Akka는 오픈 소스 툴킷으로, JVM 상의 동시성과 분산 애플리케이션을 단순화하는 런타임이다. Akka는 동시성을 위한 여러 프로그래밍 모델을 지원하지만, Erlang으로부터 영향을 받아 actor 기반의 동시성이 두드러진다.
자바와 스칼라 언어 모두로 작성이 가능하다. Akka는 스칼라 2.10로 작성되었으며, 스칼라 2.10의 Akka의 actor 구현은 스칼라 표준 라이브러리에 포함되어있다.[1]
.net(c#)버전으로 포팅된 버전이 Akka.net 이며 여기서는 주로 Akka.net이 이용되었습니다.
반응성 좋은 서비스를 위해 분산처리도 중요하지만 단일장비 자체의 성능을 올리는것도 중요합니다. 물론 AKKA는 클러스터를 통해 분산처리 환경 개발자체를 단순화하는 방법도 제공합니다.
동시성 처리를 높이기위해 단일 어플리케이션 내에서도 한가지 일만 하는것이 아닌 동시에 여러가지 일을 수행하게 할수 있으며 , 스레드를 적극 활용하여 병렬성을 이용하는 개발을 멀티스레드 프로그래밍 이라고 합니다.
동시성 처리및 병렬처리
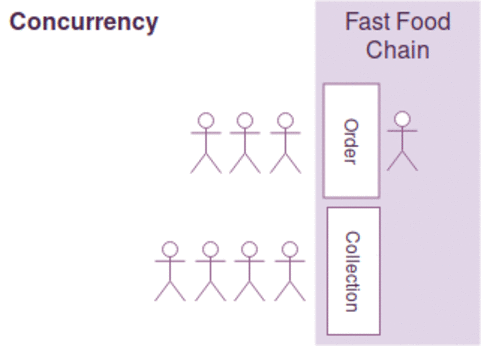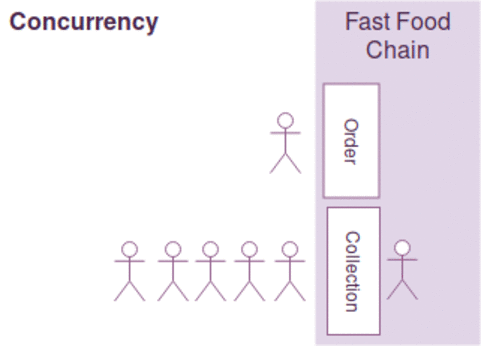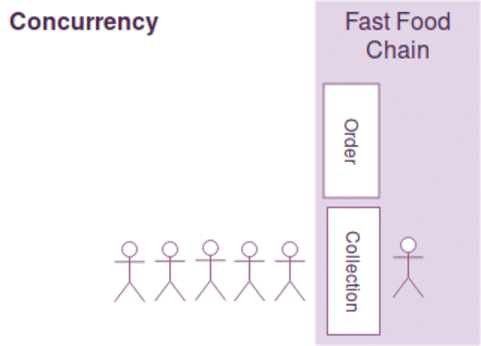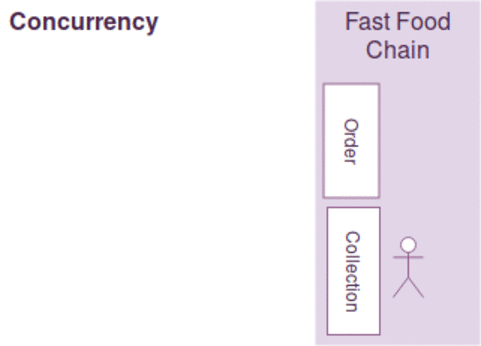
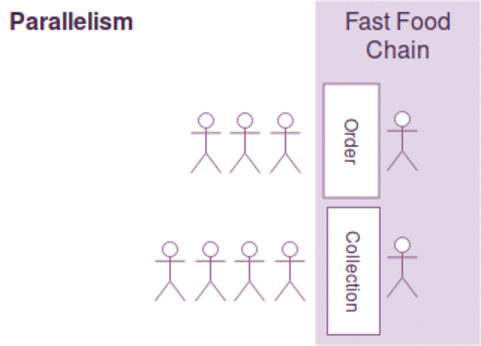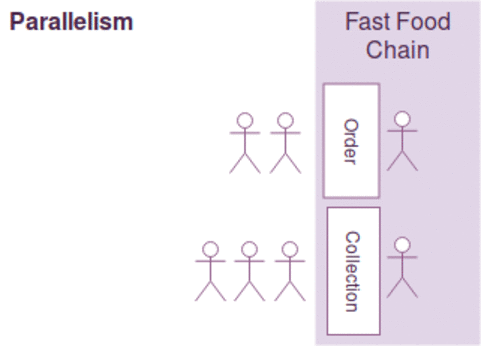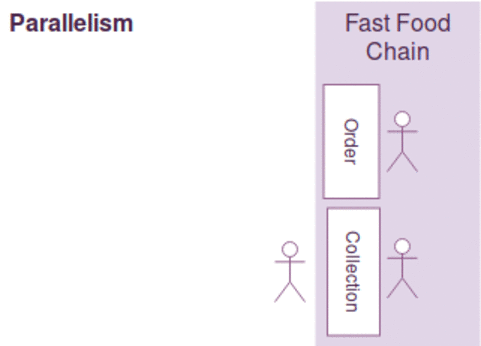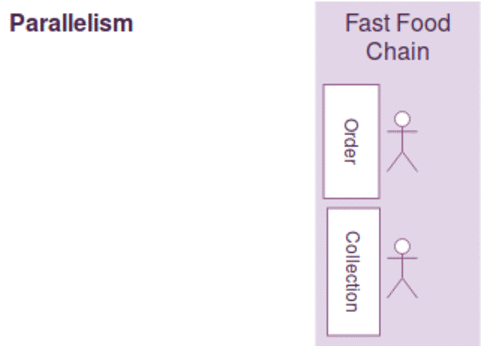
동시성과 병렬성은 약간의 차이가 있지만, 다음과 같이 간략하게 설명될수 있습니다.
- 동시성 : 한사람이 커피주문 받고 만들기를 동시에한다. ( 커피머신을 이용하면서도 주문을 받음)
