JPA의 컨셉은 Java Persistence API 의 약자로 두가지 큰 목적을 가지고 있으며
- 데이터 베이스에 존재하는 모델링을 자바객체로 맵핑을 시킴
- SP/SQL방식을 최대한 억제하고, OOP중심적 Entity설계및 영속성 Repository를 통한 데이터 제어
위 특징은, 스프링의 웹요소와 연동할때도 유용하게 쓰입니다.
CodeLink : http://git.webnori.com/projects/WEBF/repos/spring_jpa/browse
접속 DB 설정
# application.properties spring.jpa.hibernate.ddl-auto=update spring.datasource.url=jdbc:mysql://localhost:3306/spring spring.datasource.username=test spring.datasource.password=test1234
spring.jpa.hibernate.ddl-auto 옵션
none:테이블 구조 변경에 관여하지 않지않기때문에, DB 스키마와 JPA 모델을 맞추어놓아야합니다.
update:JPA에서 정의한 데이터모델과, 데이터베이스의 스키마 변경이 있을때 반영됩니다.create:어플리케이션 구동시 drop+create 를 수행create-drop:어플리케이션 구동시 drop+create를 수행하고 종료시 drop수행- validate : 테이블과 엔티티매핑정보가 맞지않으면 어플리케이션 실행하지 않음
DDL(Data Definitison Language)의 테이블 객체의 생성(Create),변경(Alert),삭제(Drop)등을
수행하는 명령문이라고 보시면됩니다. JPA에서는 옵션이라고 단순하게 설명을 하였지만
개발 프로토타잎/반영 자동화등에 활용될수 있으나 어플리케이션에서 DDL을 정책없이
모두 허용하는것은 위험합니다.
데이터베이스를 개발,유지,운영하는 정책/권한/전략과 상관이 있는 중요한 옵션입니다.
추가 용어설명
- DML(Data Manipulation Language) : 스키마객체의 데이터를 Insert/Update/Select등을 할수 있는 명령어(표준화되어있어서 거의 공통)
- DCL(Data Control Language) : Commit,RollBack,SavePoint등을 할수 있는 명령어(DB종속적인 경우가 많음)
JPA는 DDL/DML/DCL 모두 할수 있는 구조로 설계되어 있습니다.
네이밍룰
JPA에서 class를 통해 테이블을 정의할때 몇가지 규칙이 있습니다.
기본 네이밍룰
| 항목 | DB | JPA객체 | 설명 |
|---|---|---|---|
| Table(Class) | sample_table | SampleTable | 헝가리 표기법을따름 |
| Field(member) | sample_name | sampleName | 카멜표기법을 따름 |
db에따라 기본 네이밍룰은 약간의 차이가 있을수도 있습니다.
OS에따라 필드명 대소문자가 구분될수도 있기때문에,
JPA를 사용한다면 경험상 db필드명자체에 카멜/헝가리표기법이 사용되거나 혼용되는
방식은 추천되지 않습니다.( 일괄적으로 대문자이던지? 소문자이던지?)
지역 네이밍룰
만약 네이밍규칙을 다르게하고싶으면, Class명 혹은 필드명 바로위에 아래와같은 어노테이션을 사용합니다.
이미 만들어진 테이블이 있고, 네이밍 규칙을 전체적으로 통일할수 없을시 부분 적용가능합니다.
- @Table(name=”SAMPLE_TABLE”)
- @Column(name = “COLUMN_NAME”,nullable=false)
전역 네이밍룰
JPA의 기본네이밍룰이 맘에 안든다고하면, 전역 네이밍룰 변경이 가능합니다.
application.properties:
- spring.jpa.hibernate.naming.strategy=org.hibernate.cfg.EJB3NamingStrategy
- spring.jpa.hibernate.naming.physical-strategy=org.hibernate.boot.model.naming.PhysicalNamingStrategyStandardImpl
방언설정
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.H2Dialect
각각의 DB에따라 약간식 틀린 SQL문을 방언이라고하며 , JPA에서는 특수한 DB를 사용했을시
방언지정을 통해 소스변경없이, JPA의 일괄적인 인터페이스내에서 작동되도록 지원합니다.
