JAVA에서 KAFKA활용을 하기 위한 툴중하나인~ Alpakka Kafka를 활용하는 UnitTest기를 작성해보았습니다.
Alpakka 특징
알파카(Alpakka)는 레액티브(Reactive) 스트림 처리를 위한 라이브러리입니다. 이 라이브러리의 주요 장점은 다음과 같습니다:
다양한 스트림 처리 기술 지원: 알파카는 다양한 스트림 처리 기술을 지원합니다.
예를 들어, Apache Kafka, Amazon S3, Amazon Kinesis, RabbitMQ 등과 같은 다양한 데이터 소스와 Sink를 처리할 수 있습니다.
높은 확장성: 알파카는 대용량 데이터 처리를 위한 높은 확장성을 제공합니다.
알파카는 Akka Streams 프레임워크를 기반으로 하며, Akka는 높은 확장성을 가진 Actor 모델을 사용하여 대용량 처리를 처리할 수 있습니다.
유연성: 알파카는 다양한 데이터 형식을 처리할 수 있으며, 다양한 소스와 Sink를 조합하여 유연하게 처리할 수 있습니다. 이러한 유연성은 다양한 비즈니스 요구에 대응할 수 있도록 도와줍니다.
개발 생산성 향상: 알파카는 스트림 처리에 필요한 많은 기능을 제공하므로 개발 생산성을 향상시킵니다. 예를 들어, 알파카는 배압 처리, 에러 핸들링, 메모리 관리 등과 같은 기능을 제공합니다.
리액티브 프로그래밍 모델 지원: 알파카는 리액티브 프로그래밍 모델을 지원하므로 비동기적이고 반응적인 코드를 작성할 수 있습니다.
이러한 코드는 보다 성능이 높고 유지 보수가 용이합니다.
다양한 언어 지원: 알파카는 다양한 언어를 지원합니다. 현재는 자바와 스칼라를 지원하며, 앞으로는 더 많은 언어를 지원할 예정입니다.
개발자 커뮤니티 지원: 알파카는 매우 활발한 개발자 커뮤니티를 가지고 있습니다. 이러한 커뮤니티는 알파카를 사용하는 개발자들에게 지속적인 지원을 제공합니다.
by chat gpt
Reactive Stream을 선언한 오픈스택과 스트림처리 개발방식을 단일화 할수 있습니다.

- https://doc.akka.io/docs/akka/current/stream/stream-flows-and-basics.html - Akka Stream API가 전반적으로 이용이됩니다.
의존모듈 셋업하기
plugins {
id 'java'
id 'org.springframework.boot' version '2.7.8-SNAPSHOT'
id 'io.spring.dependency-management' version '1.0.15.RELEASE'
}
group = 'com.webnori'
version = '0.0.1-SNAPSHOT'
sourceCompatibility = '11'
configurations {
compileOnly {
extendsFrom annotationProcessor
}
}
repositories {
mavenCentral()
maven { url 'https://repo.spring.io/milestone' }
maven { url 'https://repo.spring.io/snapshot' }
}
dependencies {
def scalaVersion = '2.13'
def akkaVersion = '2.7.0'
implementation 'org.springframework.boot:spring-boot-starter-web'
implementation 'org.springframework.boot:spring-boot-starter-aop:2.7.0'
implementation 'org.springframework.boot:spring-boot-starter-validation:2.7.5'
compileOnly 'org.projectlombok:lombok'
annotationProcessor 'org.projectlombok:lombok'
//DB
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
implementation 'com.mysql:mysql-connector-j'
//AKKA
implementation platform("com.typesafe.akka:akka-bom_$scalaVersion:$akkaVersion")
implementation "com.typesafe.akka:akka-actor_$scalaVersion:$akkaVersion"
implementation "com.typesafe.akka:akka-stream_$scalaVersion"
implementation "com.typesafe.akka:akka-stream-kafka_$scalaVersion:4.0.0"
//Logging
implementation 'ch.qos.logback:logback-classic:1.2.3'
implementation "com.typesafe.akka:akka-slf4j_$scalaVersion:$akkaVersion"
//Swagger
implementation 'org.springdoc:springdoc-openapi-ui:1.6.6'
//Test
testImplementation 'org.springframework.boot:spring-boot-starter-test'
testImplementation "org.scalatestplus:junit-4-12_$scalaVersion:3.3.0.0-SNAP2"
testImplementation "com.typesafe.akka:akka-testkit_$scalaVersion:$akkaVersion"
testImplementation "com.typesafe.akka:akka-stream-testkit_$scalaVersion"
testImplementation "com.typesafe.akka:akka-stream-kafka-testkit_$scalaVersion:4.0.0"
}
tasks.named('test') {
useJUnitPlatform()
}
Spring Boot -JAVA 버전에서 이용할수 있습니다.
