
AKKA를 간단하게 소개하면 고성능 병렬 처리, 우수한 오류 처리와 복구, 확장성, 그리고 분산 시스템을 쉽게 구축할 수 있는 기능을 제공하는 툴킷이라고 소개를 합니다.
이미 선택한 프레임워크 내에서 툴킷(라이브러리) 형태로 이용가능합니다.
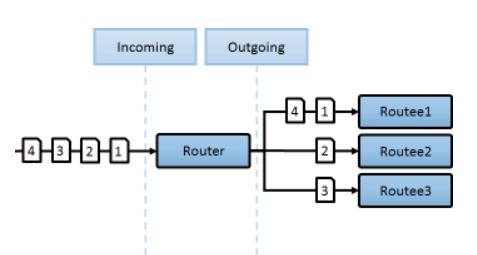
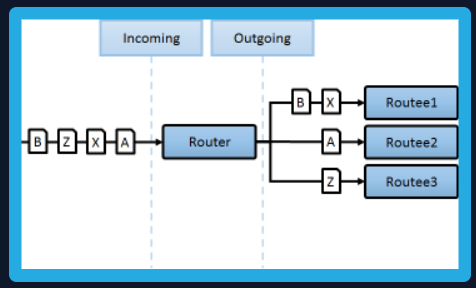
액터모델을 이해하기 위해 먼저 오늘날의 메시징큐시스템이 대부분 채택하고 있는 메일박스를 먼저 살펴보겠습니다.

첫번째 그림은 액터모델이 가진 MailBox이며 두번쨰는 Kafka가 가진 파티션별로 작동하는 MailBox입니다.
오늘날의 메시징기반 프로그래밍은 메일박스와 같은 큐를 적극채택합니다.

메일박스는 메시지가 발생하면 메일박스에 모아둡니다. 그리고 필요할때 그것을 꺼내어 사용을 하는 아주 단순한 아이디어입니다.
오늘날의 메시징 플랫폼이 대부분 채택하고 있는 이러한 메일박스에 대한 개념은 1986년 통신사인 에릭슨이 도입한 언랭이 크게 성공하였으며
AKKA를 포함 메시징 플랫폼에 많은 영향을 주었습니다.
Erlang의 액터 모델에서 "메일박스"는 중요한 개념입니다. Erlang에서 각 액터(여기서는 프로세스라고 부릅니다)는 독립적인 실행 단위로, 메시지를 통해 서로 통신합니다. 메일박스는 이러한 메시지 통신에서 중심적인 역할을 합니다. Erlang의 메일박스에 대한 설명:
메일박스는 Erlang의 프로세스 간 통신의 핵심으로, 시스템의 동시성과 병렬성, 그리고 오류 복구 능력을 강화합니다. 이러한 특징은 Erlang을 분산 시스템, 텔레커뮤니케이션, 실시간 서버 백엔드 개발에 매우 적합하게 만듭니다. |
액터모델은 전혀 새로운것이 아닌 메일박스와 같은 큐를 이용하는 작동하는 모델입니다. 디자인 패턴에서는 액티브 오브젝트 패턴에 분류됩니다.
AKKA는 Alpakka(https://doc.akka.io/docs/alpakka/current/index.html) 와 같은 서브 프로젝트를 통해 Kafka와 같이 주변 오픈스택과 스트림으로 연동하는 방향으로 발전해왔습니다.
주변스택을 약속된 인터페이스로 잘 활용하는 활동은 Reactive Stream의 활동중 일부이며 특정 기업이 주도하는 구현체라기보다 다양한 오픈스택을 가진 기업이 인터페이스를 준수하며 자발적으로 참여하고 있으며 크게 성공한 활동입니다.

Akka가 제공하는 기능을 조합하여 Kafka와 유사한 스택을 만드는것이 그렇게 어렵지는 않겠지만 Kafka를 대체하는 기술 스택은 아니며,
Akka는 Kafka를 잘 이해하고 있기때문에 그냥 사용하는것보다 높은 수준의 추상화통해 주변 스택을 잘 이용하는것을 학습할수 있습니다.


카프카가 생성한 이벤트를 소비하는쪽에서 블록킹 또는 배치처리가 아닌 동일한 메일박스에 흘려보냄으로 토픽이 액터와 연결되어
복잡한 도메인에대한 유연한 동시성 처리를 할수 있습니다.
카프카와 같이 메일박스(토픽)를 동일한 메일박스에 연결하여 처리하는 아이디어는 심플하지만 강력할수 있습니다.
예를 들어 불특정 하게 발생하는 이벤트를 일정기간 로컬액터에 보유해 정크를 처리하는 것은 DB적재 성능을 크게 향상시킬수 있습니다.
카프카의 중요 주제인 생산/소비자를 만드는것을 포함 AtLeastOnce Delivery / Transaction 등 고급주제도 함께 다루게됩니다.