예를들면 MYSQL에서는 페이지처리를 위해서 Limit를 쓴다거나, Oracle에서는 Rownum을쓴다거나
하는 차이를 알필요없이 JPA가 제공하는 Pageable을 통해 공통처리가 된다는것입니다.
그럼에도 불구하고, JPA의 어떠한 기능인터페이스를 활용했을때 실제 호출하는 SQL문을 알아둘필요가
있습니다.
Data Model(Entity) 생성
JPA영속성에서 객체를 유일하게 식별할수 있는 Id어노테이션은 필수입니다.
테이블의 기본키에 대응하는 키워드입니다.
package com.psmon.springdb;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
@Entity // This tells Hibernate to make a table out of this class
public class User {
@Id
@GeneratedValue(strategy=GenerationType.AUTO)
private Integer id;
private String name;
private String email;
@Column(columnDefinition="char(1)")
private String categorycode1;
}
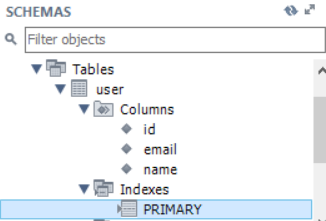
실제 DataBase에서는 위와같은 테이블이, 어플리케이션 시작시 자동 생성됩니다.
DB 종속 특수한 필드는(ex> char(1), columnDefinition을 통핸 맵핑처리가능합니다.)
DateTime의 경우 좀더 다양한 맵핑전략이 필요하며 다음 링크를 참고합니다:
http://www.developerscrappad.com/228/java/java-ee/ejb3-jpa-dealing-with-date-time-and-timestamp/
CRUD 저장소생성
전통적인 DataBase를 이용하는 개발방법은, SQL을 직접이용하거나, 관리되는 SP를 이용하여 Table의 정보를 읽거나 변경을 하였습니다.
JPA에서는 CrudRepository를 이용하여 조금더 객체 지향접근방식을 통해 Database를 제어하려고 합니다.
User테이블을 제어하는 객체를 정의하기 위해서, 여기서는 UserRepository 라고 정의를 하였습니다.
기본적인 조회기능/업데이트/삭제 기능만 사용한다고 하면, 이 코드에서 추가해야할 코드가 없어도됩니다.
상속받은 CrudRepository에 이미 Create/Read/Update/Delete와 관련된 사용가능한 기본 인터페이스가 정의되어있습니다.
package com.psmon.springdb;
import org.springframework.data.repository.CrudRepository;
//This will be AUTO IMPLEMENTED by Spring into a Bean called userRepository
//CRUD refers Create, Read, Update, Delete
public interface UserRepository extends CrudRepository<User, Long> {
}
CRUD를 이용하여 데이터 제어하기
CURD를 이용한 데이터제어를 유닛테스트기를 이용하여 테스트해보겠습니다.
간단하게 사용자를 추가하고, 조회를 하는 코드입니다.
package com.psmon.springdb;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
@RunWith(SpringRunner.class)
@SpringBootTest
public class JparestdemoApplicationTests {
@Autowired
private UserRepository userRepository;
@Test
public void contextLoads() {
jpaTest1();
}
public void jpaTest1() {
// 사용자 생성
User addUser = new User();
addUser.setName("minsu");
addUser.setEmail("test@x.com");
userRepository.save(addUser);
// 사용자 조회
Iterable<User> userList = userRepository.findAll();
userList.forEach(item->System.out.println(item.getName() ));
}
}
위코드는 실제 아래와같은 SQL문을 실행합니다.
-- 사용자생성
INSERT INTO `spring`.`user`
(`id`,
`email`,
`name`)
VALUES
(<{id:}>,
<{email: >,
<{name:}>);
-- 사용자 조회
SELECT * FROM user
JPA RelationShip
일반적으로 DB의 테이블은 하나의 테이블에 모든 정보를 포함하여 설계하지않고,
데이터의 효율적인 관리를 위해서 몇개의 테이블구조로 나누어 저장후 연관관계 형성을하게 됩니다.
이렇게 구조적으로 나뉜 테이블을 하나의 테이블정보인것처럼 정보를 머지를 하려면 JOIN을 통해 테이블을 지배해야합니다.