- 병렬성 : 커피주문을 받는사람과 만드는 사람이 각각 따로 있다.
- 순차성 : 한사람이 커피주문을 받고 커피를 만들지만~ 커피가 완성될때까지 다음손님 주문을 받지 못한다.
일반적으로 작업의 최대 효율을 높이기 위해 동시성과 병렬성을 함께 고려해야 하며 병렬성에서는 커피주문 접수받는것 자체가 밀리게 되면, 그동안 커피만드는 사람이 놀수 있는 문제가 있으며
커피 주문을 받고/만들기를 동시에 하는 경우 커피를 만드는 커피머신이 결정적으로 느린경우 동시성 처리를 하는 작업자를 늘린다고 작업효율이 증가하지 않습니다.
작업효율을 높이기위해 병렬+비동기처리 프로그래밍의 난이도가 높아지며 결정적으로 암달의 법칙에 의해 작업자를 늘린다고 작업효율이 높아지기 어렵습니다.
많은 사람이 비동기식으로 개발하면 멀티 스레드를 활용하는것처럼 이해하고 있지만~ 비동기와 멀티스레드는 다른의미 입니다. 비동기 프로그래밍은 단일스레드에서 작업효율을 낼수 있으며 싱글/멀티 스레드로 작동할지는 결정할수 있지만 플랫폼에 따라 싱글스레드로 제약이 있을수 있습니다.
- 동기식 : 계란을 요리 한 다음 토스트를 요리합니다.
- 비동기식 단일 스레드 : 계란 요리를 시작하고 타이머를 설정합니다. 토스트 요리를 시작하고 타이머를 설정합니다. 둘 다 요리하는 동안 부엌을 청소하십시오. 타이머가 꺼지면 계란을 불에서 꺼내고 토스트를 토스터에서 꺼냅니다.
- 비동기식, 멀티 스레드 : 계란 요리와 토스트 요리를 위해 두 명의 요리사를 더 고용합니다. 이제 자원을 공유 할 때 요리사가 부엌에서 서로 충돌하지 않도록 요리사를 조정하는 데 문제가 있습니다. 특정 조리기구가 하나만 존재할때 이문제는 발생할수 있습니다.
암달의 법칙

병렬 컴퓨팅에서 멀티 프로세서를 사용할 때 프로그램의 성능향상은 프로그램의 순차적인 부분에 의해 제한된다. 예를 들면, 프로그램의 95%가 병렬화 할 수 있다면 이론적인 최대 성능 향상은 아무리 많은 프로세서를 사용하더라도 최대 20배로 제한된다.
