 비동기적으로 출력
List<CompletableFuture<Void>> futures = new ArrayList<>();
for (int i = 0; i < charList.size(); i += 2) {
char finalChar1 = charList.get(i);
char finalChar2 = (i + 1 < charList.size()) ? charList.get(i + 1) : ' ';
CompletableFuture<Void> future = CompletableFuture.runAsync(() -> {
System.out.println(finalChar1 + " " + finalChar2);
});
futures.add(future);
}
// 모든 작업이 완료될 때까지 기다림
CompletableFuture<Void> allDone = CompletableFuture.allOf(futures.toArray(new CompletableFuture[0]));
try {
allDone.get();
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
}
using System;
using System.Collections.Generic;
using System.Threading.Tasks;
class AsyncExample
{
static void Main()
{
// 100개의 랜덤 문자를 생성하여 리스트에 저장
List<char> charList = new List<char>();
Random random = new Random();
for (int i = 0; i < 100; i++)
{
charList.Add((char)('A' + random.Next(26)));
}
// 리스트의 문자를 2개씩 비동기적으로 출력
List<Task> tasks = new List<Task>();
for (int i = 0; i < charList.Count; i += 2)
{
char char1 = charList[i];
char char2 = (i + 1 < charList.Count) ? charList[i + 1] : ' ';
Task task = Task.Run(() =>
{
Console.WriteLine(char1 + " " + char2);
});
tasks.Add(task);
}
// 모든 작업이 완료될 때까지 기다림
Task.WhenAll(tasks).Wait();
}
}
병렬처리를 위한 스레드 파트
자바(Java)의 스레드풀
Executor Framework:
- Java의 Executor Framework는
java.util.concurrent패키지에 있습니다. - 주요 클래스와 인터페이스:
Executor: 기본적인 실행 인터페이스.Executors: 스레드풀을 쉽게 생성할 수 있는 팩토리 메서드를 제공.ExecutorService: Executor를 확장하여 라이프사이클 관리 및 작업 제출 기능을 제공.ScheduledExecutorService: 예정된 작업을 실행하기 위한 인터페이스.
- 종류:
- Fixed Thread Pool: 고정된 수의 스레드를 갖는 풀.
- Cached Thread Pool: 필요에 따라 스레드를 생성하고, 사용하지 않는 스레드는 회수.
- Single Thread Executor: 단일 스레드로 작업을 처리.
- Scheduled Thread Pool: 예약된 작업이나 반복적인 작업을 위한 스레드풀.
- Java의 Executor Framework는
ForkJoinPool:
- Java 7에서 도입된 병렬 처리를 위한 고급 스레드풀.
- 작업을 작은 부분으로 나누고, 완료 후 결과를 합치는 'divide and conquer' 방식 사용.
.NET의 스레드풀
ThreadPool 클래스:
- .NET의 System.Threading 네임스페이스에 위치.
- 자동으로 스레드 크기를 관리하고, 작업 큐에 작업을 배치.
- 기능:
- 스레드 생성 및 회수 관리.
- 작업 대기열에 작업을 추가하고 스레드에 할당.
ThreadPool.QueueUserWorkItem메서드를 통해 작업을 스레드풀에 추가.
Task Parallel Library (TPL):
- .NET 4.0부터 도입.
- 높은 수준의 병렬 처리와 비동기 프로그래밍을 위한 라이브러리.
Task및Task<TResult>클래스를 사용하여 병렬 작업을 쉽게 생성 및 관리.- TPL은 내부적으로 ThreadPool을 사용.
두 플랫폼 모두에서 스레드풀은 멀티스레드 프로그래밍을 단순화하고 효율적으로 관리할 수 있게 해주며, 스레드 생성 및 파괴에 따른 오버헤드를 줄여주는 중요한 역할을 합니다.