JPA 객체처리모델에서는 SQL문의 JOIN문을 직접적으로 사용하지 않고, 객체포함/상속등 OOP의 특성으로
데이터베이스의 관계 형성과 유사한 효과를 내려고 합니다. 그 목적을 달성하기위해 테이블과 클래스의 몇가지 차이점을 알아야합니다.
Class VS Table
| Class | Table |
|---|---|
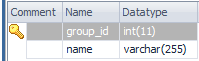
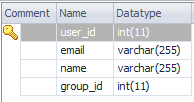
Class GroupInfo{ string name; } Class User{ GroupInfo groupInfo; string name; string email; } Class GroupInfoNew{ string name; List<User> userList; } | GroupInfo
User
select * from user u join groupinfo g on g.group_id=u.user_id |
- Class : 포함되는 객체는, 자신을 포함하는 객체 찾기가 어려우며,주인객체로 단방향접근이 일반적입니다. ( User → GroupInfo )
- Table : 테이블은 자유로운 결합이 가능하며 연관관계 아이디를 통해 양방향접근이 가능합니다. ( User ↔ GroupInfo )
- Class : 클래스는 객체자체를 리스트화하여 가질수 있습니다.
- Table : 테이블은 리스트형태의 데이터자체를 포함하는것은 불가능하며, 일대다 관계가 형성된 테이블을 통해 논리적 구성을 하여야합니다.
이와같은 차이를 극복하고, 데이터베이스의 Table을 객체지향적 인 모델로 변경을하여 사용하려면
Class(OOP)에 데이터베이스의 관계도(Relation)를 형성하는 몇가지 키워드의 의미를 알아야합니다.
아래 키워드는 OOP가 가진 특성을 잃지않고 , 관계형 DB의 속성을 확장을 해줍니다.
- ManyToOne : 다대일 관계 매칭정보
- JoinColumn : 외래키를 매핑때 사용함
- mappedBy : 연관관계설정시 주인이 아님을 설정
- OneToMany : 일대다 관계 매핑정보
- OneToOne : 일대일 관계 매칭정보, 어느곳이나 외래키를 가짐
- ManyToMany : 다대다 관계매칭정보, 맵핑테이블을 만들어서 사용하기를 권장
- 연관관계주인 : 외래키가 있는곳이 주인이며 주인만이 수정가능 아닌경우 조회만가능
외래키/인덱스

JPA를 사용하면 , 테이블 설계를 OOP를 통해 Entity(Class)에 직접 하는 전략을 선택합니다.
그리고 그것은 자동적으로 테이블을 만들어내는 DDL기능까지 수행할수 있습니다.
자신이 설계한, Entity CLASS가 어떠한 테이블 스키마에서
어떠한 관계가 형성이되고 인덱스를 설정하는지 파악하는것은 중요한 사안입니다.
어플리케이션에서 테이블 생성전략(DDL)은 일반적으로 개발단계까지 허용이되며,
운영에서 어플리케이션이 테이블 구조를 변경하는것은 허용하지 않는 정책을 사용합니다.
DDL기능을 OFF시키거나, 어플리케이션 내에는 변경 코드 자체가 없을수도 있습니다.
어플리케이션 개발자에게 DBA에 준하는 권한을 줘야 개발/운영/배포가 가능한 구조에서
어플리케이션 에게 DDL을 무조건 금지하는 정책이 어떠한 의미를 가지는지 고민이 필요해보입니다.
식별관계 VS 비식별관계
- 식별 관계는 부모 테이블의 기본 키를 자식 테이블로 전파하면서 자식 테이블의 기본 키 컬럼이 점점 늘어난다. 그러면 조인할 때 SQL이 복잡해지고 기본 키 인덱스가 불필요하게 커질 수 있다.
- 식별 관계는 2개 이상의 컬럼을 합해서 복합 기본 키를 만들어야 하는 경우가 많다.
- 식별 관계를 사용할 때 기본 키로 비지니스 의미가 있는 자연 키 컬럼을 조합하는 경우가 많다. 반면에 비식별관계의 기본 키는 비지니스와 전혀 관계없는 대리 키를 주로 사용한다.
- 언제든지 요구사항은 변한다. 식별 관계의 자연 키 컬럼들이 자식에 손자까지 전파되면 변경하기 힘들다.
