스프링 클라우드에서 Eureka - Zuul - Ribon 으로 연결되는 다이나믹하게 노드를 늘리고 로드밸런스를 지원하는 휼륭한 툴을 지원한다. 메시지큐와 연동되어 도메인이벤트도
원격처리가 되는듯하나. RestAPI에서 한해 유용해보인다. RestAPI가 아닌 원격 비동기 대량처리 스트림처리부분은 AKKA의 메시징 기법이 직관적이고 안정적이고 성능에 이점이 있는듯 하며
Kafka와 같은 외부 메시툴연동하기에도 더 이점이 있다. 더욱이 기존 구성된 마이크로서비스에 임베디드 되어 분산처리하는 방식이라 추가적인 큐시스템을 구축하지 않아도된다.
목적이 다른 플랫폼의 상호연동은 어려운 주제이기도 하지만, 잘 조화를 이루면 서로의 약점을 보완해줄수 있을것으로 기대해봅니다.
클러스터의 이해
클러스터를 구축하기전 클러스터에대한 이해가 필요합니다. 클러스터는 AKKA에서 생겨난 컨셉이 아니며
알게모르게 클러스터화된 시스템을 우리는 이용을 하고 있습니다.
클러스터가 왜 필요한가? 없었던 시절때를 생각해보면 이것이 필요한 이유를 이해할수 있습니다.
클러스터가 없었을때는 노드를 확장하기위해 노드를 추가하고, 기존 노드에 신규 노드에대한 설정을 셋팅한후
그 설정을 적용하기 위해 전체 서비스를 재시작하거나 잘작동되는 서비스의 리로드가 필요했습니다.
더자세한 문서 : 04. Clustering
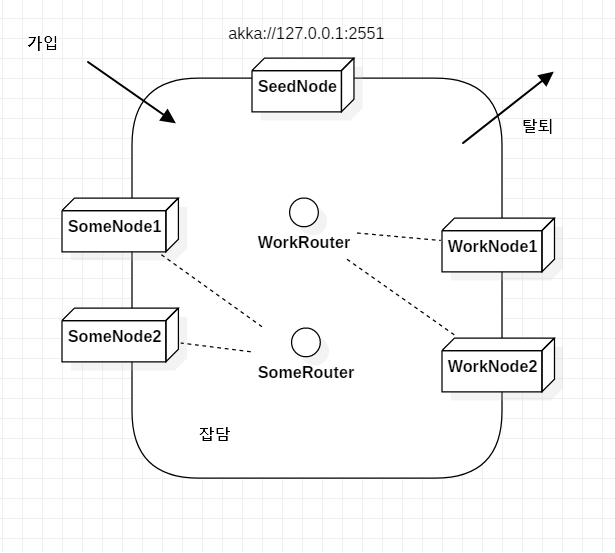
그래서 생겨난 컨셉이 클러스터이며, 작동 메카니즘은 간단합니다. 모든 노드의 클러스터 가입/탈퇴를 발견하는 책임이 있는
시드노드가 있으며(아파치의 주키퍼와 같은) 이 시드노드는 1개일수도 있고 여러개일수도 있습니다. 이 시드노드는 가급적
작동의 보장을 위해 도메인 기능 없이 순수하게 발견 역활만 합니다. 그리고 새로운 노드가 가입을 하게되면 서로 잡담을 하면서(피어투피어)
라우터는 신규노드를 알수 있습니다. 궁극적으로 최종 사용은 ip-port 물리적인 주소를 알필요가 없습니다.
우리가 구성한 라우터 이름 예를 들면 WorkRouter 란 이름만 알게되면 WorkNode가 몇개인지 신경쓸필요없이 작업처리가 가능합니다.
물론 설계시에는 클러스터를 위한 각 롤당 최소 충족조건이라는 개수를 설정할수가 있습니다.
분산처리의 기능은 라우팅과 로직에서 처리해야하는 주제이며 클러스터의 역활이 아닙니다.