로컬환경 Kafka준비
version: '3.5'
services:
zookeeper-1:
image: confluentinc/cp-zookeeper:5.5.1
ports:
- '32181:32181'
environment:
ZOOKEEPER_CLIENT_PORT: 32181
ZOOKEEPER_TICK_TIME: 2000
kafka-1:
image: confluentinc/cp-kafka:5.5.1
ports:
- '9092:9092'
depends_on:
- zookeeper-1
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper-1:32181
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: INTERNAL
KAFKA_ADVERTISED_LISTENERS: INTERNAL://kafka-1:29092,EXTERNAL://localhost:9092
KAFKA_DEFAULT_REPLICATION_FACTOR: 3
KAFKA_NUM_PARTITIONS: 3
kafka-2:
image: confluentinc/cp-kafka:5.5.1
ports:
- '9093:9093'
depends_on:
- zookeeper-1
environment:
KAFKA_BROKER_ID: 2
KAFKA_ZOOKEEPER_CONNECT: zookeeper-1:32181
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: INTERNAL
KAFKA_ADVERTISED_LISTENERS: INTERNAL://kafka-2:29093,EXTERNAL://localhost:9093
KAFKA_DEFAULT_REPLICATION_FACTOR: 3
KAFKA_NUM_PARTITIONS: 3
kafka-3:
image: confluentinc/cp-kafka:5.5.1
ports:
- '9094:9094'
depends_on:
- zookeeper-1
environment:
KAFKA_BROKER_ID: 3
KAFKA_ZOOKEEPER_CONNECT: zookeeper-1:32181
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: INTERNAL
KAFKA_ADVERTISED_LISTENERS: INTERNAL://kafka-3:29094,EXTERNAL://localhost:9094
KAFKA_DEFAULT_REPLICATION_FACTOR: 3
KAFKA_NUM_PARTITIONS: 3
kafka-ui:
image: provectuslabs/kafka-ui
container_name: kafka-ui
ports:
- "8989:8080"
restart: always
environment:
- KAFKA_CLUSTERS_0_NAME=local
- KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS=kafka-1:29092,kafka-2:29093,kafka-3:29094
- KAFKA_CLUSTERS_0_ZOOKEEPER=zookeeper-1:22181
kafka ui툴을 내장하였으며
docker-compose up -d 명령을 통해 kafka 클러스터 실행이 가능합니다.
Kafka 메시지 100개 생성하기
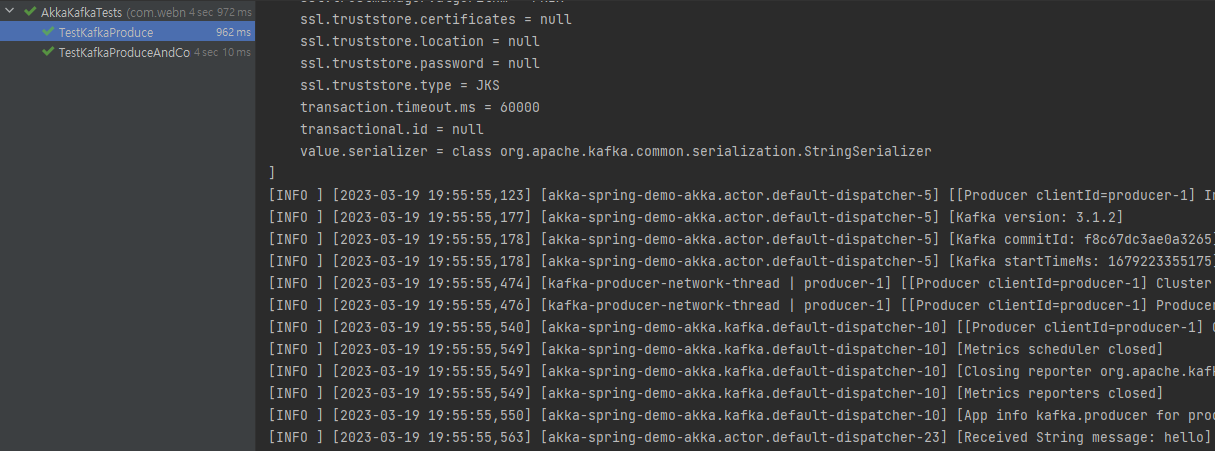
Junit Base + Akka UnitTest 에서 작성이되며 , 블락킹 하지않고 작동이되기때문에 복잡한 메시지 테스트도 수초이내에 완료됩니다.
