대량의 데이터에서 탐색을 빠르게하기 위해, 성능적으로 느린 저장장치의
IO접근을 최소화하기위해 인덱스를 설정하게됩니다.
저장된 컨텐츠,규모,필요한 요구응답시간에 따라 인덱스 전략은 달라지게 됩니다.
여기서는 전략에 촛점을 두기보다, 다양한 키/인덱스를 JPA에서는 어떻게 지정하는지 살펴보겠습니다.
Primary Key
기본키 제약조건:
- null 값 허용안함
- 유일해야한다
- 변해서는 안된다.
JPA에서 Id 어노테이션은 기본키전략을 수행한다고 보면됩니다.
단일컴럼 기본키
| JPA Entity | SQL-DDL |
|---|---|
@Entity
public class Project {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Integer id;
}
| CREATE TABLE `project` ( `id` int(11) NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
기본키 자동 생성 전략
논리적 키 선택전략:
- 자연키 : 비지니스에 의미가 있는 키(ex.주민번호)
- 대리키 : 비지니스와 관련없는 임의키(자동생성)
크게 두가지 전략이 있으며 기본키 전략을 자동생성으로 선택하였다고 가정합니다.
- AUTO : JPA가 DB가 지원하는 가능전략중 하나를 선택(주로 초기 프로토타잎에서 사용)
- IDENTITY : 데이터를 Insert한후에 기본키를 알수 있음,최적화를 위해서 저장과동시에 알수있는 방법 고민필요(JPA별도객체제공)
- SEQUENCE : DB가 유일한 값 생성을 보장하는 순차 오브젝트가 있기때문에 이기능을 활용
- TABLE : SEQUENCE가 지원되지 않는 DB에서 유사한 기능을 사용하려고, 별도의 TABLE에서 다음할당키를 관리
체번의 최적화/충돌을 피하기위해 SQL문 혹은 어플리케이션 개발자체가 변경되는 케이스가 많이 발생하였을것입니다.
JPA에서는 자동생성 옵션에따라 내부 작동을 약간씩 다르게하여, 최종 사용방식을 일관성 있는 방식으로 맞추려고 시도합니다.
다중컬럼 기본키
단일컬럼을 통해서 충분히, 기본키의 제약조건을 준수할수 있지만, 성능계에서는 다르게 해석합니다.
기본키는 DB에따라 클러스터 인덱스가 사용될수있으며 의미없는 자동 단일키로는 탐색에서 효과를 받을수가 없습니다.
유일한 키가 있음에도 불구하고 컬럼값 하나를 더 조합해야하는 경우도 만들기도 합니다.
쉬운 예를들면, 단순하게 최신순으로 페이징처리를 많이 호출한다라고 하면 단인 컬럼으로 충분합니다.
하지만 특정 월별로 페이징처리가 된다라고 가정하면, DateType을 기본키에 썩어줘서 물리적인 구분을하면
검색에 이득이 될수도 있다란 의미입니다.
클러스터 인덱스 와 논 클러스터 인덱스의 차이는 다음장 실행계획에서 좀더 자세한 정보를 파악할수가 있습니다.
탐색능력향상을 위해 기본키를 통한 실제 물리적 파티셔닝 나누기 기능을 사용하기도합니다.(DB마다 지원여부및 활용방법틀림)
다중컬럼 기본키는 이러한 성능전략에 사용될수 있으며 DBMS 분산저장 기능이 더 똑똑해지고, IO가 훨씬더 빨라지는 시점에
이러한 전략이 계속 유용하고, 탐색/분석 솔류션에서 유용한것인지? 는 논외의 연구 과제로 두겠습니다.
기본키 결합 종류
- 자연키 + 자연키 : 의미 있는 비지니스키 두가지 값이 결합하여 유니크한 정보를 만들어내기때문에 변경가능성이 없다고 했을때 이상적입니다.
- 유일키 + 그룹정보 : 유일키 + 유니크와 상관없는 어떠한 그룹정보를 결합하여 필터및 소트탐색에 성능적으로 유리하게 합니다.