메시지 전송보장을 하기 위해 어떠한 수준을 채택할것인가? 라는주제는 메시징을 다루는 시스템에서 이제는 공통주제가 되었습니다.
고성능 처리를 위해 오늘날의 프로그래밍은 동시성 또는 병렬성 프로그래밍을 채택하게 됩니다.
AKKA에서는 이 두가지 요소를 어떻게 조화롭게 사용하는지 살펴보겠습니다.
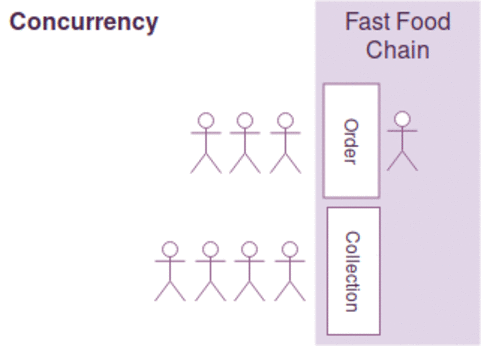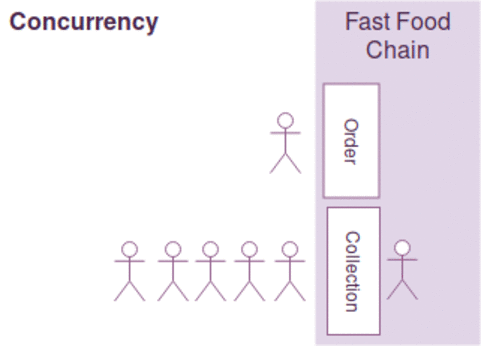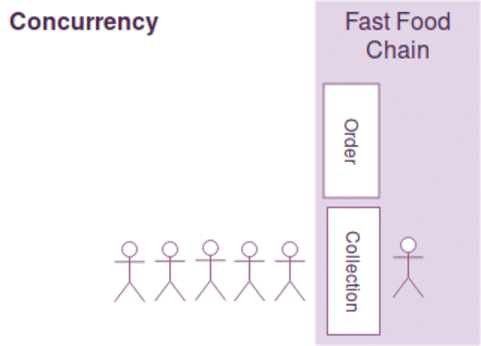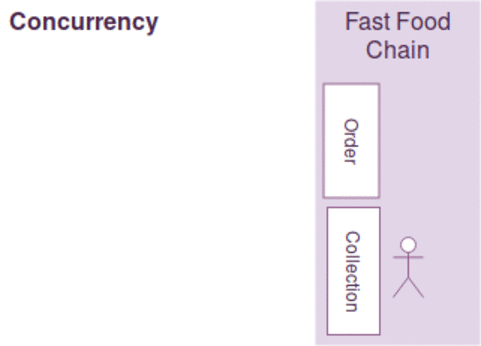
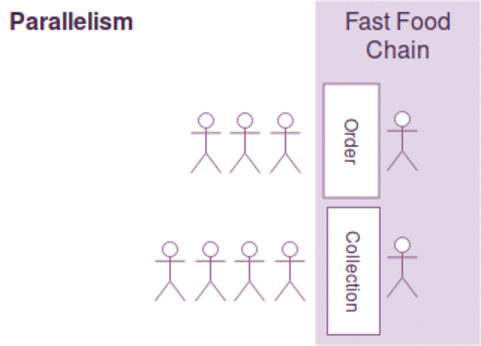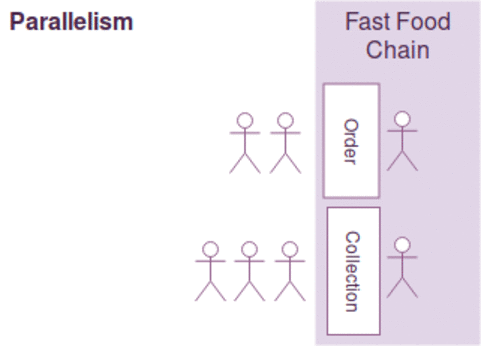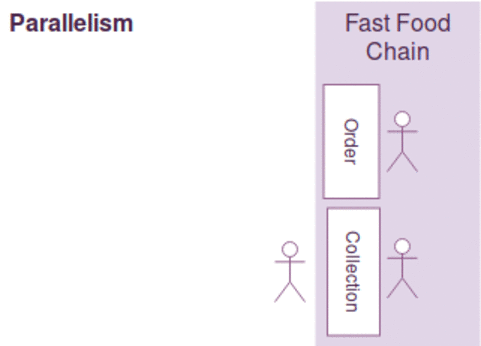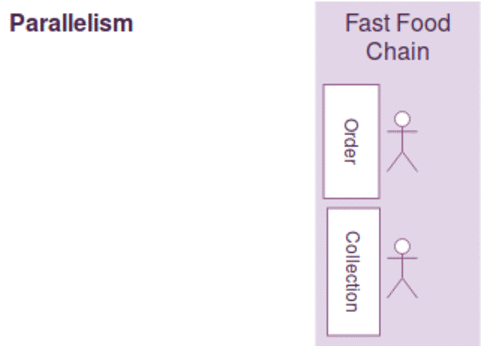
동시성과 병렬성은 약간의 차이가 있지만, 다음과 같이 간략하게 설명될수 있습니다.
