여러가지 소스에서 분석및 집계를 수행하여 추천데이터 혹은 목적성 데이터를 만들어야하며
그렇게 만들어진 데이터를 수십만명의 사용자에게 제공하기 위해 실시간 검색기능이 필요하다고 가정해봅시다.
기능 요약
- 여러가지 소스에서 데이터를 분석처리하여, 규모가 작은 목적성 데이터를 만들어냅니다.
- 배치/실시간처리등 Master LocalDB는 다양한 방법을 통해 데이터가 변경됩니다.
- MasterActor은 MasterLocalDB의 변경사항을 알려줍니다.
- SlaveActor는 Master의 변경사항을 다시 LocalDB에 분산 복제를 시도합니다.
- SlaveAPI는 LocalDB또는 SlaveActor를 통해 API 검색 서비스를 합니다.
- SlaveActor는 필요에따라, RDB가 아닌 방식을 통해 Mapreduce 기능을 수행합니다.
1차 설계
설계는 마무리되었고, 아래와같은 컨셉을 사용할것입니다.
RDB와 아닌것의 저장소를 썩어서 상호운영이 가능하게 하는것은 어려운일이고
SPARK 엔진 + 하둡 + RDB + 파이썬기반 분석시스템 조합으로 이러한 부분의 문제를 상당히 단순화하고
강력한 솔류션을 제공해주며 그것을 잘이용하는게 요즘 추세입니다.
여기서의 목표는 규모보다는, 빅데이터를 경량화시키고 데이터의 변경을 더 빨리 감지하는데 목적이 있으며
직접 클러스터기능을 구현하면서 시행착오를 통해 학습을 하는것입니다.
주요컨셉
Spring with AKKA https://gofore.com/en/collecting-data-with-akka-and-spring-boot/ (분산메시지처리를위해 Spring만으로는 부족함)
JPA Persitence : http://heowc.tistory.com/55 ( ORM은 RDB개발에서 메시지중심설계로 전환하는 핵심입니다. )
Spring Batch : http://wiki.gurubee.net/pages/viewpage.action?pageId=4949437 ( 일괄적인 방법의 배치 스케쥴링,DBMS에 JOB을 등록안할꺼임)
Akka Persitence : https://doc.akka.io/docs/akka/2.5.5/scala/persistence.html ( 레디스와 같은 메모리 DB를 직접구현)
AKKA Cluster : https://doc.akka.io/docs/akka/2.5/cluster-usage.html ( 이기종통신에서 카프카는 필수이지만, 카프카의 클러스터 메시징처리를 대처)
MapReduce : https://blog.knoldus.com/2014/09/29/map-reduce-with-akka-and-scala-the-famous-word-count/ ( 분산된 메모리로 데이터로부터 집계처리하는 방법 )
대부분 이용하는것보다, 직접 설계하는것에 컨셉을 두었습니다.
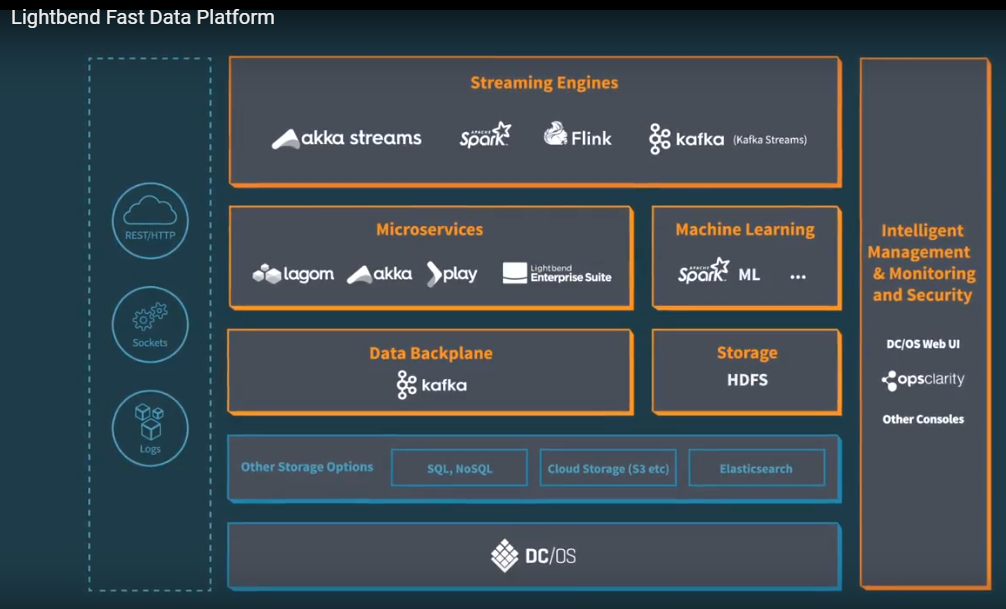
FastDataFlatform에서 잘설계된것을 이용하는것은 아래 LightBend가 가 추천되며
유사 아키텍을 여러개 살펴보았지만,가장 깔끔하게 구성된것으로 보이며 연구대상 1호입니다.
1차 설계의 문제점
준비중
2차 설계:
준비중