기본키 다중컬럼의 이점을 설명하였지만, JPA에서는 기본키를 단순하게 가져가는 전략을 기본적으로 선택합니다.
데이터베이스가 가진 Row와 어플리케이션이 가지고 있는 Entity가 동일하다라는 판별이 되는 가장 중요한 조건이기 때문입니다.
하지만, EmbeddedId 를 통해 복잡하게 가져가는 키구조에대해 대응이 가능합니다.
| JPA | SQL-DDL |
|---|---|
@Entity
public class Project2 {
@EmbeddedId ProjectId id;
}
| CREATE TABLE `project2` ( `branchName` varchar(255) NOT NULL, `projectId` int(11) NOT NULL, PRIMARY KEY (`branchName`,`projectId`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
@Embeddable
public class ProjectId implements Serializable {
int projectId;
String branchName;
public ProjectId(int projectId, String branchName) {
this.projectId = projectId;
this.branchName = branchName;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result
+ ((branchName == null) ? 0 : branchName.hashCode());
result = prime * result + projectId;
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
ProjectId other = (ProjectId) obj;
if (branchName == null) {
if (other.branchName != null)
return false;
} else if (!branchName.equals(other.branchName))
return false;
if (projectId != other.projectId)
return false;
return true;
}
|
Clustered Index(BTREE알고리즘) 에서 효과를 보기위해 기본키를 다중컬럼으로 지정하였습니다. 물론이것은 branchname으로 정렬을 한다거나 filter조건을 걸때 탐색 이득이 생깁니다. 물론 이경우도 데이터의 분포도가 넓고 분포도에따른 밀집도가 비슷해야 이득을 볼수 있습니다. JPA에서는 BTREE,Clusted등 의 옵션에는 관여할수없습니다. DBMS에서 지정할수 있는 옵션이며 DB에따라 지원하지 않거나,작동방식이 다를수 있습니다. |
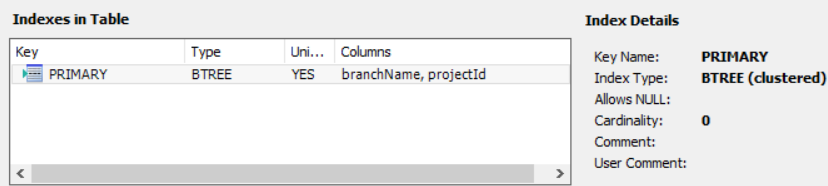
JPA에서 다중컬럼을 기본키로 하고,JPA내부 Repository에서 활용하기 위해
다중컴럼을 포함하고 있는 ProjectID에대해 번거러운 두가지 정의 작업을 해야합니다.
- ProjectID 정의하기(DB에는 인덱스 기본키 정보에 해당하는 내용입니다)
- 유일한값 가져오기 : hashCode()
- 동일한지 체크 : equals()
이것은 JPA가 데이터베이스의 질의를 통해서만 모든것을 처리하는게 아닌,
어플리케이션 레이아웃에서 JPA PROXY/영속성 처리에서 코드레벨에서 먼저
판별조건으로 사용됨을 의미합니다.
JPA가 쿼리를 만들기전 어플리케이션이 이미 알고 있는 내부 임시 저장소에서
동일한 ProjectId(projectid,branchname)를 추가하려고 한다고 하면
쿼리를 날리기전(DB호출없이)에 에러를 낼수있음을 암시합니다.
클러스터인덱스는 다양한 검색조건에대해 항상 빠른것이 아니며, 특정한 경우 빠릅니다.
그래서 성능을위해 기본키에 어떠한 값을 더 추가하여 물리적으로 나누어
성능을 높이겠다란 계획은 실패할 가능성이 높습니다.
비지니스적 검색기능의 효율을 높이고 싶다고하면 후보키설정을
똑똑하게 하는것이 추천됩니다.
사용자정의(후보키) 인덱스설정
후보키는 기본키에서 다음 제약이 분리되어 옵션및 조합으로 사용가능합니다.
- 복수개 지정가능
- 널 허용 : 인덱스 스캔및 중복체크 대상이 아닙니다. 값이 없음을 허용한다란 의미입니다.