이 버전을 스레드모델을 이용해서 각각 작성해죠
백그라운드로 항상 작동해야하는 프로그래밍 모델인경우 스레드를 이용할수 있습니다.
public class ThreadExample {
public static void main(String[] args) {
// 100개의 랜덤 문자를 생성하여 리스트에 저장
List<Character> charList = new ArrayList<>();
for (int i = 0; i < 100; i++) {
charList.add((char) ('A' + (int) (Math.random() * 26)));
}
// 리스트의 문자를 2개씩 스레드를 사용해 출력
for (int i = 0; i < charList.size(); i += 2) {
char finalChar1 = charList.get(i);
char finalChar2 = (i + 1 < charList.size()) ? charList.get(i + 1) : ' ';
Thread thread = new Thread(() -> {
System.out.println(finalChar1 + " " + finalChar2);
});
thread.start();
}
}
}
using System;
using System.Collections.Generic;
using System.Threading;
class ThreadExample
{
static void Main()
{
// 100개의 랜덤 문자를 생성하여 리스트에 저장
List<char> charList = new List<char>();
Random random = new Random();
for (int i = 0; i < 100; i++)
{
charList.Add((char)('A' + random.Next(26)));
}
// 리스트의 문자를 2개씩 스레드를 사용해 출력
for (int i = 0; i < charList.Count; i += 2)
{
char char1 = charList[i];
char char2 = (i + 1 < charList.Count) ? charList[i + 1] : ' ';
Thread thread = new Thread(() =>
{
Console.WriteLine(char1 + " " + char2);
});
thread.Start();
}
}
}
스레드풀을 각각 이용해죠
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class ThreadPoolExample {
public static void main(String[] args) {
// 스레드풀 생성
ExecutorService executor = Executors.newFixedThreadPool(10); // 10개의 스레드를 가진 풀
// 100개의 랜덤 문자를 생성하여 리스트에 저장
List<Character> charList = new ArrayList<>();
for (int i = 0; i < 100; i++) {
charList.add((char) ('A' + (int) (Math.random() * 26)));
}
// 리스트의 문자를 2개씩 스레드풀을 사용해 출력
for (int i = 0; i < charList.size(); i += 2) {
char finalChar1 = charList.get(i);
char finalChar2 = (i + 1 < charList.size()) ? charList.get(i + 1) : ' ';
executor.execute(() -> {
System.out.println(finalChar1 + " " + finalChar2);
});
}
// 스레드풀 종료
executor.shutdown();
}
}
using System;
using System.Collections.Generic;
using System.Threading;
class ThreadPoolExample
{
static void Main()
{
// 100개의 랜덤 문자를 생성하여 리스트에 저장
List<char> charList = new List<char>();
Random random = new Random();
for (int i = 0; i < 100; i++)
{
charList.Add((char)('A' + random.Next(26)));
}
// 리스트의 문자를 2개씩 스레드풀을 사용해 출력
for (int i = 0; i < charList.Count; i += 2)
{
char char1 = charList[i];
char char2 = (i + 1 < charList.Count) ? charList[i + 1] : ' ';
ThreadPool.QueueUserWorkItem(_ =>
{
Console.WriteLine(char1 + " " + char2);
});
}
}
}
이 코드들은 스레드풀을 사용하여 랜덤하게 생성된 문자 리스트를 2개씩 동시에 처리하고 출력합니다. 스레드풀을 사용하면 스레드 생성과 제거에 대한 오버헤드를 줄이면서 효율적으로 자원을 관리할 수 있습니다.
java stream api 는 reactive streams 을 준수하는가?
Java Stream API와 Reactive Streams는 서로 다른 목적과 설계 철학을 가진 두 가지 기술입니다.
Java Stream API: Java 8에서 도입된 Java Stream API는 컬렉션 프레임워크와 밀접하게 연결되어 있습니다. 이 API는 람다 표현식과 함께 사용되어 데이터 컬렉션을 함수형 스타일로 처리할 수 있도록 설계되었습니다. Stream API는 주로 컬렉션의 데이터를 필터링, 변환, 정렬 등의 작업을 위해 동기적이고 pull 방식으로 동작합니다.
Reactive Streams: Reactive Streams는 비동기 스트림 처리를 위한 표준입니다. 이는 데이터 스트림이 불특정한 소스(예: 사용자 이벤트, 외부 서비스 호출 등)에서 오는 경우에 사용되며, back-pressure를 지원하여 데이터 흐름을 제어할 수 있습니다. Reactive Streams는 Java 9의
java.util.concurrent.FlowAPI에 포함되어 있으며, 이는 자바의 표준 비동기 스트림 API로 간주됩니다.
Java Stream API는 Reactive Streams 표준을 직접적으로 준수하지는 않습니다. 그러나, Java 9 이후에는 java.util.concurrent.Flow API를 통해 Reactive Streams와 유사한 기능을 제공하게 되었습니다. 이는 비동기 처리와 back-pressure를 지원하는 반면, Java Stream API는 주로 컬렉션에 대한 동기적 처리에 중점을 둡니다.