AKKA는 언어가가진 혹은 채택한 비동기 프로그래밍을 먼저 설명합니다.
즉 기본기에 대한 가이드에서 시작합니다.
자바와 .NET에서 비동기 프로그래밍을 구현하는 방식은 기본적인 철학과 구현 메커니즘에서 차이가 있습니다. 자바의 비동기 프로그래밍
.NET의 비동기 프로그래밍
주요 차이점
|
AKKA가 자바와/닷넷에서 각각 채택한 비동기 스택
AKKA는 Scala에 도입된 Future/Promice 이용하고 닷넷환경에서는 asynce/await를 활용합니다.
CompletableFuture 가 없던 자바7은 Scala(Akka)의 영향을 받아 비동기기능이 지원이 되었습니다.
또한 Java9에서는 Akka Stream기능의 영향을 받아 StreamAPI가 추가가되었습니다.
이제 AKKA없이 기본언어 스펙에 Stream API를 지원하게 되었습니다.
닷넷진영은 이미 오래전 stream api와 같은 역할을 하는 linq가 있었기때문에 핫한 주제는 아닙니다.
기본언어의 비동기함수및 / Stream API에 대한 사용 숙련도가 낮은상태에서 AkksStream 또는 액터모델 채택을 권장하지 않습니다.
AKKA는 언어스펙이 가진 모든 비동기처리 기술스펙을 활용하기 때문입니다. ( 기본기는 항상 중요합니다. )
기본기를 통해 복잡한 문제를 충분히 잘 해결할수 있다라면~ AKKA와 같은 툴킷이 필요없을지도 모릅니다.
자바와 닷넷의 경우 추가적으로 Rx.net/Rx.net/WebPlux등 강력한 비동기 처리 모듈을 추가로 이용할수도 있습니다.
이것은 AKKA에 1:1로 대응되는 스택이 아니라, AkkaStream API에 대응되는 스택범위입니다.
이렇듯 각 언어가 가지고 있는 기본기를 건너띄고 AKKA를 도입해 고성능 어플리케이션을 작성한다란것은 있을수 없는일입니다.
AKKA(Akka.net)의 문서는 이러한 기본 이론을 먼저 알려주고 시작하며 단순하게 동시성 처리를 대체하는 툴킷이 아니며
액터모델을 중심에두고 이벤트 기반의 개발에서 발생할수 있는 다양한 문제에 해결에대한 패턴과 샘플을 제공합니다.
AKKA에서는 단일장비내에서 병렬처리를 어떻게 다루는지 살펴보겠습니다.
병렬프로그래밍AKKA의 단일액터만 사용하는 경우 단순하게 비동기처리 프로그래밍로 보여질수 있지만.
라우팅기법을 이용하며 병렬처리의 경우 멀티스레드 프로그래밍을 하지 않지만 프레임워크 또는 언어가 가진 스레드를 이해하고 활용합니다.
기존 언어에서 할수 있는 병렬처리 방법을 적극 채택 합니다.
단일 액터는 순차성을 보장하며 여러개를 생성하여 구성하면 동시적또는 병령적으로 작동가능합니다.
추가로 스레드활용 전략인 Dispatcher를 선택할수 있으며 이것은 설정화로도 분리됨으로 튜닝의 전략에 이용할수 있으며
스레드전략에 따라 동시성이 아닌 병렬성처리로 작동될수 있습니다.
default-fork-join-dispatcher {
type = ForkJoinDispatcher
throughput = 30
dedicated-thread-pool {
thread-count = 3
deadlock-timeout = 3s
threadtype = background
}
}
akka.remote.default-remote-dispatcher {
type = Dispatcher
executor = channel-executor
fork-join-executor {
parallelism-min = 2
parallelism-factor = 0.5
parallelism-max = 16
}
} |
닷넷에서는 병렬처리 프로그래밍인 TPL(https://learn.microsoft.com/ko-kr/dotnet/standard/parallel-programming/task-parallel-library-tpl)을
기본 처리기로 활용합니다. 스레드를 다루는 종류로 ForkJoin 또는 ThreadPool을 선택할수 있습니다.자바및 닷넷에따라 이용되는 모듈이 다를수도 있으며 커스텀화된 스레드모델을 생성하여 지정할수도 있습니다.이 부분은 AKKA의 전박전인 장점으로 Netty와같은 고성능 TCP모듈 / 고성능 JSON등,프로토콜버퍼 등 활용 모듈 교체가 가능합니다.비동기 프로그래밍과 병렬처리 프로그래밍은 비슷하면서도 다른분야이며 AKKA에서도 이것을 이해하고 분리하여 전략적으로 이용할수 있습니다.
