Page History
...
메일박스를 가진 액터모델을 이용해 간단하게 할수있습니다. AKKACluster(이하 클러스터)의 개념을 먼저 살펴보고
Spring Boot에 탑재하는 탑재하여 클러스터로 작동시키는 구현 코드까지 알아보겠습니다.
목차
| Table of Contents |
|---|
클러스터화 앱의
...
특징
| 주제 | 클러스터 | 클러스터가 아님 | |
|---|---|---|---|
| 고성능 이벤트 분산처리 |
|
| |
| TPS 분배 |
|
|
|
| Role기반 처리 |
|
| |
| 라우터기반 분산 |
|
| |
| AkkaStream |
|
|
클러스터화된 기능을 사용하기위해 이미 클러스터화된 시스템을 주로 이용할수도 있지만
...
| ||
| BackPresure |
|
|
분산처리를위해 이미 클러스터화된 카프카와같은 외부 큐시스템만 할용할수도 있겠지만
우리가 설계한 클러스터는 외부시스템과도 연동할수 있으며 주로 내부앱에서 발생하는 분산처리 문제를 다룰 있으며
단독 어플리케이션이 어떻게 상호 연결되는 클러스터화가 되는지 AkkaCluster Flow를 살펴보겠습니다.
...
클러스터에 작동하는 앱은 모두 Role기반으로 작동이되며~ 설계자에 의해 필요한 Role과 구성을 자유롭게 할수 있으며 여기서 소개된 클러스터의 어플리케이션 레벨에서
개발자가 직접 할수 있으며 여기서 구현및 설계된 구성과 Role을 살펴보겠습니다.
Cluster Role
...
- LightHouse(Seed) : Cluster내 역할을 가진 노드들이 클러스터링 연결될수 있도록 Discovery역할을 하게됩니다Discovery역할을 하게됩니다.
- Role-Work : work 롤이 부여된 로드는 스케일아웃이 가능하며 최종 분산처리된 이벤트의 작업을 수행하게 되며, 작업완료는 이 작업완료를 필요로하는 Role에게 완료보고를 선택적으로 할수도 있습니다.
- Role-Work : work 롤이 부여된 로드는 스케일아웃이 가능하며 분산처리를 Role-Manager : 클러스터내에 단하나만 작동하도록 구성하여 단일배치및 클러스터 이벤트 종합집계등 특수한 역할을 부여할수 있습니다.
- AkkaCluster에서는 SingleTone Cluster를 이용하여~ 이중화구성하여 스탠바이모드로 두개가 구성되어있지만 단 하나만 활성 작동하도록 구성할수도 있습니다.
...
| Code Block | ||
|---|---|---|
| ||
for(int i=0;i<testCount;i++){
clusterActor.tell(testMessage + i , ActorRef.noSender());
} |
RestAPI로 유입되는 외부분산처리는 LB를 이용할수 있지만, 클러스터내 내부간 통신에서는 LB가 지원하는 단순한 분배처리대비
RestAPI보다 수백배 빠른 고성능( Netty를 채택할수도 있고, 구글 프로토콜버퍼가 이용될수도 있습니다) 분배 처리를 할수 있습니다.
Akka 액터모델에서 기본 지원하는 라우터를 클러스터에서 이용함으로 복잡한 분산처리를 단순화할수 있습니다.Nginnx와 같이 LB를 일반적으로 이용하는경우 라운드로빈과 같은 비교적 간단한 방식만 채택할수 있지만.
클러스터(AKKA)가 구성되고 나면 다음 제공되는 다양한 라우터를 사용할수 있으며
메시지 우선순위 역전과같이 필요한경우 라우터로직만 교체할수도 있습니다.
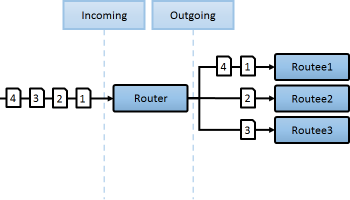
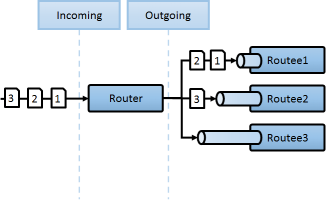
- 라우터 : 분배의 방식
- 라우팅 : 분배가 발생하는 실제 장치
- 라우티 : 분배가 도착하는 도착지
클러스터에서 이용할수 있는 라우터의 종류
...