BackPresure 가 데이터 스트림을 다룰때 중요한 이유~
스트림(stream)에서의 백프레셔(back-pressure)는 데이터 처리 시스템에서 매우 중요한 개념입니다. 백프레셔는 스트림 처리 과정에서 생산자(producer)와 소비자(consumer) 간의 데이터 처리 속도 차이를 관리하는 메커니즘을 말합니다. 이 개념을 이해하기 위해 생산자와 소비자의 역할을 살펴보겠습니다:
생산자 (Producer): 데이터를 생성하고 스트림을 통해 전송하는 역할을 합니다. 예를 들어, 데이터베이스에서 데이터를 읽거나, 센서에서 데이터를 수집하는 것이 여기에 해당합니다.
소비자 (Consumer): 스트림으로부터 데이터를 받아 처리하는 역할을 합니다. 이는 데이터를 분석하거나, 데이터베이스에 저장하는 작업 등이 될 수 있습니다.
스트림 처리 시스템에서는 생산자가 소비자보다 빠르게 데이터를 생산할 수 있습니다. 이런 경우, 소비자가 처리할 수 있는 것보다 더 많은 데이터가 스트림으로 전송되어 시스템에 부담을 줄 수 있습니다. 이를 '백프레셔'라고 합니다.
백프레셔를 관리하는 방법은 크게 두 가지가 있습니다:
버퍼링 (Buffering): 소비자가 처리할 수 있을 때까지 데이터를 일시적으로 저장하는 방법입니다. 하지만 버퍼의 크기가 한정되어 있어, 버퍼가 가득 찰 경우 추가 데이터의 처리가 어려워집니다.
플로우 컨트롤 (Flow Control): 소비자가 처리할 수 있는 속도에 맞추어 생산자의 데이터 전송 속도를 조절하는 방법입니다. 예를 들어, '백 프레셔' 신호를 통해 생산자가 데이터 전송을 일시 중단하거나 속도를 줄이는 것입니다.
이러한 백프레셔 메커니즘은 시스템의 안정성을 유지하고, 데이터 손실을 방지하는 데 필수적입니다. 예를 들어, 리액티브 프로그래밍 모델에서는 이러한 백프레셔를 자동으로 관리하는 기능을 제공하기도 합니다.
그러면 Java Stream API는 .Net의 Linq 에 대응하는가?
네, Java의 Stream API는 많은 면에서 .NET의 LINQ (Language Integrated Query)와 비슷한 역할을 합니다. 두 기술 모두 컬렉션 또는 데이터 시퀀스에 대해 쿼리를 수행하고 변환하는 데 사용되며, 모던 프로그래밍 언어에서 데이터 처리를 단순화하고 표현력을 향상시키는 데 중점을 둡니다.
Java Stream API
- Java 8에서 도입됨.
- 주로 컬렉션 프레임워크와 함께 사용됩니다.
- 람다 표현식과 함께 사용하여 데이터를 필터링, 변환, 정렬 등을 수행합니다.
- 함수형 프로그래밍 스타일을 채택하여 간결하고 선언적인 코드 작성을 가능하게 합니다.
.NET의 LINQ
- .NET 프레임워크 3.5에서 도입됨.
- 배열, 컬렉션, XML, 데이터베이스 등 다양한 데이터 소스에 대한 쿼리를 작성할 수 있습니다.
- 표준 쿼리 연산자를 사용하여 데이터를 필터링, 정렬, 그룹화 등을 수행합니다.
- 통합된 쿼리 언어로, 다양한 데이터 소스에 대해 동일한 쿼리 구문을 사용할 수 있습니다.
두 기술은 모두 개발자가 데이터를 더 쉽게 처리하고 관리할 수 있도록 설계되었습니다. 하지만, LINQ는 데이터 소스의 다양성과 쿼리 언어의 일관성에 더 중점을 두고, Java Stream API는 컬렉션에 대한 함수형 처리에 더 중점을 둔다는 점에서 차이가 있습니다.
.net의 비동기처리인 async/await 의 자바의 어느 요소와 대응되는가?
.NET의 async/await
async키워드를 사용하여 비동기 메서드를 정의합니다.await키워드를 사용하여 비동기 작업이 완료될 때까지 기다립니다.- 코드는 비동기 작업의 완료를 기다리는 동안 다른 작업을 수행할 수 있으므로, UI 스레드가 멈추지 않습니다.
- 코드 작성 및 가독성 측면에서 매우 효과적입니다.