보통 클러스터의 목적은 무설정 분산환경 접근에 목적이 있습니다.
이 차이를 잘 구분하면 클러스터를 이용할 준비가 된것입니다.
AKKA 사용 골
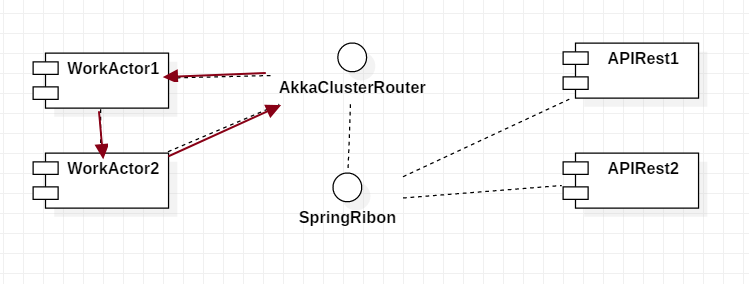
Actor1에 작업의뢰를 했지만 원격에 떨어진 Actor2의 결과를 비동기처리를 할수 있으며 이것은 Ribon의 원격명령에의해
수행될수도 있으며 Actor의 처리과정중 Ribon의 Rest호출 결과를 이용할수도 있습니다.
그럼 이것을 왜 Spring Cloud에 이식을 하려는 변종 실험을 하고 있을까요?
Spring 플랫폼은 일반적으로 RestAPI를 수월하게 다루는 좋은 웹플랫폼입니다. 하지만, 원격에 배포된 리모트 비동기 메시지를 처리는
Actor 사용이 더 유연합니다.
물론 일반적으로 외부 메시지큐는 카프카또는 레빗엠큐를 사용하여 도메인 이벤트의 전달 툴로 대체할수 있으며 AKKA일 필요는 없습니다.
구현샘플 : 충돌없는 복제
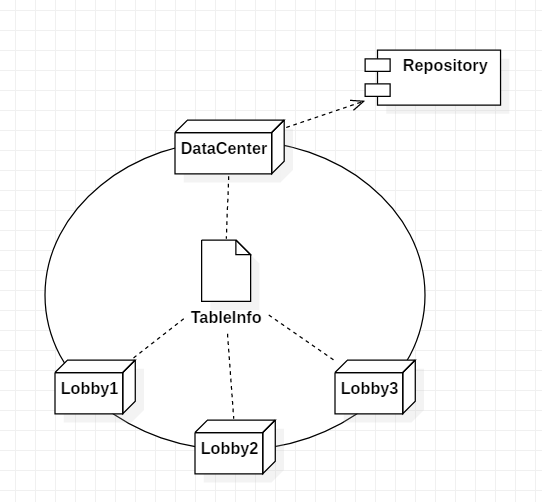
우선 이 기능이 유용함을 설명하기 위해 다음과 같이 보편적 도메인 목표를 지정하였습니다.
- 보편적 도메인목표: 비교적 스몰 데이터이나(경험상 10만미만), 동일한 데이터의 Read 성능을 극대화하고 싶다. -데이터량이 훨씬많아지면 복제가아닌 샤딩기법을 이용할수 있으며 전환도 용이합니다.
- 클러스터목표 : 복구를 위해 저장소에 정보는 저장하되, Read는 충돌없는 데이터 복제를 통해 분산된 메모리에서만 접근
여기서 전시를 책임 지는 Lobby는 무한대로 확장이 가능해야하며 필요하면 RestAPI로 제공될수 있으며 웹소켓으로도
제공될수 있습니다. 여기서는 액터를 통해 충돌없는 데이터복제를 한후 각각의 노드에서 RestAPI로 제공을 받는 방법을 선택해보겠습니다.
시드를 책임지는 디스커버리 앱설정
git : https://github.com/psmon/springcloud/tree/master/akka-cluster
클러스터를 설정없이 규모의 확장에 대비하기위해서는, 도메인 기능이 없는 디스커버리 역활인 시드노드를 먼저 설정해야합니다.