병렬 컴퓨팅을 위해, 자원을 공유하는 멀티스레드 프로그래밍을 하게되는 경우, 대표적으로 다음과같은 4가지 문제를 피하기 어려울수 있습니다.
- DeadLock(교착상태)
- Starvation(빈곤)
- LiveLock
- Race Condition
추가 참고 자료 : Terminology
AKKA역시 멀티스레드를 활용하기 때문에 암달의 법칙에서 자유로울수는 없지만, 순차적으로 처리하는 부분에 대한 면적을 최대한 줄이면서 멀티스레드 프로그래밍을 할필요 없게 단순화해주며 동일한 개발컨셉으로 네트워크 분산처리를 지원합니다. 원격에 있는 멀티스레드를 제어할수 있는 효과를 가질수 있으며 분산처리에 용이합니다.
Actor의 메시지큐와 Dispatcher
그러면 Akka에서는 어떻게 병렬성과 동시성문제를 포함 메시지 순차보정을 멀티스레드 프로그래밍 없이 할수 있을까요? 액터모델과 Mailbox Dispatcher 의 조합으로 이해할수 있습니다.

- 액터 특징 : 단일 액터는 순차성이 보장되며 자신만의 메시지 Queue를 가질수 있습니다. 동시처리를위해 멀티스레드가 아닌 액터를 늘릴수 있으며 스레드보다 가볍습니다. ( 1스레드는 1MB의 스택메모리를 예약합니다. )
- MailBoxQueue : 순차성이 보장되지만, 메시지 우선순위를 조정할수도 있습니다.
- Dispatcher : 액터에 요청된 이벤트의 수행을 어떠한 전략으로 수행할지는 Dispatcher에 규칙을 정할수 있으며, 멀티스레드를 이용할수 있지만~ 멀티스레드 프로그래밍을 할 필요가 없습니다.
- 액터 : 모든 액터는 메시지로 명령수행이 가능하며 리모트로 확장될시 클러스터 라우터를 통해서도 작업분배가 용이합니다. 이것은 로컬과 리모트의 프로그래밍 방식에 큰차이가 없음을 의미하며 Kafka와 같은 메시징 툴과의 조합도 유리할수 있습니다. ( alpakka 는 Reactive Stream의 구현체로 Akka를 모든곳과 연결을 할수 있는 모듈명입니다. )
성능업(ScaleUP) VS 확장(ScaleOUT)
ScaleUP
노드1의 장비 성능을 높이기위해 사용되는 여러가지 행위임
최종적으로 하나의 장비에서 많이 처리하고, 전체 장비의 개수를 줄이는 데 목적이 있으며,
장비의 고효율 IO처리, 효율적메모리관리및 CPU사용 최적화등의 튜닝 기술등이 이용될수 있으며
외적으로는 고성능 장비 도입 및 효율적 IO사용 분리 역시 같은 의미가 될수 있으며
개선및 도입에 따른 측정도 중요한 사안입니다.
ScaleOut
측정된 노드1의 성능을 베이스로, 대용량처리를 위해 노드를 수평적으로 확장해 나갈수 있는 행위이며
다른 서비스 의존성으로인한 병목현상으로 실제는 확장수만큼 성능이 올라가지는 않습니다.
이러한 손실을 줄이고 확장을 통한 성능향상을 위해 여러가지 클러스터및 분산저장 기술등이 이용됩니다.
외적으로는 장비를 병렬적으로 늘리고 효율적으로 관리하는 방법도 포함될수 있습니다.
병렬적으로 늘린 장비에 대한 장애대비,관리,확장대비 성능측정도 중요한 사안입니다.
동시성(Concurrency) VS 병렬처리(Parallelism)
동시성과 병렬성은 관련 개념이지만 약간의 차이점이 있습니다.
동시성이란 두 개 이상의 작업이 동시에 실행되지 않을 수도 있지만 작업이 진행 중임을 의미합니다.
예를 들어 작업의 일부가 순차적으로 실행되고 다른 작업의 일부와 혼합되는 시간 조각으로 실현할 수 있습니다.
반면에 병렬 처리는 실행이 진정으로 동시에 일어날 수있을 때 발생합니다.
concurrency
![]()
동시성의 경우, 본질적으로 작업이 ,동일시간에 한꺼번에 실행되지는 않습니다.