- 식별 관계는 부모 테이블의 기본 키를 자식 테이블의 기본 키로 사용하므로 비식별 관계보다 테이블 구조가 유연하지 못하다.
어느 한가지가 항상 유리한것은 아니기때문에, 키 전파가 되는것에 따라 이러한 차이가 있다라고 알우둡니다.
이후 샘플은 비식별관계만 이용하여, JPA 연관특성을 살펴 보겠습니다.
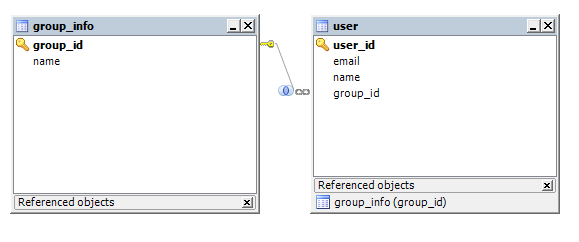
ManyToOne
위 샘플에서 사용자(User) 데이터 모델링에서, 사용자가 속한 그룹을 표한하는 테이블을 추가해보겠습니다.
여러명의 사용자는 한개의 그룹에 속할수 있기때문에, 사용자의 입장에서 다대일 입니다.
즉 사용자의 모델링에서만.., 다대일 설정을 그룹 정보와 맺어주면됩니다.
-부모의 키와 자식의 키가 다르며(전파되지 않았으며) , 자식의 테이블에서만 부모를 찾는 참조(외래)키만 있기때문에 비식별관계입니다.
SQL MODE
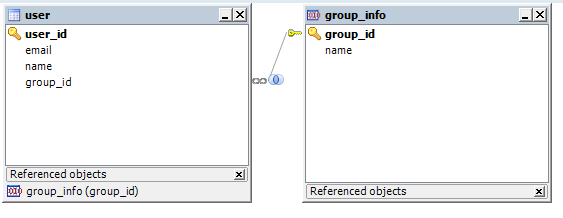

우리가 원하는 테이블 모델링은 위와같을 모습이며, user테이블에 group_id가 외래키로 설정이 되어있습니다.
어플리케이션에서 레거시한 제어를 모두한다고 하면, 이러한 외래키 설정이 필요없을수도 있으나
데이터 무결성의 입장에서 중요한 설정이며, JPA 사용시 외래키를 직접 지정하지는 않지만
Relation을 사용하면, 외래키설정이 적절한 위치에 자동으로 됩니다.
자동으로 된다고 이러한 개념을 무시하면 안되고, DB 테이블 설계시 고려되어야하는 일반적인상황을
OOP 작성시 고민해야 한다는 점입니다.
SQL문으로 표현
CREATE TABLE `group_info` ( `group_id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) COLLATE utf8_bin DEFAULT NULL, PRIMARY KEY (`group_id`) ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8 COLLATE=utf8_bin; CREATE TABLE `user` ( `user_id` int(11) NOT NULL AUTO_INCREMENT, `email` varchar(255) COLLATE utf8_bin DEFAULT NULL, `name` varchar(255) COLLATE utf8_bin DEFAULT NULL, `group_id` int(11) DEFAULT NULL, PRIMARY KEY (`user_id`), KEY `FKa36i4ekojwk70bxen390i6tek` (`group_id`), CONSTRAINT `FKa36i4ekojwk70bxen390i6tek` FOREIGN KEY (`group_id`) REFERENCES `group_info` (`group_id`) ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
JPA MODE
@Entity
public class GroupInfo {
@Id
@GeneratedValue(strategy=GenerationType.AUTO)
@Column(name = "GROUP_ID")
private Integer id;
private String name;
}
@Entity
public class User {
@Id
@GeneratedValue
@Column(name = "USER_ID")
private Integer id;
private String name;
private String email;
@ManyToOne
@JoinColumn(name = "GROUP_ID", nullable=true )
private GroupInfo groupInfo;
}
@Autowired
private GroupRepository groupRepository;
@Autowired
private UserRepository userRepository;
GroupInfo newGroup = new GroupInfo();
newGroup.setName("학생");
groupRepository.save(newGroup);
// 사용자 생성
User addUser = new User();
addUser.setName("minsu");
addUser.setEmail("test@x.com");
addUser.setGroupInfo(newGroup);
userRepository.save(addUser);
// select * from user join group_info 과 동일한 효과로, 분리된 테이블에서 그룹명을 가지고 온다.