모든 노드의 위치를 알수 있는 등대와 같은 역활을 해서, Lighthouse 라고 불리기도합니다.
akka {
actor {
provider = cluster
}
remote {
enabled-transports = ["akka.remote.netty.tcp"]
netty.tcp {
hostname = "127.0.0.1"
port = 2552
}
}
cluster {
seed-nodes = [
"akka.tcp://ClusterSystem@127.0.0.1:2552"
]
roles = ["seed"]
role{
seed.min-nr-of-members=1
}
# auto downing is NOT safe for production deployments.
# you may want to use it during development, read more about it in the docs.
#
auto-down-unreachable-after = 10s
}
}
# Enable metrics extension in akka-cluster-metrics.
akka.extensions=["akka.cluster.metrics.ClusterMetricsExtension"]
메인 시드는 자기자신에게 가입함으로, 디스커리 역활을 수행할수 있습니다.
@Override
public Receive createReceive() {
return receiveBuilder()
.match(ClusterEvent.MemberUp.class, mUp -> {
log.info("Member is Up: {}", mUp.member());
})
.match(ClusterEvent.UnreachableMember.class, mUnreachable -> {
log.info("Member detected as unreachable: {}", mUnreachable.member());
})
.match(ClusterEvent.MemberRemoved.class, mRemoved -> {
log.info("Member is Removed: {}", mRemoved.member());
})
.match(ClusterEvent.MemberEvent.class, message -> {
// ignore
})
.build();
}
시드를 포함하여, 모든 워크 노드들은 위와같은 액터기능을 탑재해야합니다. 이것은 잡담이라고도 불리며
멤버가 가입되고 탈퇴하는 모든 메시지를 잡담을 통해 서로를 인지할수 있고 인지를 하기 때문에 목적지의 IP를
알필요없이 라우터를 통한 호출이 가능합니다.
요청시 데이터 를 통기화하는 액터
@Override
public void preStart() {
// first read for sync , After that no more db load
tableRepository.findAllTableInfos().forEach(tableEntity -> {
TableInfo tableInfo = tableEntity.toTableInfo();
tableInfos.add(tableInfo);
});
}
@Override
public Receive createReceive() {
return receiveBuilder()
.match(TableCMD.class, s -> {
if(s.cmdType==TableCMD.TableCMDType.SYNC_FIRST){
log.info("Received TableCMD message: {}", s);
ActorRef requestActor = getSender();
seqNumSync++;
requestActor.tell(new TableInfoList(seqNumSync,tableInfos),ActorRef.noSender());
}
})
.matchAny(o -> log.info("received unknown message"))
.build();
}
//Config
cluster {
seed-nodes = [
"akka.tcp://ClusterSystem@127.0.0.1:2551"
]
roles = ["datacenter"]
데이터센터가 가지는 Role설정과 기능이며, 가입된 클러스터 노드 아무나 복제요청을 하면 그것을 전달해주는 것입니다.
여기서는 최초의 저장소의 데이터만 전달해주는기능만 있으며, 이것은 Update,Insert,Delete등의 기능과 함께 변경부 전달이라는 기능을 추가할수 있습니다.
노드 가입시 자동 데이터복제
//Create a TableSync object when it joins the cluster
Cluster.get(system).registerOnMemberUp(new Runnable() {
@Override
public void run() {
system.actorOf(TableInfoActor.props(),"lobbyTableSync");
}
});
cluster {
seed-nodes = [
"akka.tcp://ClusterSystem@127.0.0.1:2551"
]
roles = ["lobby"]
role{
seed.min-nr-of-members=1
datacenter.min-nr-of-members=1
lobby.min-nr-of-members=1
}
분산되는 어플리케이션 lobby에 작동되는 설정과 코드이며, 여기서 핵심은 클러스터 최소 조건 (적어도 하나의 시드와 data센터 그리고 자신)
이 충족되었을때 동기화를 담당하는 액터를 생성하는 것입니다. 또한 자신의 롤은 lobby임을 설정하는것입니다.