@Test
@DisplayName("KafkaProduce - 100개의 메시지생산이 처리완료")
public void TestIt() {
new TestKit(system) {
{
final TestKit probe = new TestKit(system);
final ActorRef greetActor = AkkaManager.getInstance().getGreetActor();
greetActor.tell(probe.getRef(), getRef());
expectMsg(Duration.ofSeconds(1), "done");
final Config config = system.settings().config().getConfig("akka.kafka.producer");
final ProducerSettings<String, String> producerSettings =
ProducerSettings.create(config, new StringSerializer(), new StringSerializer())
.withBootstrapServers("localhost:9092");
String topic = "test-1";
CompletionStage<Done> done =
Source.range(1, 100)
.map(number -> number.toString())
.map(value -> new ProducerRecord<String, String>(topic, value))
.runWith(Producer.plainSink(producerSettings), system);
Source<Done, NotUsed> source = Source.completionStage(done);
within(
Duration.ofSeconds(10),
() -> {
Sink<Done, CompletionStage<Done>> sink = Sink.foreach(i ->
greetActor.tell("hello", getRef())
);
source.runWith(sink, system); // 10
// check that the probe we injected earlier got the msg
probe.expectMsg(Duration.ofSeconds(5), "world");
// Will wait for the rest of the 3 seconds
expectNoMessage();
return null;
});
}
};
}
생산된 Kafka Message 확인
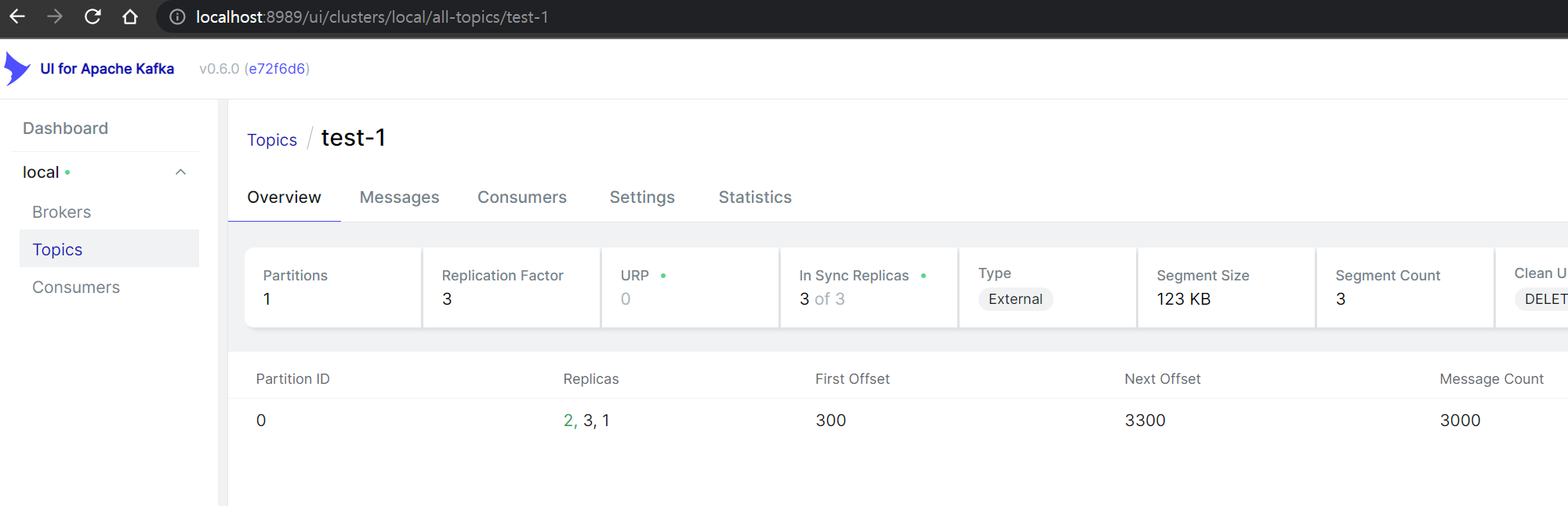
생성한 메시지를 Kafka툴을 통해 확인할수 있습니다.