Iterable<User> userList = userRepository.findAll();
userList.forEach(item->System.out.println( String.format("Name:%s GroupName:%s", item.getName(),item.getGroupInfo().getName() ) ));
전통적인 처리 방법은 Insert쿼리를 실행하고 다시조회쿼리를 실행하고,그 데이터셋의 결과를 어플리케이션에 가지고와서 사용하기 과정까지 각각 다른 처리코드와 변환과정이 필요했을것입니다.( 테이블을 쿼리로 설계 <-> SQL <-> DataSet <-> Object <-> Json ) Json의 뷰단의 데이터가 하나만 바뀌어도 최대 5가지 수정 포인트에서 코드 수정이 이루어 졌을것입니다.
JPA를 통한 데이터모델링 정의및 데이터제어가 다소 익숙하지않고 SQL문의 자유롭고 복잡한 표현을 모두 표현하기에 어려울수도 있습니다. 현재로서는 일괄적인 단일지점( 객체지향 정의)에서 모두 가능하다란것정도 이해를 해두고 넘어갑시다.
OneToMany
테이블구조는 변함이 없으며 접근 방식을 ManytoOne에서 OneToMany로 변경을 하여 객체지향접근방식으로
접근해보겠습니다. Group을 핸들링하고 User는 리스트처럼 사용하는것을 시도해보겠습니다.
SQL MODE
DB는 구조상, 하나의 테이블에서 서브 List형태의 데이터를 가질수가 없습니다.
각각의 테이블에서 그룹정보 / 사용자정보를 따로 입력해야하며 .. 조회시 Join을 통해
그룹정보가 사용자리스트를 가진것처럼 집합을 만들어야합니다.
-- 그룹을 추가한다. INSERT INTO test.group_info( group_id ,name ) VALUES ( NULL -- group_id - IN int(11) ,'' -- name - IN varchar(255) ) -- 사용자를 추가할시 그룹을 지정하거나, 나중에 지정한다. group id가 현재는 null 허용 INSERT INTO test.user( user_id ,email ,name ,group_id ) VALUES ( NULL -- user_id - IN int(11) ,'' -- email - IN varchar(255) ,'' -- name - IN varchar(255) ,0 -- group_id - IN int(11) ) -- 여러명을 등록할시 위 과정이 반복됩니다. --학생인 사용자만 조회시..Join을 통해 해결 select * from user left outter join group_info gi on gi.name='학생'
JPA MODE
JPA에서의 목적은, 기존 SQL에서 처리하는 방식을 객체지향적으로 변경하는것입니다.
그리고 Join사용에 있어서 기존 테이블의 관계(외래키관계)를 잘 설계해야한다는것입니다.
Join에서 해방되고, 외래키 설정같은것을 신경쓸필요가 없어보이나
JPA를 활용한 코드가, 외래키 설정도 실제 되고, Join SQL문이
FindByname 내에 내재되어 작동이 된다라는 사실입니다.
각종 Join(InnerJoin,LeftOutterJoin,Right....)에 대응하는 JPA Relation 키워드기능을 잘 파악해둬야합니다.
이 샘플의 JPA함수 호출이 왜? left outer join을 자동적으로 선택하여 호출하게 되었는지
살펴볼 필요가 있습니다.
public class User {/...
@ManyToOne
@JoinColumn(name = "GROUP_ID", nullable=true )
private GroupInfo groupInfo;회원이 가지는 외래키로(ManyToOne) 설정된 그룹ID가 null을 허용하고 있기때문입니다.
이 의미는, InnerJoin을 사용할경우 그룹에 소속되지 않는 사용자가 있을수 있기때문에
사용자 데이터도 조회할수 없음을 의미합니다.
InnerJoin이 성능과 최적화에 더 유리하며, 만약 InnerJoin으로 작동 시키고 싶으면
nuuable=false 필수값으로 지정하게 되면, JPA에서는 User<->Group 양방향 객체참조시
그룹을 꼭가진 필수관계이기 때문에, 외부조인대신 내부조인을 선택하게 됩니다.
JPA에서 연관관계/매핑부분은 가장중요한 부분이라 생각되며, 관련된 데이터 베이스
지식을 다시 공부해야할 필요도 있습니다.