Java의 CompletableFuture
CompletableFuture를 사용하여 비동기 계산을 캡슐화합니다.- 다양한 정적 메서드(예:
supplyAsync,runAsync)를 사용하여 비동기 작업을 시작할 수 있습니다. - 메서드 체이닝을 통해 결과 처리, 예외 처리, 작업 연결 등을 수행할 수 있습니다.
join또는get메서드를 사용하여 비동기 작업의 결과를 얻을 수 있으나,async/await보다는 좀 더 복잡한 코드가 될 수 있습니다.
CompletableFuture는 .NET의 async/await와 같은 단순성과 직관성을 완전히 제공하지는 못합니다. 그러나 Java에서 비동기 프로그래밍을 구현하는 데 필요한 기능과 유연성을 제공하며, Java 9의 추가적인 개선사항을 통해 더 강력하고 다양한 비동기 프로그래밍 기법을 지원합니다.
1에서 100까지의 숫자배열이 있고 이중에서 소수만 찾는 코드를 Java StreamAPI , .Net Linq를 이용해 구현코드를 작성해주세요
import java.util.stream.IntStream;
import java.util.List;
import java.util.stream.Collectors;
public class PrimeNumbers {
public static void main(String[] args) {
List<Integer> primeNumbers = IntStream.rangeClosed(1, 100)
.filter(PrimeNumbers::isPrime)
.boxed()
.collect(Collectors.toList());
System.out.println(primeNumbers);
}
private static boolean isPrime(int number) {
if (number <= 1) {
return false;
}
return IntStream.rangeClosed(2, (int) Math.sqrt(number))
.noneMatch(i -> number % i == 0);
}
}
using System;
using System.Linq;
using System.Collections.Generic;
public class PrimeNumbers
{
public static void Main()
{
var primeNumbers = Enumerable.Range(1, 100)
.Where(IsPrime)
.ToList();
Console.WriteLine(String.Join(", ", primeNumbers));
}
private static bool IsPrime(int number)
{
if (number <= 1) return false;
for (int i = 2; i <= Math.Sqrt(number); i++)
{
if (number % i == 0) return false;
}
return true;
}
}
이 코드들은 1부터 100까지의 숫자 중에서 소수를 찾아 출력합니다. Java의 경우 IntStream을 사용하여 범위를 지정하고, .NET에서는 Enumerable.Range를 사용하여 같은 범위를 정의합니다. 두 경우 모두 소수 판별 로직을 filter 또는 Where 메서드에 적용하여 소수만을 추출합니다.
위 배열을 활용 Java Stream API와 .NET의 LINQ 를 이용하여 첫글짜가 'A' 를 찾아 콜렉션을 반환하는 코드를 작성해죠
import java.util.List;
import java.util.stream.Collectors;
import java.util.Arrays;
public class FilterNames {
public static void main(String[] args) {
List<String> names = Arrays.asList("Emily", "Michael", "Olivia", "Ethan", "Sophia", "Daniel", "Ava", "Alexander", "Grace", "Lucas");
List<String> filteredNames = names.stream()
.filter(name -> name.startsWith("A"))
.collect(Collectors.toList());
System.out.println(filteredNames);
}
}
using System;
using System.Linq;
using System.Collections.Generic;
public class FilterNames
{
public static void Main()
{
List<string> names = new List<string> { "Emily", "Michael", "Olivia", "Ethan", "Sophia", "Daniel", "Ava", "Alexander", "Grace", "Lucas" };
var filteredNames = names.Where(name => name.StartsWith("A"))
.ToList();
Console.WriteLine(String.Join(", ", filteredNames));
}
}
위 코드에서 동시처리 능력 2를 적용해 작동하는 코드로 작성해죠
동시 처리 능력을 2로 설정하는 것은 코드에서 병렬 처리를 의미합니다. Java Stream API와 .NET의 LINQ 모두 병렬 처리를 지원합니다. Java에서는 parallelStream()을 사용하고, .NET에서는 PLINQ (Parallel LINQ)를 사용하여 병렬 처리를 구현할 수 있습니다.
