MapReduce의 대안으로 최근 아주 뜨거운 기술이 있는데 바로 Apache Spark입니다.
Spark는 Hadoop MapReduce와 비슷한 목적을 해결하기 위한 클러스터 컴퓨팅 프레임웍으로,
메모리를 활용한 아주 빠른 데이터 처리가 특징입니다. 또한,
함수형 프로그래밍이 가능한 언어인 Scala를 사용하여 코드가 매우 간단하며, interactive shell을 사용할 수 있습니다.
akak와는 어떻게 상호운영을 할수 있는지 살펴보겠습니다.
소개
Spark 특징:
http://engineering.vcnc.co.kr/2015/05/data-analysis-with-spark/
설치
Spark를 고성능으로 잘 사용하려면 Spark엔진,클러스터스토어인 하둡,이를 스트림으로 활용할수있는 모듈등
여러 장치에 복잡하게 구성해야하나, StandAlone ( 하나의 설치 패키지에 모두포함하여 단일 노드에 모두작동)
으로 모두구성 하여 사용도 가능합니다.
Spark를 간략하게 알아보기위한것임으로 편한 방법을 선택합니다. 여기서는 웹에서 파이썬을 실행할수 있는
스파크 + 주피터노트북이 이미 설치된 도커 컨테이너를 활용하였습니다.
도커-키네마틱을 사용하여 스토어방식으로 원클릭설치
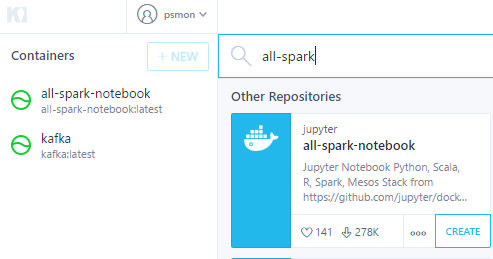
스파크의 구성요소를 공부하면서, 어렵게 설치할수도 있지만....
원클릭 인스톨을 시도하였습니다. 클러스터로 구성된 어떠한 서버 프레임을
설치를 시도하다가 짜증이나서 포기하는 경우가 많았는데...
키네마틱을 사용하면서 여러가지 서버툴들을 쉽게 사용하게 되었습니다.
주피터노트북
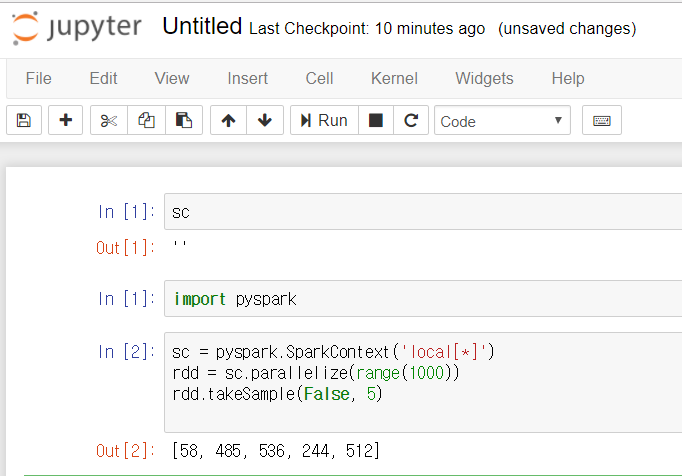
확장
Spark를 배치용도로 사용하고, 적당한 타이밍에 분석하고자한다면 SparkStream은 크게 필요없을듯 보입니다.
하지만 데이터의 수집이 , 정확하게는 생산자로부터 끊임없이 데이터가 발생하고 이것을 오랫동안 쌓아두지
않고 바로 소비하여 원하는 형태의 결과물로 만들고자할때 유용해보입니다. ( 글쓴 단계에서 연구중 )
Spark의 장점을 알게되었다면, Stream을 통해 어떻게 우리가가진 어플리케이션과 상호 운영할것인가?
에 대해 고민을 할수가 있습니다.

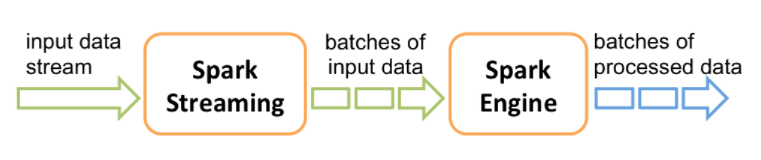
원본문서 : https://spark.apache.org/docs/latest/streaming-programming-guide.html
AKKA Stream와 상호운영

실시간 데이터 처리 플랫폼에서 Stream이 붙으면 , 상호운영이 된다고 보면 됩니다.
실시간 데이터 처리에있어서 중요한 키워드이며, 안정적으로 유실없이 어떻게
메시지를 상호간 처리하느냐에 대한 고민입니다. 이미지는 글쓴 단계에 찾은 아키텍이며
아직 연구대상에 있습니다.
Akka Stream 에서 상호운영되는 Stream플랫폼이 뭐가있나?
조사중 Spark을 알게 되고 설치가 왜이리 힘들어? 서치하다가
도커를 알게되었지만....,
목표와 다루는 분야가 약간 틀리지만
Python과 더불어 Docker / Spark 의 사용률과 인기가 점점 올라가고 있더군요
Spark-stream akka:
http://bahir.apache.org/docs/spark/2.1.0/spark-streaming-akka/
http://bahir.apache.org/docs/spark/current/spark-streaming-akka/