SQL Join의 자유로운 표현력에 비해 ,JPA는 분명 제약적입니다.
객체 지향적 설계가 어떠한 Join문을 실제 작동시키게될지? 성능적으로 어떠한 전략을 택해야할지?
오브젝트 설계시 고려가 되지 못하면, Join 기능을 사용조차 할수없는 답답함이 생길수도 있습니다.
이것을 장점으로 받아들일지? 단점으로 생각해야할지? JPA를 선택하는 중요한 사안이될수 있습니다.
@Entity
public class GroupInfo {
@OneToMany(mappedBy = "groupInfo", cascade = {CascadeType.PERSIST},fetch=FetchType.EAGER)
private Set<User> users;
@Override
public String toString() {
String result = String.format(
"GroupInfo[id=%d, name='%s']%n",
id, name);
if (users != null) {
for(User user : users) {
result += String.format(
"User[id=%d, name='%s']%n",
user.getId(), user.getName());
}
}
return result;
}
}
public interface GroupRepository extends CrudRepository<GroupInfo, Long> {
public GroupInfo findByName(String name);
}
- cascade : 속성값에는 CascadeType라는 enum에 정의 되어 있으며 enum값에는 ALL, PERSIST, MERGE, REMOVE, REFRESH, DETACH가 있습니다.
- targetEntity : 관계를 맺을 Entity Class를 정의합니다.
- fetch : FetchType.EAGER, FetchType.LAZY로 전략을 변경 할 수 있습니다. 두 전략의 차이점은 EAGER인 경우 관계된 Entity의 정보를 미리 읽어오는 것이고 LAZY는 실제로 요청하는 순간 가져오는겁니다.
- mappedBy : 양방향 관계 설정시 관계의 주체가 되는 쪽에서 정의합니다.
- orphanRemoval : 관계 Entity에서 변경이 일어난 경우 DB 변경을 같이 할지 결정합니다. cascade와 다른것은 cascade는 JPA 레이어 수준이고 이것은 DB레이어에서 처리합니다. 기본은 false입니다.
GroupInfo newGroupA = new GroupInfo("학생");
Set usersA = new HashSet<User>() {{
add(new User("minsu2","min2@x.com",newGroupA));
add(new User("minsu3","min3@x.com",newGroupA));
}};
newGroupA.setUsers(usersA);
GroupInfo newGroupB = new GroupInfo("선생");
Set usersB = new HashSet<User>() {{
add(new User("tom1","tom1@x.com",newGroupB));
add(new User("tom2","tom2@x.com",newGroupB));
}};
newGroupB.setUsers(usersB);
groupRepository.save(new HashSet<GroupInfo>() {{
add(newGroupA);
add(newGroupB);
}});
GroupInfo groupInfo = groupRepository.findByName("학생");
System.out.println( String.format("학생정보: %s", groupInfo.toString() ) );
위 테스트 코드는, 각각의 그룹을 생성을 하고 사용자까지 Group에 포함하여 저장하는 방식을
사용하였습니다. 전형적인 객체 지향적인 접근 방식이며
최종 save명령을 통해, 실질적인 저장쿼리가 순차적으로 모두 반영을 할것입니다.
또한 마지막에는, 그룹명을 통해 학생리스트를 조회하는 명령을 조인을통한 테이블 집합변경
없이 수행하였습니다. ( 물론 , 실제 이 조회명령을 수행하기위해 Join문이 작동됩니다.)
Paging 처리
JPA MODE
public interface UserPageRepo extends Repository<User, Long>{
Optional<User> findOne(Long id);
// 전체 페이징처리
Page<User> findAll(Pageable pageRequest);
// 검색 확장-그룹명으로 페이지 필터
Page<User> findByGroupInfoName(String groupName,Pageable pageRequest);
// Update
void delete(User deleted);
User save(User persisted);
void flush();
}
SQL문 쿼리없이, 검색조건/필터조건등을 지정하여 페이징 처리가 가능합니다.
JPA에서는 가변적인 함수처리로, SQL문의 페이징처리가 고려된 복합 검색 연산조합처리 모두가능합니다.