Java Stream API를 사용한 병렬 처리 코드
Java에서는 parallelStream()을 사용하여 병렬 처리를 적용합니다. parallelStream()은 내부적으로 ForkJoinPool을 사용하며, 기본적으로 사용 가능한 모든 프로세서 코어를 사용합니다. 동시 처리 능력을 2로 제한하는 정확한 방법은 없지만, 시스템 속성을 사용하여 ForkJoinPool의 전역 병렬성 수준을 조정할 수 있습니다. 여기서는 기본 설정을 사용합니다.
import java.util.List;
import java.util.stream.Collectors;
import java.util.Arrays;
public class ParallelFilterNames {
public static void main(String[] args) {
List<String> names = Arrays.asList("Emily", "Michael", "Olivia", "Ethan", "Sophia", "Daniel", "Ava", "Alexander", "Grace", "Lucas");
List<String> filteredNames = names.parallelStream()
.filter(name -> name.startsWith("A"))
.collect(Collectors.toList());
System.out.println(filteredNames);
}
}
.NET의 PLINQ를 사용한 병렬 처리 코드
.NET에서는 PLINQ (Parallel LINQ)를 사용하여 병렬 처리를 수행합니다. AsParallel() 메서드를 사용하여 쿼리를 병렬로 실행할 수 있습니다. 동시 처리 능력을 제어하기 위해 WithDegreeOfParallelism 메서드를 사용할 수 있습니다.
using System;
using System.Linq;
using System.Collections.Generic;
public class ParallelFilterNames
{
public static void Main()
{
List<string> names = new List<string> { "Emily", "Michael", "Olivia", "Ethan", "Sophia", "Daniel", "Ava", "Alexander", "Grace", "Lucas" };
var filteredNames = names.AsParallel()
.WithDegreeOfParallelism(2)
.Where(name => name.StartsWith("A"))
.ToList();
Console.WriteLine(String.Join(", ", filteredNames));
}
}
이 코드들은 병렬 처리를 통해 첫 글자가 'A'인 이름들을 필터링합니다. Java의 경우 parallelStream()을 사용하며, .NET에서는 PLINQ의 AsParallel()과 WithDegreeOfParallelism()을 사용합니다.
위 코드를 rxJava로 닷넷은 rx.net 으로 작동되게 변환해주세요
RxJava와 Rx.NET (Reactive Extensions)는 비동기 및 이벤트 기반 프로그램을 작성하기 위한 라이브러리입니다. 이들은 비동기 데이터 스트림과 LINQ 스타일의 쿼리 연산자를 사용하여 복잡한 비동기 코드를 간단하고 선언적으로 표현할 수 있도록 해줍니다.
import io.reactivex.rxjava3.core.Observable;
import java.util.Arrays;
import java.util.List;
public class RxJavaFilterNames {
public static void main(String[] args) {
List<String> names = Arrays.asList("Emily", "Michael", "Olivia", "Ethan", "Sophia", "Daniel", "Ava", "Alexander", "Grace", "Lucas");
Observable.fromIterable(names)
.filter(name -> name.startsWith("A"))
.subscribe(System.out::println);
}
}
using System;
using System.Linq;
using System.Collections.Generic;
using System.Reactive.Linq;
public class RxNetFilterNames
{
public static void Main()
{
List<string> names = new List<string> { "Emily", "Michael", "Olivia", "Ethan", "Sophia", "Daniel", "Ava", "Alexander", "Grace", "Lucas" };
names.ToObservable()
.Where(name => name.StartsWith("A"))
.Subscribe(Console.WriteLine);
}
}
위 코드에서 초당 2로 처리능력을 제약하는것을 추천해죠
import io.reactivex.rxjava3.core.Observable;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.TimeUnit;
public class RxJavaRateLimitedFilterNames {
public static void main(String[] args) {
List<String> names = Arrays.asList("Emily", "Michael", "Olivia", "Ethan", "Sophia", "Daniel", "Ava", "Alexander", "Grace", "Lucas");
// Create an Observable that emits a long value every 500 milliseconds
Observable<Long> interval = Observable.interval(500, TimeUnit.MILLISECONDS);
Observable.fromIterable(names)
.filter(name -> name.startsWith("A"))
.zipWith(interval, (name, time) -> name) // Combine with the interval Observable
.subscribe(System.out::println);
// Keep the main thread alive for a short while to see some results
try {
Thread.sleep(10000); // Adjust the sleep time as necessary
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
이 코드는 Observable.interval을 사용하여 500밀리초 간격으로 long 값을 발행하는 타이머 스트림을 생성합니다. 이는 초당 2개의 항목을 발행하는 것과 동일합니다. 그런 다음, zipWith 메서드를 사용하여 원본 이름 스트림과 인터벌 스트림을 결합합니다. 이로써, 이름 스트림의 각 항목이 처리되는 사이에 500밀리초의 지연이 생기게 되어, 이름 처리 속도가 초당 2개로 제한됩니다.