더 정확한 유닛테스트는 생산자와 소비자를 모두 등록하여, 생산한 메시지의 카운트를 최종 소비자를 통해 검증하는것입니다.
Alpakka이용시 Kafka의 기능을 이용하여 AtLeastOnce 전략을 사용할수 있습니다.
- https://doc.akka.io/docs/alpakka-kafka/current/atleastonce.html
- AtMostOnce - 리시버가 받았는지 관심없을때
- AtLeastOnce - 최소한번 메시지 전송보장
- EXACTLY-ONCE DELIVERY - 정확하게 중복없이 한번 전달로 , 전송 라이브러리가 보장할수 있는것이 아닙니다.
생산자와 소비자를 함께 테스트하기
void debugKafkaMsg(String key, String value, ActorRef greet, String testKey) {
System.out.printf("pringKafka with Key-Value : %s-%s%n", key, value);
//테스트키 동일한것만 카운트 확인..(테스트마다 Kafka고유키 사용)
if(testKey.equals(key)) greet.tell("hello", null);
}
@Test
@DisplayName("KafkaProduce - 100개의 메시지생산을하고 100개의 메시지소비테스트 확인")
public void TestKafkaProduceAndConsume() {
new TestKit(system) {
{
final TestKit probe = new TestKit(system);
final ActorRef greetActor = AkkaManager.getInstance().getGreetActor();
final int testCount = 100;
final String testKey = java.util.UUID.randomUUID().toString();
final String testKafkaServer = "localhost:9092";
final String testGroup = "group1";
greetActor.tell(probe.getRef(), getRef());
expectMsg(Duration.ofSeconds(1), "done");
final Config producerConfig = system.settings().config().getConfig("akka.kafka.producer");
final ProducerSettings<String, String> producerSettings =
ProducerSettings.create(producerConfig, new StringSerializer(), new StringSerializer())
.withBootstrapServers(testKafkaServer);
final Config conSumeConfig = system.settings().config().getConfig("akka.kafka.consumer");