프로그래밍 방식에 일반적으로 블락킹이 없다고 하면 신경쓸 필요가 없지만, 블락킹처리를 하는 액터와 아닌 액터를 논리적으로 구성하여
각각 다른 스레드 모델로 작동지정이 가능하며 처리 스레드 영역을 분리할수 있습니다.
모던한 프로그래밍에 의해 비동기로 모두 작성되면 좋겠지만 블락킹(동기) 코드가 함께 작동될때 성능튜닝 장치를 제공해줍니다.
AKKA를 통해 고성능 어플리케이션을 작성하기 위해서 다음과 같이 기본 언어가 제공해주는 스레드 모델역시 학습해야 합니다.
기본 언어가 가진 병렬처리 기능을 채택하고 활용할수 있기때문입니다.
동시성 비동기에 최적화된 Node.js나 코루틴의 경우 단일 스레드로 동시성처리에대한 효율을 가질수 있습니다.
하지만 단 하나라도 블락이되는 코드가 포함되어 있으면 전체가 일시정지 하기 쉽상입니다.
이러한 비동기 동시적 프로그래밍은 함수형을 이용한 선형이아닌 선언형 프로그래밍과 콜백처리를 잘 다뤄야합니다.
스레드를 잘 다루거나? 함수형 프로그래밍으로 동시성을 잘 다루거나? 둘중에 하나의 선택지가 있습니다.
AKKA에서는 액터/Stream/dispacher을 도입해 함께 다룹니다. 다만 왜 유명한 메시징 기업들이 대부분 액터모델을 채택했는지?
메시빙 분산처리를 고민하는 개발자라고 하면 학습해 볼 필요가 있는 주제 인것으로 보여집니다.
액터 모델을 도입해 성공한 몇몇 기업들을 살펴보겠습니다. 액터 모델은 동시성과 병렬 처리를 다루는 데 특히 유용한 프로그래밍 패러다임입니다. 여기에는 대규모 분산 시스템과 복잡한 동시성을 관리해야 하는 애플리케이션을 개발하는 기업들이 포함됩니다.
이러한 기업들은 액터 모델을 도입함으로써 시스템의 확장성, 안정성 및 동시성 처리 능력을 크게 향상시킬 수 있었습니다. 특히, 대규모 분산 시스템과 높은 사용자 트래픽을 관리해야 하는 상황에서 액터 모델의 장점이 두드러지게 나타났습니다. |
이제 동시성과 병렬처리문제를 따로가 아닌 문제의 공간에 함께두고 해결하는 방법에대해 이야기 해보겠습니다.

데모앱 : http://code.webnori.com/actor/broadcast
필자가 만든 액터모델을 작동시키고 시각화하고 설명을 하는 데모 프로젝트입니다.
( 앱이 중단될때까지 임시 운영예정입니다 .)
액터모델은 논리적인 구성이 가능하며 분배기를 채택하고 연결된 작업 Node의 이벤트를 처리할 Thread 수를 지정할수가 있습니다.
단일 장비에서 최적화된 스레드모델과 비교 하면 성능이 떨어질수도 있지만 분산처리를 할수 있는 장점이 있습니다.
블락킹 코드가 하나라도 있는경우 비동기 방식을 사용하지 말라는 제약을 본적이 있을것입니다. 액터모델에서도 긴시간 블락킹코드 사용은 권장하지 않지만 이것이 액터모델를 느리게 만드는 큰 제약은 아닙니다.
다음은 액터모델의 구현방법에 대해 언어별로 간단하게 알아 보겠습니다.
public class HelloWorldActor extends AbstractActor {
@Override
public Receive createReceive() {
return receiveBuilder()
.matchEquals("sayHello", s -> {
log.info("Hello World");
})
.build();
}
} |
public class HelloWorldActor : ReceiveActor
{
public HelloWorldActor()
{
Receive<string>(message =>
{
if (message == "sayHello")
{
Console.WriteLine("Hello World");
}
});
}
} |
using Orleans;
public class HelloGrain : Grain, IHelloGrain
{
public Task<string> SayHello(string greeting)
{
return Task.FromResult($"You said: '{greeting}', I say: Hello World!");
}
} |
이벤트를 수신받고 그것을 큐에 하나씩 꺼내어 처리하는 메일박스와 같은 기능을 활용할때 액터모델을 채택해 구현 할수 있습니다.
액터모델이 아니여도 됩니다. 멀티스레드 프로그래밍을 통해 자료규조를 이용해 액티브오브젝트 패턴을 직접 작성을 하여 액터모델과 유사하게 작성할수 있습니다.
액터모델은 단순합니다. 하지만 AKKA에서 제공하는 확장은 이렇게 작성된 액터모델을 구조또는 구현코드의 큰 변경없이 다음과 같이 확장할수 있다란 점입니다.
여기서 액티브 오브젝트패턴으로 직접 작성하였고 객체간 통신을 해야하는것을 직접 구현해야 한다고 해봅시다.