이름 | 특징 |
|---|---|
|
|
|
|
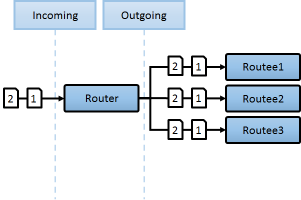
| 랜덤 메시지 전송 |
|
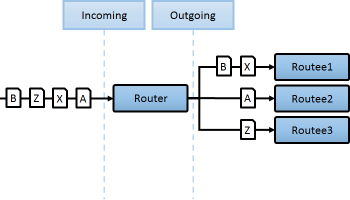
특정 처리에 대해 해시값기반 베이스로 노드의 변경의 가능성을 최소화할때 웹소켓의 경우 hanshake를 위해 LB-l7 레이에서도 이용하는 전력으로 AKKA에서는 특정 해시이벤트가 특정노드에 작동처리 보장됨으로 네트워크로 이용해야하는 Redis보다 수십배 빠른 인 메모리 캐시를 이용할수 있습니다. |
| 기본적으로 랜덤이나, 느린놈을 제외하고 특정시간이 지나야 다시 합류시킴(일반적으로 빠른 응답속도 보장용) 옵션: |
|
|
|
|
|
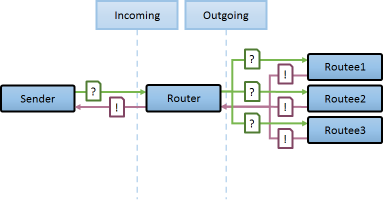
성능을 위해 다중노드로 구성하였으며, 가장 빠르게 처리한 녀석의 결과를 사용할시 옵션: |
...
| Code Block | ||
|---|---|---|
| ||
akka{
actor {
provider = cluster
}
remote.artery {
canonical {
hostname = "127.0.0.1"
port = 12551
}
}
cluster {
seed-nodes = [
"akka://ClusterSystem@127.0.0.1:12551"
]
role{
seed.min-nr-of-members=1
}
# auto downing is NOT safe for production deployments.
# you may want to use it during development, read more about it in the docs.
#
auto-down-unreachable-after = 10s
downing-provider-class = "akka.cluster.sbr.SplitBrainResolverProvider"
}
extensions=["akka.cluster.metrics.ClusterMetricsExtension"]
} |
일반적인 분산 시스템 알고리즘은 퀴럼(Quorum)을 이용하며 즉 작업을 진행하기 위해 동의해야 하는 최소한의 노드 수를 기반으로 합니다. 홀수 구성은 이러한 알고리즘을 더 효율적으로 만들 수 있습니다.
클러스터 노드가 홀수로 구성되어야 안정적/효율적으로 운영될수 있다란 기초지식은 이러한 SplitBrain을 해결하는 투표 알고리즘 방식에 기인을 하며
Role별로 제공되는 SplitBrain 해결전략을 선택할수 있습니다. 이것은 대부분의 클러스터시스템이 튜닝옵션으로 유사하게 제공하는 부분일수도 있기때문에
...
클러스터 내에서 일반 노드에 장애가 발생했을때 해당 노드만 빠르게 제거하고 클러스터를 문제없이 가동시키는 것은 중요합니다.
클러스터내 장애감내(허용) 를 위한 컨셉은 꼭 AKKA가 아니여도 클러스터를 단지 이용하게 되는경우도 도움될수 있습니다.
Cluster 내 Split Brain 해결전략
...
Static Quorum
- 특징: 정해진 수의 노드가 온라인 상태여야 클러스터가 작동하도록 요구하는 전략입니다. 이는 특히 클러스터 노드 수가 비교적 작을 때 유용합니다.
- 적용 시나리오: 클러스터가 비교적 작고, 정해진 수의 노드가 항상 온라인이어야 하는 경우.
Keep Majority
- 특징: 네트워크 분할이 발생했을 때, 가장 많은 노드를 포함하고 있는 파티션을 유지하고 나머지는 종료합니다. 이는 가장 큰 세그먼트가 클러스터의 '진짜' 상태를 가지고 있다고 가정합니다.
- 적용 시나리오: 클러스터의 가용성을 최대화하려는 경우, 특히 클러스터 크기가 크고 노드 분포가 균일한 환경에서 유용합니다.
Keep Oldest
- 특징: 클러스터 내 가장 오래된 노드가 포함된 세그먼트를 유지합니다. 이 전략은 오래된 노드가 중요한 역할을 하거나 상태 정보를 가지고 있다고 가정합니다.
- 적용 시나리오: 클러스터 내 특정 노드(예: 가장 오래된 노드)가 중요한 역할을 할 때 유용합니다.
Down All
- 특징: 네트워크 분할 상황이 발생하면 클러스터의 모든 세그먼트를 종료시킵니다. 이는 데이터의 일관성을 최우선으로 고려할 때 선택할 수 있는 극단적인 전략입니다.
- 적용 시나리오: 데이터 일관성이 매우 중요하고, 네트워크 분할 상황에서 어떠한 데이터 손실도 허용되지 않는 경우.
Lease Majority
- 특징: 외부 리소스(예: 데이터베이스)에 'lease'(임대) 개념을 사용하여 클러스터의 한 세그먼트만이 리소스를 '임대'할 수 있도록 합니다. 다른 세그먼트는 이 리소스를 사용할 수 없게 됩니다.
- 적용 시나리오: 외부 시스템이나 리소스와의 일관성을 유지해야 하고, 해당 리소스에 대한 접근을 제어할 수 있는 경우.