동기화를 요청하는 액터
ActorRef dataCenter = getContext().actorOf(FromConfig.getInstance().props(),
"dcTableSyncRouter");
@Override
public void preStart() {
// first requestData
sendRefreshTable(TableCMD.TableCMDType.SYNC_FIRST);
getContext().setReceiveTimeout(Duration.create(10, TimeUnit.SECONDS));
}
private void sendRefreshTable(TableCMD.TableCMDType cmdType) {
dataCenter.tell(new TableCMD(cmdType),getSelf() );
}
@Override
public Receive createReceive() {
return receiveBuilder()
.match(TableInfoList.class, tableList -> {
tableInfos = tableList.getValues();
log.info(String.format("===== first Table sync, count:%d",tableInfos.size()));
})
.match(ReceiveTimeout.class, message -> {
log.info("=== Timer");
sendRefreshTable(TableCMD.TableCMDType.SYNC_FIRST);
})
.match(TableCMD.class, cmd -> {
if(cmd.cmdType == TableCMD.TableCMDType.SYNC_FIRST)
sender().tell(tableInfos,null);
})
.matchAny(o -> log.info("received unknown message"))
.build();
}
갱신기능을 넣지 못했지만, 최초 데이터를 요청하고 ( 스냅샷컨셉을 추가하면, 갱신부를 다룰수 있으며, 이것은 푸시로도 확장될수 있습니다.)
주기적으로 상태를 갱신할수 있습니다. 여기서 핵심은 원격지의 dataCenter 액터 접근객체를 얻기위해 어떠한 ip가 사용되지 않았다는것입니다.
클러스터 최소조건을 충족하면 그냥 사용할수 있습니다.
akka.actor.deployment {
/lobbyTableSync/dcTableSyncRouter = {
# Router type provided by metrics extension.
router = cluster-metrics-adaptive-group
# Router parameter specific for metrics extension.
# metrics-selector = heap
# metrics-selector = load
# metrics-selector = cpu
metrics-selector = mix
#
routees.paths = ["/user/dcTableSync"]
cluster {
enabled = on
use-role = datacenter
allow-local-routees = off
}
}
}
위 라우터가 설정됨으로 datacenter에 해당하는 어플리케이션을 자동으로 찾을수가 있습니다.
보통 이러한 설정은 라우터 전략과함께 이용하는 측에서 셋팅이됩니다.
Spring Cloud내에서 클러스터를 직접 설계하는 실험을 해보았으며 이것은 실제로 잘 작동을 합니다.
AKKA가 오해받는 것은 이러한 클러스터 설계를 비교적 몇가지 툴을 사용하여 유연한 구현이 가능하지만
어렵다, 괴상한 개발방법이다. , 액터는 극안무도한 추상화 객체이다 등 오해를 받습니다.
최근 추세는 외부플랫폼을 사용하여 비용을 지불하고 이러한 분산처리기능을 쉽게이용할수 있습니다.
하지만 클러스터에대한 이해없이 그러한 툴을 사용하고 있지 않은지? 또는 이러한 컨셉을 사용못해
중앙 DB에 부하를 전가하고 비용으로 해결하지 않은지? 고민해볼 여지는 있어보입니다.
분명한건 메시지 처리에 한해 좋은 학습 도구라는점이며 이러한 컨셉을 익혀두는 것은
AKKA가아닌 다른 플랫폼을 사용하여 운영레벨에 도입하는것에도 도움이 된다란 것입니다..
여기서는 비교적 간단하게 Akka Cluster를 이용하였으며, 다음 문서를 통해 더 상세한 기능을
살펴볼수가 있습니다.
참고 : https://doc.akka.io/docs/akka/2.5/cluster-metrics.html