Akka에서의 분산처리 클러스터의 최종 목표는, 외부 클러스터 시스템을 이용만 하는것이 아닌
단일지점 병목지점이 없는 확장가능한 시스템을 직접 구현하는것입니다.
외부 시스템을 그냥 사용하는것이 때로는 효율적일수 있지만, 직접 구현해보는것은 클러스터 시스템을 이용하는데 있어서 도움이 될것입니다.
클러스터 분산처리

클러스터는 여러 대의 컴퓨터들이 연결되어 하나의 시스템처럼 동작하는 컴퓨터들의 집합을 말하며
LightHouse(등대)는 클러스터내에 서버 발견(Discovery)과 가입/탈퇴를 관리하는 역활을 하며,
여러대의 컴퓨터를, 하나로 묶기위해 필요한 요소중 하나이며 아파치에서 주키퍼와 그역활이 유사합니다.
Rancher(목장관리),주키퍼(동물원사육사)등 클러스터시스템들은
유일하게 위치 투명성있는 관리 시드 노드가 항상 존재하며,재미있는 네이밍이 붙어있습니다.
Akka.net에서는 이하 등대로 표현하겠습니다.
git : https://github.com/psmon/AkkaForNetCore/tree/master/LightHouse
클러스터 OverView

Gossip Protocol
단일지점 병목을 없애기위해 피어투 프로토콜을 이용하며, 각노드는 빠르게 특정대상(정확히는 구성된 라우터)에게 이야기할수 있으며
설정없이 서로의 존재를 알기위해 잡담(Gossip) 방식을 사용합니다.
- 최초 Node1을 뛰운다.
- A1 : Node1은 인스턴스를 뛰우고 난후, 등대 에게 자신의 존재를 알린다.
- Node2를 뛰운다
- A2 : 노드2는 인스턴스를 뛰우고 난후, 등대에게 자신의 존재를 알린다.
- A1 : 등대는 Node1에게 Node2의 존재를 알린다.
- B1 : Node1은 Node2에게 인사를 하여 서로 연결을 맺어둔다.
- A2 : 연결이 완료되었음을 등대에게 알린다.
- Node3를 뛰운다.
- 동일과정 : A3 → (A1,A2) → (B3,B2) → A3
- Node1이 탈퇴(Down)한다.
- A1 : Node1이 등대에게 탈퇴를 알린다. ( 비정상 종료시에는 등대가 Node1이 사라짐을 파악후 제거진행)
- A3,A2 : 등대가 Node1의 탈퇴 사실을 알린다.
- B3,B1 : Node1과의 연결을 제거한다.
위 작동방법이 복잡한것처럼 보이지만, 설정변경없이 노드를 유연하게 확장할때 장점이있으며
피어투피어 네트워크는 다음과 같이 리얼 세계와 연관을 시키면 이해가 쉽습니다.
- 작업공간은 새로 참여할수도 있고, 중간에 나갈수도 있다.
- 새로운 역활의 담당자(노드)가 공간에 참여하면, 모든 구성원과 명함을 주고 받는다.
- 모든 전문가는 각각의 역활을 알고있기때문에, 직접 대화가가능하며, 동일한 역활의 담당자가 추가되면 그룹구성을한다.
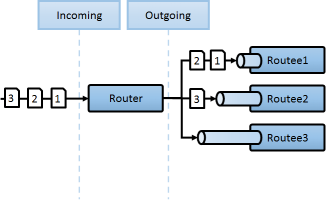
기존 설계된 로컬 액터에 클러스터 룰 셋팅만하고, 라우팅 전략역시 설정만으로 분산처리를 설계할수 있습니다.
라운드 로빈만이 유일한 라우팅으로 알고 있다고 하면, AKKA에서는 다음과 같은 라우팅을 클러스터에서 사용할수 있습니다.
분산 처리의 세계에서는 구현된 로컬 로직 변경을 최소화하고 다양한 라우팅을 사용할수 있습니다.
성능관련 스케일 아웃은 라우팅 전략과 관련이 있고
운영중 장비를 Down없이 스케일 늘리고 줄일수 있는 전략은 클러스터링과 연관이 있다고 볼수 잇습니다.
기술적으로 AKKA내에서 클러스터는 목표는 병목 현상이 없는 탄력적인 분산형 피어 투 피어 네트워크라고 정의 내릴수 있습니다.
AKKA에서는 다양한 라우팅 전략을 디플로이 환경설정 전략으로 최소의 코드변경만으로 적용가능합니다.
또한 이러한 전략을 적용하기 위해 운영중 장비를 Down없이 다이나믹하게 스케일아웃할수있는
클러스터로 개념으로 확장 가능합니다. AKKA의 라우팅전략은 코드설계가아닌, 설정화로 이루어내니
지원가능한 대표적인 라우팅을 설명합니다. ( 라이브러리 내에서는 지속적으로 새로운 라우팅 모델이 업데이트중에 있습니다.)