final ConsumerSettings<String, String> consumerSettings =
ConsumerSettings.create(conSumeConfig, new StringDeserializer(), new StringDeserializer())
.withBootstrapServers(testKafkaServer)
.withGroupId(testGroup)
.withProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true")
.withProperty(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "3000")
.withProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
String topic = "test-1";
//Consumer Setup
Consumer
.plainSource(
consumerSettings,
Subscriptions.topics(topic))
.to(Sink.foreach(msg ->
debugKafkaMsg(msg.key(), msg.value(), greetActor, testKey))
)
.run(system);
//Producer Setup
CompletionStage<Done> done =
Source.range(1, testCount)
.map(number -> number.toString())
.map(value -> new ProducerRecord<String, String>(topic, testKey, value))
.runWith(Producer.plainSink(producerSettings), system);
//Producer Task Setup
Source<Done, NotUsed> source = Source.completionStage(done);
within(
Duration.ofSeconds(10),
() -> {
Sink<Done, CompletionStage<Done>> sink = Sink.foreach(i ->
System.out.println("생산완료")
);
//For Clean Test - 3초후 메시지생성
expectNoMessage(Duration.ofSeconds(3));
// Kafka 생산시작
source.runWith(sink, system);
// Kafka 소비 메시지 확인(100)
for (int i = 0; i < testCount; i++) {
probe.expectMsg(Duration.ofSeconds(5), "world");
}
return null;
});
}
};
}
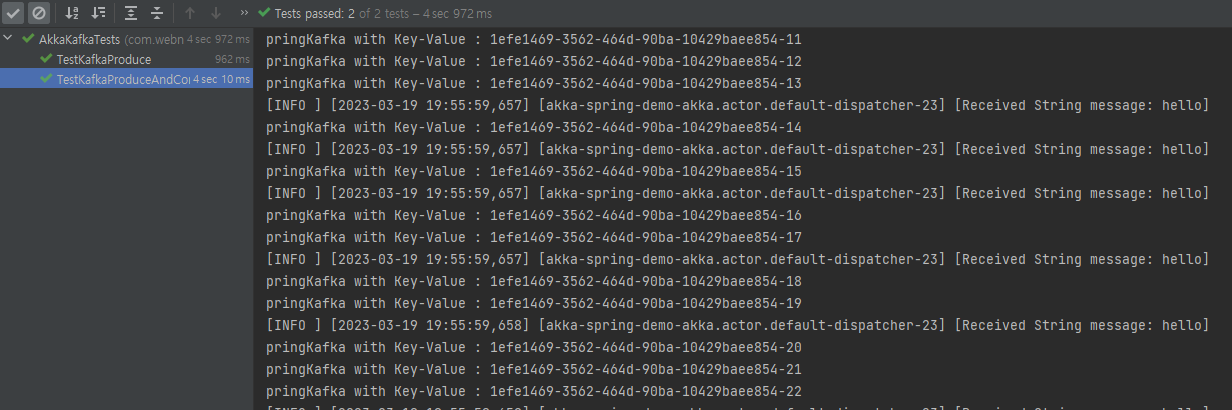
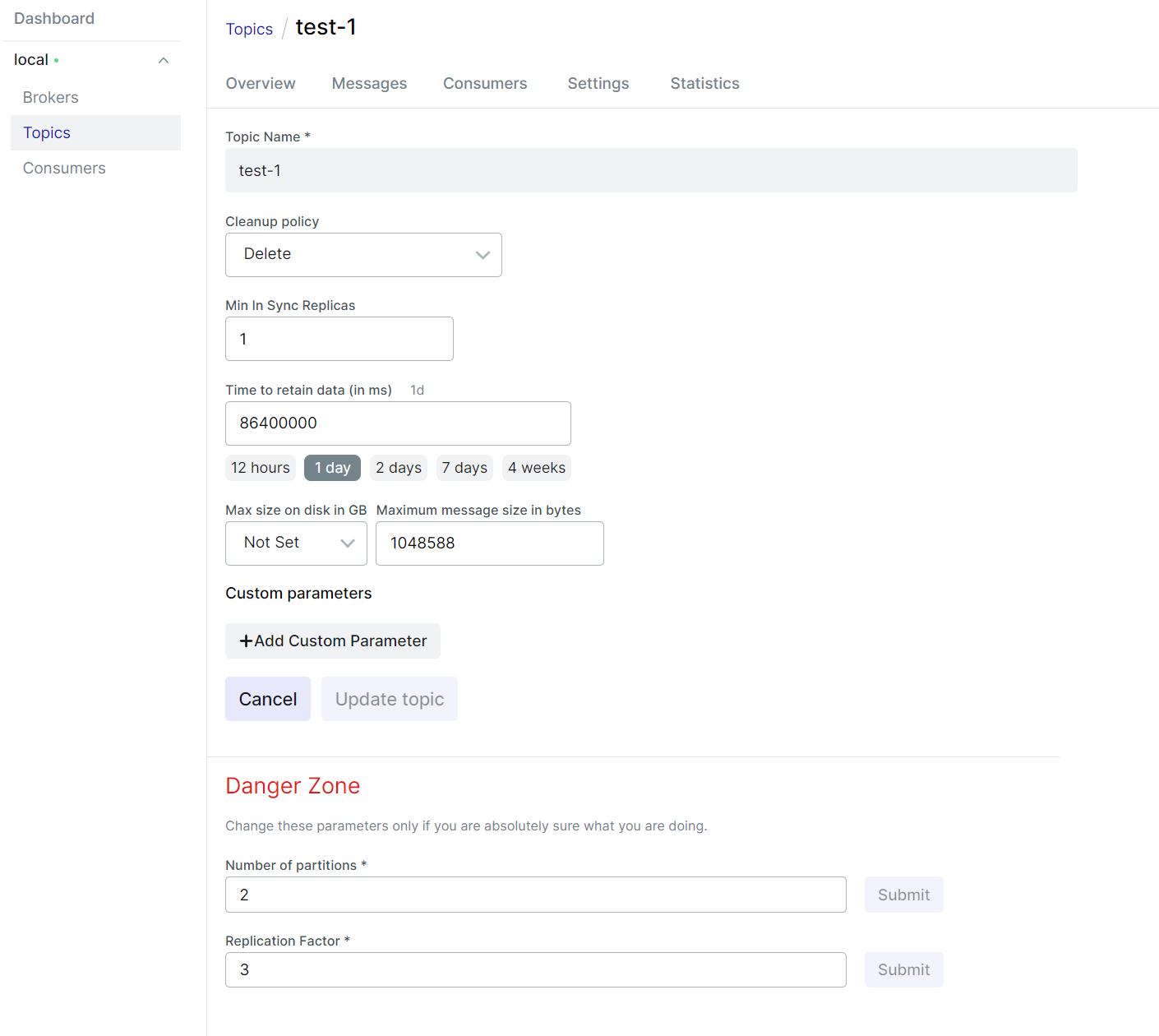
단일토픽 멀티 파티션
이 테스트기의 목적은 AkkaStream을 탑재하여 작동코드를 테스트 해볼수 있지만, Kafka를 이용하기 위해 꼭 이 스트림기를 이용할 필요는 없습니다.