적어도 다음과 같은 네트워크 프로그래밍을 해야할것입니다.
JAVA 7시절때 AKKA의 등장은 핫한 툴킷중 하나였지만 지금은 꼮 AKKA일필요는 없다라고 보여집니다. 단지 우리는 메시징 패턴중 하나인 액터모델을 하나더 알게되었습니다.
단일장비인 경우 액터모델이 스레드모델에 대비해 성능적으로 항상 이점이 있는것은 아닙니다.
함수를 직접접근하는것은 큐에 넣었다 꺼내어 처리하는 것보다 훨씬 빠릅니다.
이 성능을 극단적으로 높이기위해? C++에서 사용하는 포인트와 성능비교 하겠습니까?
이 영역에 성능을 극단적으로 높여야 하는 영역은 어셈블리를 부분할용하기도 했습니다.
기존 OOP가 잘하는것을 액터모델로 모두 변환할필요는 없으며~ 로컬에서도 큐를가진 객체가 유용한 기능일때 도입을 할수 있습니다.
액터모델은 사실상 디자인 패턴중 액티브 오브젝트 패턴에 속하며 멀티스레드에서 발생하는 다양한 문제 ( 교착/기아/자원점유)를 심플하게 해결하기 위해 등장했으며 게임서버영역인 실시간 멀티플레이어 게임에서는 오랫동안 사용한 패턴중 하나입니다.
MS의 Orlean이 그랬듯 액터모델은 게임서버 에서는 이미 익숙하게 다뤄 왔던 분야이기때문에 액터모델은 큰 이질감이 없지만
상태 없는 웹서비스에서 분산환경은 복잡성을 줄이기 위해 , 클라우드에서 제공하는 PASS를 이용하는 방향으로 발전해 왔습니다.
액티브 오브젝트(Active Object) 패턴은 소프트웨어 설계에서 사용되는 설계 패턴 중 하나입니다. 이 패턴의 주요 목적은 객체의 메서드 호출을 비동기적으로 수행하는 것입니다. 이를 통해 호출자는 메서드의 결과를 기다리지 않고 다른 작업을 계속할 수 있으며, 이는 특히 병렬 처리나 비동기 처리가 필요한 시스템에서 유용합니다. 액티브 오브젝트 패턴의 핵심 구성 요소는 다음과 같습니다:
이 패턴은 복잡한 멀티스레드 시스템을 더 쉽게 관리하고, 코드의 병렬 처리를 용이하게 하며, 시스템의 반응성을 향상시킬 수 있습니다. 그러나 설계가 복잡해지고, 성능 오버헤드가 발생할 수 있으므로, 시스템의 요구사항과 환경에 맞게 적절히 적용해야 합니다. |
분산처리를 지원하는 여러 클러스터화된 클라우드 스택을 이용하면서 분산처리와 연관된 개발은 안하지만 분산처리를 다룰수는 있습니다.
하지만 분산처리 할줄(구현) 아는 엔지니어라고 불리지 않습니다. 네 이러한것을 직접 구현할 필요는 없을수 있습니다.
AKKA에서 설명하는 이론과 샘플코드를 살펴볼수 있습니다.
그 환경을 잘 다루기 위해 적어도 클러스터를 직접 구성해보는것은 그 환경을 이해하는데 도움이 된다 입니다.
이제 자료구조 작성할 필요는 없지만 빠른 탐색이 가능한 자료구조를 만들어봄으로 자료구조를 더 잘 이용할수 있다란것을 알고 있습니다.
다음은 AKKA가 가지고 있는 기능을 카테고리화 해보았으며 일부 유용한 코드생성을 GPT를 통해 진행해보았습니다.
단순하게 여기서 다루는 주제가 AKKA가 아니라 오늘날의 분산처리 프로그래밍에서 고민해야할 메시지 패턴과 같은 모음집입니다. 디자인 패턴이 OOP프로그래밍 발전에 기여를 했다고 하면
AKKA에서 정리한 메시지 패턴은 오늘날의 분산처리 프로그래밍에 많은 영향을 주었으며 이것은 AKKA의 도입과 상관없이 학습해야할 중요한 주제입니다.

public class ReActor : ReceiveActor
{
private ILoggingAdapter log = Context.GetLogger();
public ReActor()
{
string myPath = Self.Path.ToString();
Receive<string>(message => {
Handle(message);
});
Receive<DelayReply>(message => {
Handle(message);
});
}
public void Handle(string str) //InMessage
{
Task.Run(async () =>
{
await Task.Delay(1000); //동기적함수를 호출하여 지연시키지만 액터는 멈추지 않습니다.