- AKKA가 아니여도 이러한 라우팅 분산처리는 IT에서 이미 활용하고 있는 컨셉입니다.
RoundRobin
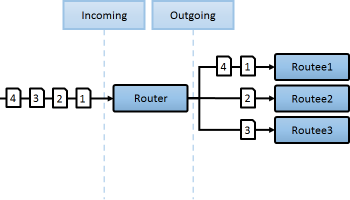
단순하게 들어온 메시지 순서대로, 순차적으로 대상 노드를 바꿔가며 전송시 사용
ex>단순한 RestAPI의 성능향상및 특정 노드 장애에 대응하는 다중화구성 ( 기본적으로 Pool에 등록된 Node Crash발생시 해당노드는 해당풀에서 자동제거됨)
Broadcast
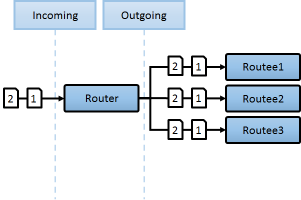
어떠한 정보의 변경을 모든 노드가 알아야할시, 주로 전체 동기화및 전체 푸시용도
ConsistentHashing
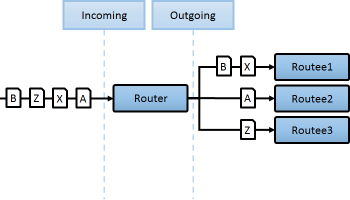
특정 처리에 대해 해시값기반 베이스로 노드의 변경의 가능성을 최소화할때
ex>
- 웹소켓 기능 보장 ( 핸드쉐이크과정에서 노드변경이되면 오동작)
- 자체캐쉬 작동 보장(성능을 위해 노드 자체에 서버 캐시처리를 하였지만, 노드변경시 서버캐시 적용못받음)
- 최초 설계에의한 제한적 분산(기능적으로 생성한 오브젝트가 예상되는 특정 노드에 있어야하는 경우등)
- SSL및 서비스 로그인 세션유지 ( 노드변경시 재인증을 받아야하는 성능이슈 )
- X에 해당하는 고객(또는 몰)의 외부적인 요소에의해 API 호출제약이 n이라고 가정하면 단순하게 분산처리가 되어버리면 TPS제어를 할수 없습니다. 클러스터내에 하우터가 조장되면 분산이 재조정되기 때문에 특정 컨디션의 데이터를 특정노드에 실행이 보장되면 단일노드 환경에서 원격캐싱이아닌 수백배 빠른 로컬캐시를 활용할수도 있으며 호출 제약또한 리모트가 아닌 인메모리 기능으로 심플하게 구현할수 있습니다.
- Redis에대한 오해 : Redis가 Key/Value여서 RDB를 사용하는것보다 빠른 캐시개념으로 접근할수 있지만... 원격 접근이라는 네트워크 전달 비용이 있습니다. 인 메모리전략은 수백배/수천배 빠를수 있습니다. 로컬캐싱을 이용할수 있습니다.
ScatterGatherFirstCompleted
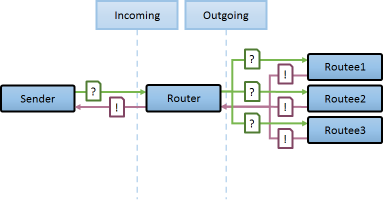
성능을 위해 다중노드로 구성하였으며, 가장 빠르게 처리한 녀석의 결과를 사용할시
ex> 1개의 빠른인스턴스 검색시 인덱스된 데이터가 불규적으로 분산되거나 중복이있을시 , 가장 빠른 결과물을 사용할시
SmallestMailbox
동일한 작업을 수행해도 완료시간을 동일하게 보장할수 없음으로
덜바쁜 노드에게 우선으로 일을 주는방식
TailChopping
기본적으로 랜덤 라우터이나, 최적 응답시간내에 반응못하면(5s)
마지막까지 처리는 하지만~ 특정노드를 잠시쉬게 하는 전략
> GC를 제대로 할 시간을 주지 못할때 해당 노드는 GC를 계속 시도하느라 CPU를 점유해서 뻗을수 있습니다. 이때 빈도가 특정노드중 일부이며 잠쉬 쉬면 정상화가 될수도 있다란 측정이 가능 했을때 활용가능합니다.
추가정보
https://github.com/reactive-streams
- https://github.com/akka/reactive-kafka
- https://blog.knoldus.com/2017/06/18/when-akka-stream-meets-rabbitmq/
여러 업체및 진영( Java/C#/SCALA/JS등 )에서 네트워크상의 비동기처리를 비롯하여 이와 관련한 문제에대해
공통적으로 고민하기 시작하였으며, 표준 인터페이스를 만드는 reactive-streams 활동으로 이어집니다.
akka를 비롯하여 위에서 언급한 stream처리가 필요한 플래폼들은 이 활동에 영향을 주거나/받았으며,
이러한 인터페이스에 대한 표준을 따르고 있습니다.