using System;
using System.Linq;
using System.Collections.Generic;
using System.Reactive.Linq;
using System.Reactive.Concurrency;
public class RxNetRateLimitedFilterNames
{
public static void Main()
{
List<string> names = new List<string> { "Emily", "Michael", "Olivia", "Ethan", "Sophia", "Daniel", "Ava", "Alexander", "Grace", "Lucas" };
// Create an Observable sequence that emits a value every 500 milliseconds (2 per second)
var interval = Observable.Interval(TimeSpan.FromMilliseconds(500));
names.ToObservable()
.Where(name => name.StartsWith("A"))
.Zip(interval, (name, _) => name) // Combine with the interval sequence
.Subscribe(Console.WriteLine);
Console.ReadLine(); // Wait for the computation to finish
}
}
이 코드는 Observable.Interval을 사용하여 500밀리초마다 값을 방출하는 시퀀스를 생성합니다. 이는 초당 2개의 항목을 방출하는 것과 동일합니다. 그런 다음 Zip 연산자를 사용하여 이름 리스트와 인터벌 시퀀스를 결합하여, 초당 2개의 이름만 처리되도록 합니다.
Zip 연산자는 두 시퀀스의 각 항목을 결합할 때까지 기다립니다. 따라서, 인터벌 시퀀스의 각 항목이 방출될 때마다 이름 리스트의 항목 하나가 처리됩니다. 이 방식으로, 이름 리스트를 처리하는 속도가 초당 2개로 제한됩니다.
결과받은 값을 비동기함수로 호출하는 샘플도 공유해죠
import io.reactivex.rxjava3.core.Observable;
import io.reactivex.rxjava3.schedulers.Schedulers;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.TimeUnit;
public class RxJavaAsyncFunctionExample {
public static void main(String[] args) {
List<String> names = Arrays.asList("Emily", "Michael", "Olivia", "Ethan", "Sophia", "Daniel", "Ava", "Alexander", "Grace", "Lucas");
Observable.fromIterable(names)
.filter(name -> name.startsWith("A"))
.zipWith(Observable.interval(500, TimeUnit.MILLISECONDS), (name, time) -> name)
.flatMap(name -> asyncFunction(name)
.subscribeOn(Schedulers.io())) // Run the async function on the IO scheduler
.observeOn(Schedulers.single()) // Observe the results on a single thread
.subscribe(result -> System.out.println("Processed: " + result),
Throwable::printStackTrace);
// Keep the main thread alive for a short while to see some results
try {
Thread.sleep(10000); // Adjust the sleep time as necessary
} catch (InterruptedException e) {
e.printStackTrace();
}
}
private static Observable<String> asyncFunction(String name) {
return Observable.just(name)
.map(n -> {
// Simulate some asynchronous processing
try {
Thread.sleep(1000); // Simulate delay
} catch (InterruptedException e) {
e.printStackTrace();
}
return n.toUpperCase(); // Return some processed result
});
}
}
이 코드에서 asyncFunction은 비동기적으로 이름을 대문자로 변환하는 간단한 예제 함수입니다. 이 함수는 각 이름을 받아 1초 동안 대기한 후 이름을 대문자로 변환하여 반환합니다.
flatMap연산자는 각 이름을asyncFunction으로 전달하고, 결과를 새로운Observable로 반환합니다.subscribeOn(Schedulers.io())는asyncFunction의 처리를 IO 스케줄러에서 비동기적으로 실행하도록 합니다.observeOn(Schedulers.single())은 처리된 결과를 단일 스레드에서 관찰하고 출력하도록 합니다.
이 방식을 사용하면, 각 이름은 별도의 스레드에서 비동기적으로 처리되며, 주 스레드는 계속 실행 상태를 유지합니다.