DelayReply reply = new DelayReply();
reply.message = str;
return reply;
}).PipeTo(Self);
}
public void Handle(DelayReply data) //Out
{
string logtrace = string.Format("I'am {0} RE:{1}", Self.Path, data.message);
log.Info(data.message);
Sender.Tell(data);
}
} |
액터에 작성된 코드는 블락킹/논블락킹 제약없이 활용할수 있습니다. 하지만 액터의 흐름을 중단하지 않기 위해서는 액터에서 작동되는 코드역시 블락없이 흘러가는것이 좋으며 결과통보는 다시 수신받을수 있습니다.
위 샘플코드는 블락킹이 포함된 것을 액터의 흐름에 방해하지 않는 언어가 가지고 있는 비동기처리를 파이프로 연결한 케이스입니다.
액터모델로 구성이되면~ 다양한 라우터를 상위에 연결시켜 분배전략을 채택할수 있습니다. 라운드로빈은 가장 알려진 분배처리방식이며
잘알려진 라우터를 추가 구현없이 이용할수 있으며 커스텀한 라우팅 모델을 만들수도 있습니다.
다음은 AKKA에서 제공되는 대표적인 라우터 종류입니다.

연결지향성(특히 웹소켓)을 단일지점 병목없는 분산처리를 다루는 경우 유용할수 있습니다.
추가 참고 링크 : 05.RouterActor

Stream영역에서는 우리의 이벤트를 과거 방식인 배치가 아닌 흐름의 연속성에서 어떻게 다뤄야할지 이론을 작동코드와 함께 설명합니다.
이 영역은 LIghtbend가 주도하는 Reactive Stream 와도 연관이 있으며 이 영역은 액터모델을 도입하지 않아도 활용할수 있는 영역으로
Rx.NET의 영향을 받아 자바진영에서는 이기종간 상호 연동을 위해 Reactive Stream 준수하는 활동으로 성공한 영역입니다.
Akka Stream역시 Reactive Stream의 일부이며 자바9에서 StreamAPI가 만들어지는데 큰 영향을 주었으며, Pivotal도 이 활동에 참여해 Webplux 를 만들었습니다.
using (var system = ActorSystem.Create("MySystem"))
{
using (var materializer = system.Materializer())
{
// 스트림 소스 정의: 여기서는 단순한 숫자 시퀀스를 사용
var source = Source.From(Enumerable.Range(1, 100));
// 스트림 싱크 정의: 여기서는 콘솔에 출력
var sink = Sink.ForEach<int>(i => Console.WriteLine($"Processed {i}"));
// Throttle을 사용하여 초당 10개 요소 처리 제한
var throttledFlow = Flow.Create<int>()
.Throttle(10, TimeSpan.FromSeconds(1), 1, ThrottleMode.Shaping);
// 스트림 파이프라인 구축 및 실행
await source.Via(throttledFlow).RunWith(sink, materializer);
}
} |
로컬환경에서 동시성/병렬성을 다루기 위해 여기까지로도 충분하지만 분산환경에서 단일지점 병목없는 상태관리를 하려면 아래 요소를 추가로 다루어야합니다. CQRS및 클러스터를 다뤄야하는 항목으로 여기서부터 난이도가 증가합니다. 이러한 주제가 클라우드 PASS를 통해 신경을 덜 쓸수도 있지만 작동하는 구현체가 존재하며 이 영역을 학습하는데 도움될수 있습니다. |

public class ShoppingCartActor : ReceivePersistentActor
{
private readonly string _cartId;
private readonly List<string> _items = new List<string>();
public ShoppingCartActor(string cartId)
{
_cartId = cartId;
Recover<ItemAdded>(evt => _items.Add(evt.ItemId));
Recover<ItemRemoved>(evt => _items.Remove(evt.ItemId));
Command<AddItem>(cmd =>
{
Persist(new ItemAdded(cmd.ItemId), evt =>
{
_items.Add(evt.ItemId);
});
});
Command<RemoveItem>(cmd =>
{
Persist(new ItemRemoved(cmd.ItemId), evt =>
{
_items.Remove(evt.ItemId);
});
});
}
public override string PersistenceId => _cartId;
} |

클러스터 구성이 없어도 메시징 처리에서 다양한 툴킷을 제공하지마녀 로컬에서 작성된 액터모델을 로직의 큰 변경없이 클러스터화 될수 있다란것은 AKKA가 가진 장점중에 하나입니다.
클러스터를 다루는 오픈스택 ( 주키퍼/몽고DB/KAFKA 등)에서 클러스터에서 왜 홀수로 구성하는것이 좋은가? 란 이야기는 많이들 들어보았을것입니다.
Akka의 클러스터에서도 이것은 중요한 공통 문제로 Split Brain Resolver ( 뇌가 분리되는 의학현상) 현상을 먼저 설명을 하고 그 전략은 단순하게 홀수로 구성하는것이아닌
다양한 해결전략을 설명하며 클러스터를 이해할수 있습니다.
이러한 내용은 클러스터를 직접개발하는것이 아닌 이용하는 엔지니어에도 도움이 될만한 주제입니다.
이러한 전략은 대부분 상호영향을 주고받았기때문에 AKKA에서 생겨난것이아니며 클러스터에서 고민하는 공통부분입니다.