- JPA함수 : findBy{필드명A}OrfindBy{필드명B}AndfindBy{필드명C}(....인자값);
- SQL문 : where 필드명A=인자값A or 필드명B=인자값B and 필드명C
더자세한정보는 아래문서를 참고합니다.:
UseCase
//Test를 위해 100개의 데이터 인입
GroupInfo newGroupA = new GroupInfo("학생");
Set usersA = new HashSet<User>() {{
for(int i=0; i<100 ; i++) {
String userName = String.format("minsu%d", i);
String email = String.format("min%d@x.com", i);
add(new User(userName,email,newGroupA));
}
}};
newGroupA.setUsers(usersA);
groupRepository.save(new HashSet<GroupInfo>() {{
add(newGroupA);
}});
//원하는 페이지를 조회합니다.( 페이지번호 , 페이지당 처리수)
PageRequest pageRequest = new PageRequest(1,10);
Page<User> sPage = userPageRepo.findAll(pageRequest);
System.out.println( String.format(" %d:Contents %d:Page", sPage.getNumberOfElements(),sPage.getNumber() ) );
Page<User> sPage2 = userPageRepo.findByGroupInfoName("학생", pageRequest);
System.out.println( String.format(" %d:Contents %d:Page", sPage2.getNumberOfElements(),sPage2.getNumber() ) );
페이지와 소팅 동시처리
pageRequest = new PageRequest(0,10, Sort.Direction.DESC , "a","b","c" ); pageRequest = new PageRequest(0,10, Sort.Direction.DESC , "a",Sort.Direction.ASC,"b" );
다중 소팅
Sort.Direction sortDir = Sort.Direction.DESC;
if( sortdir.equals("asc") ) sortDir = Sort.Direction.ASC;
Sort sortOpt = new Sort( sortDir, sort )
.and( new Sort(Sort.Direction.DESC, "customervaluation") );
JPQL MODE
public interface UserPageRepo extends Repository<User, Long>{
// QueryMode
@Query(value="select t from User t "
+ "where t.name =:name "
+ "order by t.id " , nativeQuery=false )
List<User> findBySomeName( @Param("name") String name, Pageable pageable);
}
JPA의 함수처리방식이 익숙하지 않다면, SQL방식으로 인터페이스 작성도 가능합니다.
함수의 인자가, SQL문의 인자로 전달하는 방식의 패턴을 파악한후, 기존 SQL문 활용이 가능합니다.
JPQL VS SQL(Native)
JPQL은 JPA와 연동되어 일반적으로 대부분의 DB에 호환이되는 다소 제약적인 쿼리사용이 가능합니다.
JPQL의 공통된 인터페이스, 예를 들면 데이터를 나뉘는 파티션 인터페이스인 페이징처리를
각 DB에 맞게끔 모두 처리가가능합니다.
이와 반대로 SQL(Native) 모드로 사용도가능하며, DB변경시 호환이 깨질수 있습니다.
예를 들어 페이징을 위해 Mysql에만 있는 페이징처리를 위해 Limit기능을 사용할수 있지만
DB변경시 관련 SQL문을 지원하지 않는다면, 작동하지 않을것입니다.
nativeQuery , true/flase에따라 작동방식이 변경가능하며 , 특수한 경우가 아니면
JPQL사용이 권장됩니다.
다른 유용한 사이트:
JPA 개념 설명 : http://blog.woniper.net/255
다른 진영(.net) 에서도 JPA와 유사한 스펙을 가지고 있습니다.
Entity Framework : https://docs.microsoft.com/en-us/ef/core/
NHibernate : https://en.wikipedia.org/wiki/NHibernate /
서로의 어플리케이션진영에서 데이터베이스를 어떻게 다룰것인가?
에대한 고민이 비슷해 보이며 서로에게 영향을 주면서 계속 발전중인듯보입니다.
마치 웹에서 MVC패턴 적용이 진영간 표준화 된것처럼
데이터베이스를 다루는 기술도 표준화를 이끌어내기를 기대해봅니다.
진영간 유사한 스펙에 다른 기술적 차이
| JAVA(JPA) | .NET(EntityFrame) | |
|---|---|---|
| 모델정의 | Entity-클래스 | 클래스 |
| Persitent 저장소명 | Repository | DbContext |
| 쿼리툴 | QueryDSL | Linq |