using System;
using System.Linq;
using System.Collections.Generic;
using System.Reactive.Linq;
using System.Reactive.Concurrency;
using System.Threading.Tasks;
public class RxNetAsyncFunctionExample
{
public static void Main()
{
List<string> names = new List<string> { "Emily", "Michael", "Olivia", "Ethan", "Sophia", "Daniel", "Ava", "Alexander", "Grace", "Lucas" };
names.ToObservable()
.Where(name => name.StartsWith("A"))
.Zip(Observable.Interval(TimeSpan.FromMilliseconds(500)), (name, _) => name)
.SelectMany(name => AsyncFunction(name)
.ToObservable()
.SubscribeOn(TaskPoolScheduler.Default)) // Execute the async function on the task pool
.ObserveOn(Scheduler.Default) // Observe the results on the default scheduler
.Subscribe(result => Console.WriteLine("Processed: " + result),
ex => Console.WriteLine($"Error: {ex.Message}"));
Console.ReadLine(); // Wait for the computation to finish
}
private static async Task<string> AsyncFunction(string name)
{
// Simulate some asynchronous processing
await Task.Delay(1000); // Simulate delay
return name.ToUpper(); // Return some processed result
}
}
보너스
AKKA컨셉을 공유하는 JAVA/.NET버전
스레드 모델대신 액터모델이 유용한 경우 채택할수 있으며 자바와 닷넷의 비동기 처리모델에 개발방식의 큰차이가 있지만~ 두진영의 개발패턴이 동일한점이 특징입니다.
import akka.NotUsed;
import akka.actor.ActorSystem;
import akka.stream.ActorMaterializer;
import akka.stream.javadsl.Source;
import akka.stream.javadsl.Sink;
import java.time.Duration;
import java.util.Arrays;
public class AkkaStreamExample {
public static void main(String[] args) {
final ActorSystem system = ActorSystem.create("stream-example");
final ActorMaterializer materializer = ActorMaterializer.create(system);
// 배열에 저장된 이름들
String[] names = {"Emily", "Michael", "Olivia", "Ethan", "Sophia",
"Daniel", "Ava", "Alexander", "Grace", "Lucas"};
// Source 생성
Source<String, NotUsed> source = Source.from(Arrays.asList(names));
// 초당 2개의 요소를 출력하는 Sink
source.throttle(2, Duration.ofSeconds(1))
.runWith(Sink.foreach(System.out::println), materializer);
}
}
using Akka.Actor;
using Akka.Streams;
using Akka.Streams.Dsl;
using System;
using System.Linq;
class AkkaNetStreamExample
{
static void Main(string[] args)
{
using (var system = ActorSystem.Create("stream-example"))
using (var materializer = system.Materializer())
{
// 배열에 저장된 이름들
string[] names = {"Emily", "Michael", "Olivia", "Ethan", "Sophia",
"Daniel", "Ava", "Alexander", "Grace", "Lucas"};
// Source 생성
var source = Source.From(names);
// 초당 2개의 요소를 출력하는 Sink
source.Throttle(2, TimeSpan.FromSeconds(1))
.RunWith(Sink.ForEach<string>(Console.WriteLine), materializer)
.Wait();
}
}
}
Spring Boot에 최근 포함된 WebFlux 버전
- Spring Boot을 이용하는 경우~ Pivotal이 지원함으로 기본포함 스펙이용을 권장합니다.
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;
import org.springframework.web.reactive.function.server.RouterFunction;
import org.springframework.web.reactive.function.server.ServerResponse;
import reactor.core.publisher.Flux;
import java.time.Duration;
import static org.springframework.web.reactive.function.server.RouterFunctions.route;
@SpringBootApplication
public class WebfluxExample {
public static void main(String[] args) {
SpringApplication.run(WebfluxExample.class, args);
}
@Bean
public RouterFunction<ServerResponse> routerFunction() {
return route()
.GET("/stream-names", request -> {
String[] names = {"Emily", "Michael", "Olivia", "Ethan", "Sophia",
"Daniel", "Ava", "Alexander", "Grace", "Lucas"};
Flux<String> nameStream = Flux.fromArray(names)
.zipWith(Flux.interval(Duration.ofSeconds(1)))
.map(tuple -> tuple.getT1());
return ServerResponse.ok().body(nameStream, String.class);
})
.build();
}
}
DataLake에서 Reactive Stream을 준수하는 모듈을 이용하는경우~ 일괄적인 방법으로 데이터를 안전하게 처리할수 있습니다.
이러한 컨셉은 Rx.net 에서 최초 적용된 컨셉으로 자바진영에서는 Webflux를 통해서 이용할수 있습니다.(또는 Reactor / rxJava )
- Reactive Streams는 비동기 스트림 처리를 위한 표준입니다. 이는 데이터 스트림이 불특정한 소스(예: 사용자 이벤트, 외부 서비스 호출 등)에서 오는 경우에 사용되며, back-pressure를 지원하여 데이터 흐름을 제어할 수 있습니다.