Kafka를 활용하는 방법은 다양할수 있으며 Kafka의 고급옵션들이 실제 의도된대로 작동하는지 Kafka 작동을 확인할수 있는 학습용도로만 이용할수도 있습니다.
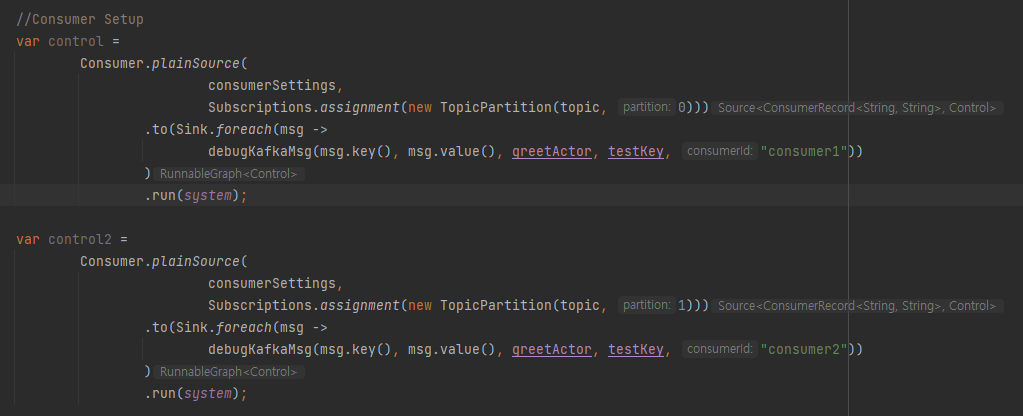
// Kafka 생산시작
source.runWith(sink, system); //파티션 0
source2.runWith(sink, system); //파티션 1
// Kafka 소비 메시지 확인 -
for (int i = 0; i < testCount * partitionCount; i++) {
probe.expectMsg(Duration.ofSeconds(5), "world");
}
단일 토픽에 파티션을 N개 소비테스트가 필요할때 파티션 지정을 하여 N개 구동할수 있습니다.
N개의 소비자를 작동 할수 있으며 총 생산 메시지를 검증할수 있습니다.
지원되는 Consumer Type : https://doc.akka.io/docs/alpakka-kafka/current/consumer.html
카프카 옵션
# Properties for akka.kafka.ProducerSettings can be
# defined in this section or a configuration section with
# the same layout.
akka.kafka.producer {
# Config path of Akka Discovery method
# "akka.discovery" to use the Akka Discovery method configured for the ActorSystem
discovery-method = akka.discovery
# Set a service name for use with Akka Discovery
# https://doc.akka.io/docs/alpakka-kafka/current/discovery.html
service-name = ""