이것은 어떠한 구현체가 아니라, 구현을 위한 약속된 스펙입니다.
서로 다른 스트리밍구현이 상호운영이될수 있도록하는것이 이 프로젝트의 기대치입니다.
클러스터 탑재하기

설정
akka {
remote {
log-remote-lifecycle-events = debug
dot-netty.tcp {
port = 7000
hostname = 127.0.0.1
}
}
actor {
provider = cluster
deployment {
/cluster-roundrobin {
router = round-robin-pool # routing strategy
#routees.paths = ["/user/clustermsg"]
nr-of-instances = 500 # max number of total routees
cluster {
enabled = on
allow-local-routees = on
use-role = akkanet
max-nr-of-instances-per-node = 20
}
}
}
}
cluster {
seed-nodes = ["akka.tcp://actor-cluster@127.0.0.1:7100"] # address of seed node
roles = ["akkanet"] # roles this member is in
auto-down-unreachable-after = 300s
debug {
verbose-heartbeat-logging = off
verbose-receive-gossip-logging = off
}
}
}
주요설정
- actor.privider = cluster : 해당 액터들을 클러스터로 사용하겠다.
- cluster-roundrobin.cluster.user-role = 롤이름 : 라운드 로빈방식으로, 롤 이름으로 지정된 노드에서 작동됨
- cluster.seed-nodes : 등대역활 지정
- cluster.roles : 자신이 가져야할 롤 지정(복수개지정가능)
로컬액터 클러스터액터로 전환
protected Cluster Cluster = Akka.Cluster.Cluster.Get(Context.System);
private bool ClusterMode = true;
protected override void PreStart()
{
// subscribe to IMemberEvent and UnreachableMember events
if (ClusterMode)
{
Cluster.Subscribe(Self, ClusterEvent.InitialStateAsEvents,
new[] { typeof(ClusterEvent.IMemberEvent), typeof(ClusterEvent.UnreachableMember) });
}
}
protected override void PostStop()
{
if (ClusterMode) Cluster.Unsubscribe(Self);
}
// src : https://github.com/psmon/AkkaForNetCore/blob/master/AkkaNetCore/Actors/ClusterMsgActor.cs
기존 로컬전용 액터에, 잡담(Gossip) 기능을 추가하는것으로 클러스터 기능 작동준비가 완료됩니다.
도메인 메시지를 처리하는 Received에는 코드변화가 없습니다.
클러스터로 구성된 액터에게 메시지 보내기
// 클러스터 액터 설정 : https://github.com/psmon/AkkaForNetCore/blob/master/AkkaNetCore/Startup.cs
AkkaLoad.RegisterActor(
"clusterRoundRobin",
actorSystem.ActorOf(Props.Create<ClusterMsgActor>()
.WithDispatcher("fast-dispatcher")
.WithRouter(FromConfig.Instance),
"cluster-roundrobin"
));
// 클러스터 액터 DI 참조 얻기및 메시지 보내기 : https://github.com/psmon/AkkaForNetCore/blob/master/AkkaNetCore/Controllers/ActorTestController.cs
private readonly IActorRef clusterRoundbin1;
public ActorTestController()
{
clusterRoundbin1 = AkkaLoad.ActorSelect("clusterRoundRobin");
}
[HttpPost("/cluster/msg/tell")]
public void ClusterMsg(string value, int count)
{
for (int i = 0; i < count; i++)
clusterRoundbin1.Tell(value);
}
클러스터 한방에 로컬에서 뛰우기

클러스터 개발의 난제는, 로컬에 구성요소를 N개를 뛰우고 디버깅이 가능한가인데, 도커가 없을 시절
멀티노드를 뛰우는것은 상당히 불편한 과정에 하나였습니다.
요즘 대부분의 IDE들은 Docker(+Compose,+쿠버네틱)개발환경을 지원하고 있음으로
운영과 비슷한 조건의 노드 구성을 하고 구동시킬수 있으며 디버깅지원은 보너스입니다.
샘플에서는 추가로 DataDog(https://www.datadoghq.com/) 매트릭스 연동하였습니다. ( 클러스터에 발생하는 메시지에대한 모니터링)
데이터 분산처리
이 샘플에서는, 메시징을 별도로 저장하지 않았으며 처리중인 메시지는 영속화를 할수가 있습니다.
메시지가 저장되는 순간 데이터화(영속화)가 되었다라고 표현할수 있으며 이렇게 저장되는 메시지는
장애복구를 포함하여 전송보장및 우아한종료등 직접 설계에 반영할수 있습니다.
클러스터 싱글톤을 포함하여 샤딩처리및 영속화는 다음장 이후에 다뤄보겠습니다.
Links :
- https://getakka.net/articles/clustering/cluster-overview.html
- https://getakka.net/articles/clustering/cluster-sharding.html
- https://getakka.net/articles/clustering/distributed-data.html