다음은 reactive stream을 준수하는 객체를 이용하는경우~ 원격지의 데이터를 더 안정적으로 처리할수 있습니다.
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.common.serialization.StringDeserializer;
import reactor.core.publisher.Flux;
import reactor.kafka.receiver.KafkaReceiver;
import reactor.kafka.receiver.ReceiverOptions;
import software.amazon.awssdk.services.s3.S3Client;
import software.amazon.awssdk.services.s3.model.PutObjectRequest;
import java.util.Collections;
import java.util.HashMap;
import java.util.Map;
public class ReactiveKafkaToS3 {
private final S3Client s3Client;
private final ReceiverOptions<String, String> receiverOptions;
public ReactiveKafkaToS3(S3Client s3Client) {
this.s3Client = s3Client;
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "your-kafka-broker:9092");
props.put(ConsumerConfig.CLIENT_ID_CONFIG, "your-client-id");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "your-group-id");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
receiverOptions = ReceiverOptions.create(props);
}
public void consumeAndStore() {
KafkaReceiver.create(receiverOptions.subscription(Collections.singleton("your-kafka-topic")))
.receive()
.flatMap(record -> storeInS3(record))
.subscribe();
}
private Flux<Void> storeInS3(ConsumerRecord<String, String> record) {
PutObjectRequest putObjectRequest = PutObjectRequest.builder()
.bucket("your-s3-bucket")
.key("your-object-key")
.build();
return Flux.fromFuture(s3Client.putObject(putObjectRequest, software.amazon.awssdk.core.sync.RequestBody.fromString(record.value())).thenRun(() -> {
// S3에 성공적으로 저장된 후 처리
System.out.println("Stored in S3: " + record.value());
}));
}
public static void main(String[] args) {
// S3 클라이언트 초기화 및 서비스 시작
S3Client s3Client = S3Client.builder().build();
new ReactiveKafkaToS3(s3Client).consumeAndStore();
}
}
Parquet 로저장하기편
Webflux를 포함 ReactiveStream의 특징으로~ 스트림과같은 데이터처리의 흐름을 일관성있는 방식으로 처리할수 있습니다.
여기서 스트림의 의미는 유체를 의미하고 카프카와 같이 끊임없이 발생하는 이벤트를 다루는경우 배치기보다는 유체처럼 이벤트를 다루어야한다는 컨셉입니다.
그리고 이것은 OOP의 특징을 살려, 실세계에 존재하는 유압/유체제어 장치에서 아이디어를 가지고 왔습니다.
<dependencies>
<!-- 기존 의존성 -->
<!-- Apache Parquet와 Avro -->
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-avro</artifactId>
<version>YOUR_PARQUET_VERSION</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>YOUR_AVRO_VERSION</version>
</dependency>
</dependencies>
private Schema avroSchema; // Avro 스키마
public ReactiveKafkaToS3(S3Client s3Client, String schemaString) {
this.s3Client = s3Client;
this.avroSchema = new Schema.Parser().parse(schemaString); // Avro 스키마 초기화
// 기존 초기화 로직...
}
private Flux<Void> storeInS3(ConsumerRecord<String, String> record) {
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
try (ParquetWriter<GenericRecord> writer = AvroParquetWriter.<GenericRecord>builder(new org.apache.hadoop.fs.Path("data.parquet"))
.withSchema(avroSchema)
.withCompressionCodec(CompressionCodecName.SNAPPY)
.build()) {
GenericRecord avroRecord = new GenericData.Record(avroSchema);
avroRecord.put("your_field", record.value()); // Kafka 레코드의 값을 Avro 레코드에 셋팅
writer.write(avroRecord);
} catch (IOException e) {
e.printStackTrace();
}
PutObjectRequest putObjectRequest = PutObjectRequest.builder()
.bucket("your-s3-bucket")
.key("your-object-key.parquet")
.build();
return Flux.fromFuture(s3Client.putObject(putObjectRequest, software.amazon.awssdk.core.sync.RequestBody.fromBytes(outputStream.toByteArray())).thenRun(() -> {
System.out.println("Stored in S3: " + record.value());
}));
}
다음은 자바기준 Reactive Stream을 지원하는 대표적인 오픈스택으로~ 위와같은 일괄적인 방법으로 이벤트의 흐름을 스트림을 이용해 할수 있습니다.
|
|
|
|




Add Comment