# Timeout for getting a reply from the discovery-method lookup
resolve-timeout = 3 seconds
# Tuning parameter of how many sends that can run in parallel.
# In 2.0.0: changed the default from 100 to 10000
parallelism = 10000
# Duration to wait for `KafkaProducer.close` to finish.
close-timeout = 60s
# Call `KafkaProducer.close` when the stream is shutdown. This is important to override to false
# when the producer instance is shared across multiple producer stages.
close-on-producer-stop = true
# Fully qualified config path which holds the dispatcher configuration
# to be used by the producer stages. Some blocking may occur.
# When this value is empty, the dispatcher configured for the stream
# will be used.
use-dispatcher = "akka.kafka.default-dispatcher"
# The time interval to commit a transaction when using the `Transactional.sink` or `Transactional.flow`
# for exactly-once-semantics processing.
eos-commit-interval = 100ms
# Properties defined by org.apache.kafka.clients.producer.ProducerConfig
# can be defined in this configuration section.
kafka-clients {
}
}
akka.kafka.consumer {
enable.auto.commit = true
kafka-clients {
bootstrap.servers = "localhost:9092"
}
}
akka.kafka.committer {
# Maximum number of messages in a single commit batch
max-batch = 1000
# Maximum interval between commits
max-interval = 3s
# Parallelsim for async committing
parallelism = 100
# API may change.
# Delivery of commits to the internal actor
# WaitForAck: Expect replies for commits, and backpressure the stream if replies do not arrive.
# SendAndForget: Send off commits to the internal actor without expecting replies (experimental feature since 1.1)
delivery = WaitForAck
# API may change.
# Controls when a `Committable` message is queued to be committed.
# OffsetFirstObserved: When the offset of a message has been successfully produced.
# NextOffsetObserved: When the next offset is observed.
when = OffsetFirstObserved
}
final Config conSumeConfig = system.settings().config().getConfig("akka.kafka.consumer");
final ConsumerSettings<String, String> consumerSettings =
ConsumerSettings.create(conSumeConfig, new StringDeserializer(), new StringDeserializer())
.withBootstrapServers(testKafkaServer)
.withGroupId(testGroup)
.withProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true")
.withProperty(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "3000")
.withProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
카프카의 옵션을 기본값으로 정의할수 있으며 코드를 통해 특정(생산/소비/커밋방식) 작동만 변경할수 있습니다.
보너스편 - ChatGPT에게 작성한 유닛테스트 코드를 분석의뢰
요즘 ChatGPT가 설명을 더 잘한는것 같아 보너스로 분석 의뢰를 해보았습니다.
Q> 위 코드를 분석해죠
ChatGPT> 이 코드는 Akka-Streams와 Akka-Kafka를 사용하여 Kafka 프로듀서 및 컨슈머를 테스트하는 것입니다.
첫 번째 테스트인 "TestKafkaProduce"에서는 Kafka 프로듀서를 생성하고 1에서 100까지의 메시지를 생성하여
Kafka에 기록하고 작업이 완료되면 Kafka 컨슈머를 시작하여 기록한 메시지를 확인합니다. 메시지가 성공적으로 처리되면 "hello"라는 메시지를 Akka 액터에게 보냅니다.
두 번째 테스트 "TestKafkaProduceAndConsume"에서는 Kafka 프로듀서를 생성하고 1에서 100까지의 메시지를 생성하여 Kafka에 기록합니다
. 그런 다음 Kafka 컨슈머를 시작하고 Kafka에서 생성한 메시지를 확인하여 모든 메시지가 성공적으로 처리되었는지 확인합니다. 이 과정에서 "hello"라는 메시지를 Akka 액터에게 보내어 확인합니다.
Kafka 개발을 위한 선택
Akka가 JAVA호환이기도 하지만 Scala 기반으로 작성되었기때문에 JAVA와 SCALA의 언어스펙 차이 따라 동일기능을 수행하더라도 JAVA코드로 작성된 코드가 가독성이 떨어지고 복잡합니다.
오히려 자바보다 닷넷으로 포팅된 AKKA가 SCALA작성법과 유사하며
참고 : https://getakka.net/community/contributing/porting-guide.html
AKKA의 Reactive지원이 강력하긴하지만 JAVA SPRING에서의 KAFKA 활용 구현체의 난이도를 낮추는 것은 Webflux를 대안으로 추천합니다.
참고링크 :
- https://github.com/psmon/java-labs/tree/master/springweb/src/test/java/com/webnori/springweb/akka - AKKA Unit Test
- https://doc.akka.io/docs/akka/current/stream/stream-flows-and-basics.html - Akka Stream
- https://doc.akka.io/docs/alpakka/current/index.html - alpakka
- https://alpakka.getakka.net/ - 닷넷 진영 alpakka
- kafka and akka.net - 닷넷진영에서 활용할수 있는 유사샘플 (웹노리 컨텐츠 )