도커이전 클러스터 시스템을 구성하는것은 의존요소 설치및 멀티노드 구성을 복잡하게 해야했으나
도커 등장이후 네트워크 제어를 포함 클러스터화된 앱을 로컬에서 모두 구성하고 테스트하는것은 그리 어려운일이 아닌게 되었습니다.
도커툴과함께 Test가능한 API를 클러스터 액터에 연결함으로 고성능으로 분산처리되는 기능을 테스트해볼수 있게되었습니다클러시스템을 설계하고 개발하는경우 개발 테스트를 위해 로컬에 클러스터를 유사하게 구성하는것은 중요하며
Docker + Swagger 조합으로 여기서 소개한 클러스터를 TEST할수 있습니다.
클러스터 TEST by Docker
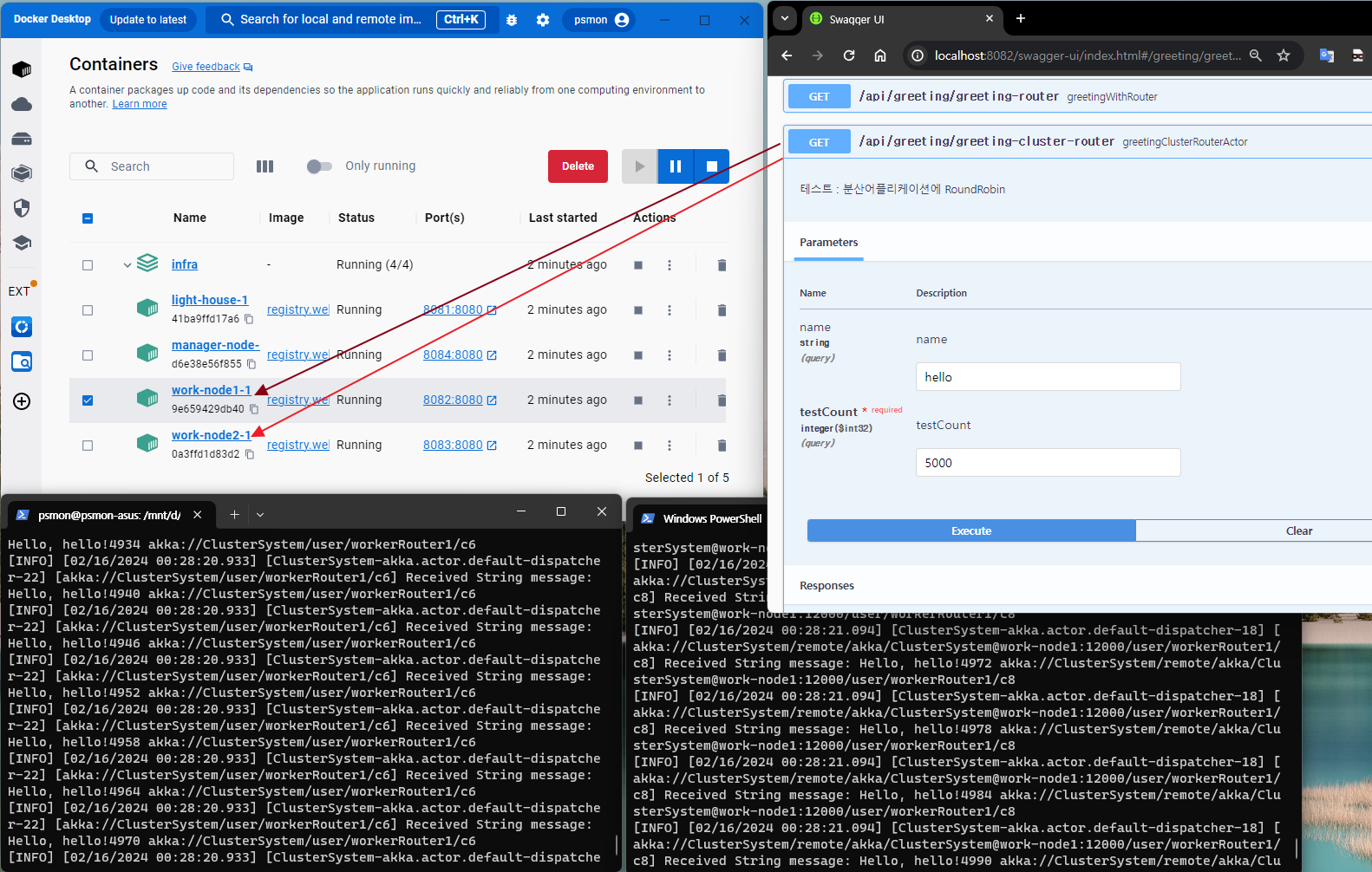
- 클러스터앱 빌드및 실행
- https://github.com/psmon/java-labs/blob/master/infra/docker-compose-cluster-local.yml
- 실험코드를 내려받고 아래 명령을 통해 로컬빌드및 클러스터 app 구동이 원큐에 가능합니다.
- javalabs\infra>docker-compose -f docker-compose-cluster-local.yml up -d
- https://github.com/psmon/java-labs/blob/master/infra/docker-compose-cluster-local.yml
...