단순하게 홀수자체가 방지전략이 아닌 리더선출방식과 특히 방지전략(Static Quorum)을 함께 이해해야
Sprit Brain 방지를 할수 있다라고 AKKA에서 설명을 합니다. 이 분야는 주키퍼와같이 클러스터를 이용하는 관점에서도 도움될만한 공통 내용입니다.
Akka.NET에서 Split Brain Resolver (SBR) 문제를 해결하는 것은 클러스터 환경에서 중요합니다. S
plit Brain 문제는 클러스터의 노드들이 네트워크 장애로 인해 서로 분리되었을 때 발생하며, 각 부분이 독립적인 클러스터로 작동하기
시작하는 상황을 의미합니다. 이는 데이터 불일치, 리소스 중복 사용, 클러스터 무결성 손상 등의 문제를 야기할 수 있습니다.
Akka.NET에서는 이러한 문제를 방지하기 위해 Split Brain Resolver 전략을 구현할 수 있습니다. SBR은 클러스터가 분할되었을 때
어떤 노드를 살리고 어떤 노드를 종료할지 결정하는 메커니즘입니다. Akka.NET에서는 몇 가지 전략을 제공합니다:
1. Static Quorum
원리: 클러스터의 노드 수가 특정 임계값 이상인 경우에만 생존을 허용합니다.
적용: 중요한 결정이나 작업을 처리하는 대규모 클러스터에 적합합니다.
2. Keep Majority
원리: 노드가 가장 많은 부분 클러스터를 생존시킵니다.
적용: 대부분의 노드가 동일한 데이터 센터에 위치하는 경우 유용합니다.
3. Keep Oldest
원리: 가장 오래된 노드를 포함하는 부분 클러스터를 유지합니다.
적용: 특정 노드가 중요한 역할을 할 때 적합합니다.
4. Lease Majority
원리: 외부 시스템(예: Etcd, Consul)에 '임대' 개념을 사용하여 클러스터의 생존 여부를 결정합니다.
적용: 외부 조정 시스템을 사용하는 환경에 적합합니다.
AKKA 클러스터가 지원하는 해결 전략을 선택할수 있습니다.
akka.cluster.split-brain-resolver {
active-strategy = keep-majority
}
리더 선출 과정의 단계:
1. 클러스터 멤버십 확인
클러스터 노드가 시작되면, 먼저 클러스터에 참여하기 위해 다른 노드들과 통신을 시도합니다.
각 노드는 자신의 상태(예: 조인 중, 업, 비활성화 등)를 클러스터에 알립니다.
2. 리더 선출 조건
Akka.NET 클러스터에서 리더는 항상 '업(Up)' 상태에 있는 노드 중 가장 작은 주소를 가진 노드로 자동 선출됩니다.
주소는 Akka.NET이 노드를 식별하는 데 사용하는 것으로, 일반적으로 호스트 이름과 포트 번호로 구성됩니다.
3. 리더의 역할
리더는 새로운 노드가 클러스터에 조인하는 것을 승인하거나, 노드의 상태 변경을 조정하는 등의 역할을 합니다.
예를 들어, 노드가 '조인 중(Joining)' 상태에서 '업(Up)' 상태로 전환될 때, 이를 리더가 승인합니다.
4. 리더 변경
현재 리더가 실패하거나 네트워크 분할로 인해 접근할 수 없게 되면, 클러스터는 자동으로 새로운 리더를 선출합니다.
새 리더는 '업(Up)' 상태에 있는 남은 노드들 중에서 가장 작은 주소를 가진 노드로 선택됩니다.
5. 분산된 의사 결정
리더는 중앙 집중식 조정자가 아니라 클러스터의 결정을 간소화하고 가속화하는 역할을 합니다.
모든 중요한 결정은 클러스터 멤버들 간의 합의에 의해 이루어집니다.
중요 사항
스플릿 브레인: 리더 선출 과정은 네트워크 파티셔닝 또는 스플릿 브레인 문제가 발생했을 때 더욱 복잡해질 수 있습니다.
이러한 상황에서는 클러스터의 일부가 나머지 클러스터와 분리되어 각 세그먼트가 자체 리더를 선출할 수 있습니다.
고가용성: 리더의 고가용성을 보장하기 위해, Akka.NET 클러스터는 리더가 실패하거나 분리될 경우 자동으로 새 리더를 선출하는 메커니즘을 제공합니다.
Akka.NET 클러스터의 리더 선출 과정은 클러스터의 안정성과 효율성을 보장하기 위해 중요한 역할을 합니다. 클러스터의 모든 노드는 리더의 결정을 따르며,
클러스터의 상태 변화에 따라 유연하게 대응합니다.
Akka 클러스터에서 홀수 노드 구성은 실제로 Split Brain 상황을 방지하는 데 도움이 될 수 있습니다. 이는 특히 퀴럼 기반의 전략을 사용할 때 중요합니다.