- 유니크 : 필드,인덱스의 속성으로 값중복이 허용되지 않습니다.
Entity정의
인덱스를 두개 임의 설정하고, 특정 필드에는 유니크 조건을 걸었습니다.
유니크키,복합키,복합키+유니크키등을 모두 퉁쳐 설명하려고 만들 샘플입니다.
@Entity
@Table(indexes = {
@Index(name = "IDX_MYIDX1", unique=true, columnList = "idxf1,idxf2"),
@Index(name = "IDX_MYIDX2", unique=false, columnList = "idxf3,idxf4")
})
public class EntityWithCompositeIndex {
@Id
private long id;
@Column(name="idxf1",unique=true)
private String idxf1;
@Column(name="idxf2",unique=true)
private int idxf2;
@Column(name="idxf3",unique=true)
private int idxf3;
@Column(name="idxf4",unique=false)
private int idxf4;
}
테이블 인덱스 확인
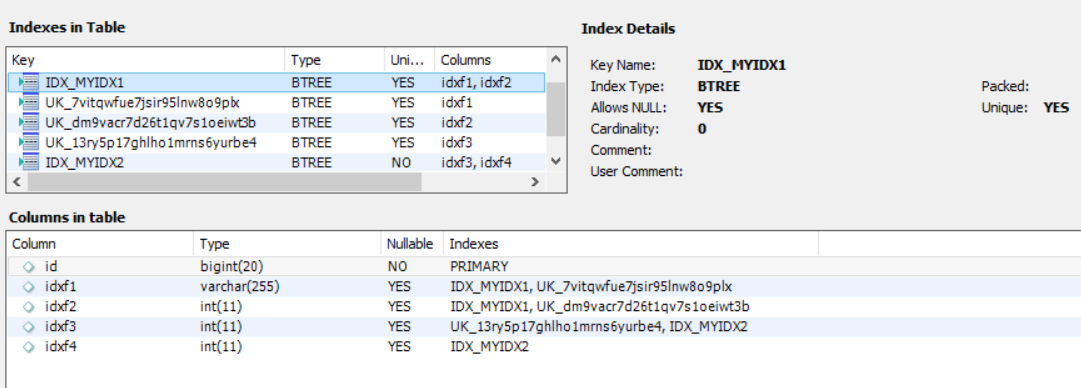
임의로 건 인덱스(IDX_MYIDX1,2)는 두개인데, 3개가 더 추가되어있습니다. Unique=true준것만으로 추가적인 인덱스 설정이 됨을
의미합니다. Unique 도 키의 한가지 종류인것을 알수 있습니다. ( Entity에서의 Unique는 유일한지 설정되는 속성값입니다.)
SQL DDL확인
CREATE TABLE `entitywithcompositeindex` ( `id` bigint(20) NOT NULL, `idxf1` varchar(255) DEFAULT NULL, `idxf2` int(11) DEFAULT NULL, `idxf3` int(11) DEFAULT NULL, `idxf4` int(11) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `IDX_MYIDX1` (`idxf1`,`idxf2`), UNIQUE KEY `UK_7vitqwfue7jsir95lnw8o9plx` (`idxf1`), UNIQUE KEY `UK_dm9vacr7d26t1qv7s1oeiwt3b` (`idxf2`), UNIQUE KEY `UK_13ry5p17ghlho1mrns6yurbe4` (`idxf3`), KEY `IDX_MYIDX2` (`idxf3`,`idxf4`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8
외래키
기본키/후보키등은 주로 성능에 관련되어 DBMS에의해 내부적으로 작동되는것이다라고 하면
외래키는 테이블 끼리의 연관도외에, OOP에서 Entity의 연관도 즉 기능과 설계에 관련된것이기때문에
별도로 분리하였습니다. 단순히 외래키를 설정한다와 테이블의 연관도를 잘 설계한다라는 아주 다른 이슈입니다.
http://wiki.webnori.com/display/webfr/02-DBHANDLE+with+JPA#id-02-DBHANDLEwithJPA-JPARelation