작업단위가, 블락당하지 않고 계속 흘러감으로 마치 여러가지 작업이 한꺼번에 수행되는것 처럼 보이는것으로
일반적으로 스레드 사용을 명시적으로 하지 않습니다.
using System;
using System.Threading;
using System.Threading.Tasks;
class CustomData
{
public long CreationTime;
public int Name;
public int ThreadNum;
}
public class Example
{
public static void Main()
{
// Create the task object by using an Action(Of Object) to pass in custom data
// to the Task constructor. This is useful when you need to capture outer variables
// from within a loop.
Task[] taskArray = new Task[10];
for (int i = 0; i < taskArray.Length; i++) {
taskArray[i] = Task.Factory.StartNew( (Object obj ) => {
CustomData data = obj as CustomData;
if (data == null)
return;
data.ThreadNum = Thread.CurrentThread.ManagedThreadId;
Console.WriteLine("Task #{0} created at {1} on thread #{2}.",
data.Name, data.CreationTime, data.ThreadNum);
},
new CustomData() {Name = i, CreationTime = DateTime.Now.Ticks} );
}
Task.WaitAll(taskArray);
}
}
// The example displays output like the following:
// Task #0 created at 635116412924597583 on thread #3.
// Task #1 created at 635116412924607584 on thread #4.
// Task #3 created at 635116412924607584 on thread #4.
// Task #4 created at 635116412924607584 on thread #4.
// Task #2 created at 635116412924607584 on thread #3.
// Task #6 created at 635116412924607584 on thread #3.
// Task #5 created at 635116412924607584 on thread #4.
// Task #8 created at 635116412924607584 on thread #4.
// Task #7 created at 635116412924607584 on thread #3.
// Task #9 created at 635116412924607584 on thread #4.
Parallelism

병렬처리의 경우 작업을 명시적으로 여러개의 물리(코어)적 연산 장치에 각각 Join시켜 한꺼번에 처리하는 경우를 진정한 의미에서 병렬처리라 할수 있습니다.
가용한(풍부한) 자원을 바탕으로, 여러가지 작업을 한꺼번에 수행할수가 있습니다.
일반적으로 각 작업단위를 스레드하나에 할당하고 다수의 스레드를 동작시키는것도 병렬처리라고 볼수 있습니다.
//병렬처리를 위한 멀티 코어 프로그래밍 예
Thread[] threads = new Thread[NumOfThread];
Process currentProcess = Process.GetCurrentProcess();
foreach (ProcessThread processThread in currentProcess.Threads)
{
processThread.ProcessorAffinity = currentProcess.ProcessorAffinity;
}
//물리적단위인 Core(process) 에 Task를 명시적으로 걸고 동시에 시작해버립니다.
for (int i = 0; i < NumOfThread; i++)
{
threads[i].Join();
}
}
Synchronous(동기)
메서드 호출후 값이 반환되거나, 예외가 throw될때까지 호출자가 진행할수 없는 경우
Asynchronous(비동기)
메서드 호출후, 호출자는 몇가지 메카니즘(완료및 진행 등록된 콜백)을 통해 알수있으며
진행이가능 합니다. 동기구현을 목적으로 블로킹(Result)기능을 사용할수 있지만
일반적으로 비동기 API로 설계하는것은 시스템이 진보할수 있음을 보장함으로 선호됩니다.
액터는 본질적으로 비동기입니다.
주의 : 비동기 메서드 진행중 일어나는 모든 예외가, 호출자의 예외처리 블락에 잡히지 않을수 있음에 유의합니다.
Non-blocking vs. Blocking
한 스레드의 지연이 다른 스레드를 무기한 지연 시킬수 있을때 블록킹되었다라고 표현함
예를 들면 상호배제(mutual exclusion)을 사용하여 하나의 스레드가 독점할시 자원을 공유하고있는
다른 스레드가 진행될수 없는경우
논블록킹은 이와 반대되는 개념으로, 어떠한 스레드도 다른것들을 무기한 연기할수 없다란것을 의미합니다.
블록킹 작업포함시 전반적인 작업진행이 쉽게 보장이 되지 않기때문에, 논블록킹 작업방식으로의 설계가 추천됩니다.
Deadlock vs. Starvation vs. Live-lock
DeadLock
DeadLock(교착상태)는 여러 Task가 어떠한 특정 상태를 기다린후 진행할수 있는 구조에서
어떠한 Task가 특정상태에 도달하지 못할때 하위의 모든 시스템이 멈추는 경우입니다.