홀수 노드 구성의 이점:
명확한 다수결 형성: 홀수 노드를 사용하면, 클러스터의 한 부분이 다른 부분보다 명확하게 더 많은 노드를 가질 확률이 높아집니다.
이것은 클러스터가 네트워크 분할 상황에서 어느 쪽 부분을 유지할지 결정하는 데 도움이 됩니다.
퀴럼 결정의 용이성: 퀴럼 기반 전략에서는 클러스터의 전체 노드 중 과반수 이상이 동의해야 결정이 내려집니다.홀수 노드 구성은
퀴럼이 명확하게 형성되도록 하여, 결정을 내리는 데 필요한 노드 수를 명확히 합니다.
스플릿 브레인 방지: 네트워크 파티셔닝이 발생했을 때, 홀수 노드 구성은 한 쪽 세그먼트가 명확한 다수를 형성할 가능성을 높여,스플릿 브레인 상황의 발생 가능성을 감소시킵니다.
주의할 점:
항상 완벽하지는 않음: 홀수 노드 구성이 스플릿 브레인을 완전히 방지할 수는 없습니다. 네트워크의 복잡한 분할 상황에서는 여전히 스플릿 브레인이 발생할 수 있습니다.
추가적인 메커니즘 필요: 홀수 노드 구성은 스플릿 브레인 방지 전략의 일부일 뿐입니다.Akka 클러스터는 Split Brain Resolver 같은 추가적인 메커니즘을 사용하여 네트워크 분할 상황을 더욱 효과적으로 관리해야 합니다.
홀수 노드 구성은 클러스터 안정성을 향상시키는 한 방법이지만, 클러스터의 전체적인 안정성과 운영을 위해서는 다양한 전략과 메커니즘을 종합적으로 고려해야 합니다. |
자신이 이미 만든 어플리케이션을 AKKA가 제공하는 간단한 설정추가로 클러스터화 할수 있습니다. 클러스터환경을 단순하게 이용만 하는것이 아닌 클러스터를 설계할수 있는 장난감이 생겼습니다.
샘플은 닷넷어플리케이션이며 자바도 동일컨셉으로 적용할수 있습니다.
클러스터화가 각 어플리케이션은 액터모델의 이벤트 전송이 리모트로 가능해지며 어플리케이션간 가장 빠른 실시간성 메시지를 이용할수 있습니다.
A → B 어플리케이션의 이벤트 전송이 가장빠른 TCP모듈을 채택하여 0.1 초 이내에 또는 1초이내에 수만이상의 이벤트전송이 가능합니다.


AKKA에서는 도메인 주도설계의 구현에 해당하는 CQRS파트를 간단하게 구현할수 있는 툴을 지원하며
DDD의 3인방중 한명인 반 버논이 AKKA의 액터모델을 이용해 자바로 구현된 DDD 구현체를 소개하였습니다.
( DDD구현은 닷넷이 시초이며~ 닷넷진영관 협업함 )

액티브 오브젝트 패턴이자 액터모델은 그 개념이 OOP와 함께 등장했을정도로 오래되었으며
인기있고 대중적인 것은 분명아닙니다. 하지만 이벤트를 분산처리하는 메시징 영역에서는 분명 액터모델로인해 발생한 메시지패턴은 충분히 학습할만한 가치가 있고
다양한 분산처리 프레임워크에 영향을 주었습니다.
가령 비동기 처리방식에서 async/await는 닷넷에 있고 CompletableFuture 는 자바에 있습니다. 또한 닷넷진영의 rx.net 과 자바진영의 webplux 또한 유사하지만 다릅니다.
자바와 닷넷의 분산처리 능력을 균형있게 다뤄야 하는 관점에서 액터모델을 함께 도입했다고 하면 동시성/병렬처리를 통한 고성능 문제를
언어상관없이 액터모델을 통해 동일한 해결방법을 생각하고 유사하게 구현할수 있습니다.
액터모델은 전혀 새로운것이 아니라~ 메시징 이벤트 영역에서 오랜동안 활용된 개발패턴이며
실시간 메시지를 잘 다뤄야하는 게임영역 그리고 전세계 사용자를 커버하는 메시징영역 그리고 Kafka의 내부에서도 이러한 패턴을 채택했을까? 고민을 해보면
분명 액터모델은 모든것을 해결할수는 없겠지만 , 하나의 장치로 학습할필요는 있으며
AKKA의 액터모델은 적어도 JVM/CLR 환경에서 분산처리 시스템을 직접 작성해보고 연습해볼수 있는 충분히 좋은 과학상자와 같은 툴킷이며
AKKA를 통해 기본언어가 가진 비동기처리와 병렬처리를 오히려 배울수 있었으며고성능 분산처리 메시징에 관심이 있는 개발자라 라고한다면 AKKA가 아니여도 되지만, 학습해볼만한 가치는 있다라고 마무리를 해봅니다.
추가 참고링크