Starvation
Starvation(빈곤)은 계속 진행이되며 , 우선순위가 높은 Task가 어렵게 진행이되지만
항상 높은 우선순위의 Task를 선택하는 순진한 스케쥴링 알고리즘때문에 낮은 순위의 Task가
끝나지 않거나 진입을 못하는 경우입니다.
LiveLock
LiveLock은 Task중 누구도 진행되지 않는 경우이며, 교착상태와 유사합니다. 서로 진행되기를
기다리면서 Task의 상태가 지속적으로 변화는 상황으로 불행한 경우 획득하지 않고 항상 상대방에게
양보하는 경우가 발생하여 누구도 실행되지 않는 케이스입니다.
Race Condition
우리가 정한 이벤트 세트의 순서에대한 가정이 , 외부의 결정적이지 않은 효과임에도 불구하고
위반되어 오동작인 상태가 되는것을 레이스(경쟁) 조건이라고 합니다.
발생하는 케이스는 스레드가 공유 가능상태를 가지고 경쟁상태가 자주발생하면서 스레드의 작업순서가
바뀌면서 예기치 않는 동작이 발생하는것입니다. 일반적으로 공유상태는 경쟁조건을 가질필요가 없으며
순서를 보정하지 않습니다. 패킷으로 예를 들면 P1,P2를 차례로 서버에 보냈지만 패킷이 다른 네트워크의
경로 를 통해 P2를 먼저받고 P1을 나중에 수신받을수 있으며 순서에대한 정보처리없이 서버가 이를 처리하려한다면
패킷의 의미에 따라 Race Condion(경쟁조건)이 발생할수가 있습니다. 이것은 멀티스레드에서도 발생할수 있는
문제이며 동시에 공유자원을 접근해서 발생하는 문제도 포함됩니다.
이러한 문제는 여러가지 액터가 메시지를 동시에 보내고
어떠한 한가지 액터가 그 메시지를 받아서 처리할때 메시지 순서에대한 보증을
어떠한 근거로 할것인가? 의 고민에 빠지게됩니다.
메시지 전달 보증(Message Delivery Reliability)에 추가적으로 언급하겠습니다.
Non-blocking Guarantees (Progress Conditions)
이전 섹션에서 설명된것처럼 블로킹은 여러가지 이유로 바람직하지 않습니다.
이것은 교착상태의 위험과 시스템 처리량 감소를 야기 시킬수 있습니다.
다음은 다양한 강도(차단이 강하거나 제한) 를 지닌 차단 특성에대해 논의를 합니다.
Wait-freedom -기다림이 없으나 호출수 한정
모든 호출이 한정된 수의 단계로 끝나도록 보장되는 경우 메소드는 대기하지 않아도됩니다.
wait-free 메소드는 결코 블로킹되지 않으며 교착상태가 발생하지 않으며
참여자는 제한된 수의 호출후에 진행할수 있으므로 궁핍(기아)현상이 발생하지 않습니다.
Lock-freedom -Lock이 없음
Lock이 없기때문에 교착상태가 발생하지 않지만
호출이 결국 완료되는것을 보장하지 않기때문에 궁핍(기아)현상을 보장하기에는 충분하지 않습니다.
Obstruction-freedom -기다림/Lock등 방해요소가없음
메소드가 격리되어 작동하다가, 특정 시점을 (Write중)
obstacle-free(방해가 없는상태)라고 하며 ,다른 스레드가 접근시
아무런 조취를 하지 않기때문에 진행작업이 중단될수가 있습니다. ( access violation at address )
낙관성 동시성 제어(OCC-Optimistic concurrency control)
동시성 처리에있어서 충돌 발생가능성이 거의 없거나, 큰 문제가 되지 않는다란 가정을 하여
안전한 동시성 처리를 위해 필요했던 Locking을 사용을 배제합니다. ( 적어도 Read에서 Lock을 제거)
하지만, 아무것도 하지 않는다란 의미가 아니고 충돌이 없다란 가정을 충족하기위해
Lock이 필요없어야할 아이디어가 추가가되며, 그 아이디어는 사용 콤포넌트(데이터베이스,Local Disk,Thread)마다 다를수 있습니다.
동시성 처리를 위해, Lock이 항상 필요해야한다란것은 비관적 동시제어로 불릴수 있으며 가장 안전한동시에 단순하며 성능문제로 쓸모 없어질수 있습니다.
참고 : 데이터 베이스에서의 낙관성 동시제어
2 Comments
Anonymous
자료 감사합니다.
잘 보았습니다.
PSMON
관심 감사합니다.
Add Comment