JPA의 컨셉은 Java Persistence API 의 약자로 데이터 베이스에 존재하는 모델을
자바객체로 맵핑하는데 목적이 있습니다. DB는 종속적이지 않게 여러가지 DB 선택이가능하며
여기서는 단지 MYSQL을 통해 실습이 진행됩니다.
설명을 위해, 축약된 코드로 설명을 하였으며, 풀소스는 아래에서 확인가능합니다.
CodeLink : http://git.webnori.com/projects/WEBF/repos/spring_jpa/browse
접속 DB 설정
# application.properties spring.jpa.hibernate.ddl-auto=update spring.datasource.url=jdbc:mysql://localhost:3306/spring spring.datasource.username=test spring.datasource.password=test1234
spring.jpa.hibernate.ddl-auto 옵션
noneDataBase구조 변경에 관여하지 않지않기때문에, DB 모델과 Code모델을 맞추어놓아야합니다.
updateJPA에서 정의한 데이터모델과, 실제 데이터베이스의 모델에 변경이 있을때 반영됩니다.create매번 데이터베이스를 생성하지만, 어플리케이션이 닫힐때 드롭하지 않습니다.create-drop매번 데이터베이스를 생성하고, 세션이 닫힐때 자동으로 데이터베이스를 드롭합니다.
Data Model(Entity) 생성
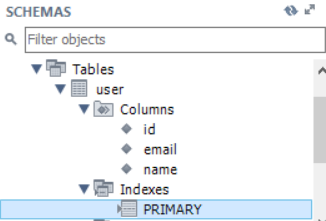
실제 DataBase에서는 위와같은 테이블이, 어플리케이션 시작시 자동 생성됩니다.
JPA에서 class를 통해 테이블을 정의할때 몇가지 규칙이 있습니다.
- 헝가리 표기안법을 따릅니다. ( 첫글자가 대문자) 만약 Class명이 SampleTable 이라고 하면 실제 테이블명인 sample_table로 변환되게 됩니다.
- 컬럼명은 카멜 표기법을 따릅니다. ex> sampleName
- 이미 존재하는 테이블및 컬럼을 참조하여 규칙이 다를시 @Table(name=”SAMPLE_TABLE”) @Column(name = “COLUMN_NAME”) 어노테이션을 통해 해결가능
CRUD 저장소생성
전통적인 DataBase를 통한 개발방법은, SQL을 직접이용하거나, 주로 SP를 이용하여 Table의 정보를 읽거나 변경을 하였습니다.
JPA에서는 CrudRepository를 이용하여 조금더 객체 지향접근방식을 통해 Database를 제어할수가 있습니다.
User 란 테이블을 제어하는 객체를 정의하기 위해서, 여기서는 UserRepository 라고 정의를 하였습니다.
package com.psmon.springdb;
import org.springframework.data.repository.CrudRepository;
//This will be AUTO IMPLEMENTED by Spring into a Bean called userRepository
//CRUD refers Create, Read, Update, Delete
public interface UserRepository extends CrudRepository<User, Long> {
}
CRUD를 이용하여 데이터 제어하기
CURD를 이용한 데이터제어를 유닛테스트기를 이용하여 테스트해보겠습니다.
간단하게 사용자를 추가하고, 조회를 하는 코드입니다.
위 코드를 SQL문으로 변환하면 아래와 같으며, 위코드는 실제 아래와같은
SQL문을 실행합니다.
JPA를 활용했을때 장점은, 일괄적인 객체접근을 통해 데이터모델을 핸들링 할수가 있다란 것이며
일반적으로 소스와 통합이 되기때문에 SP이 필요없이 형상관리가 될수 있다란것이며
데이터 모델이 고정적이지 않고 복잡한 SQL문 혹은 조인이 사용이 되는 데이터 추출에서는 권장되지 않습니다.
JPA Relation
일반적으로 DB의 테이블은 하나의 테이블에 모든 정보를 포함하지 않고, 데이터의 효율적인 관리를 위해서 몇개의 테이블구조로
나누게 됩니다. 이렇게 구조적으로 나뉜 테이블을 맵핑을 하여 하나의 테이블정보인것처럼 처리를 하려면 SQL문에서는 JOIN문으로 해결하며
JPA 객체처리모델에서는 SQL문의 JOIN문에서 해방을 하여 동일한 효과를 내려고 합니다.
그 목적을 달성하기위해 데이터베이스와 객체지향의 몇가지 차이점을 알아야합니다.
class User{
int id;
string name;
string email;
}
class ClickLog{
int clickid;
User user; //데이터베이스에서는 userid가 저장됨
string clickurl;
}
- 프로그래밍모델에서 객체는 일반적으로 단방향 접근이 허용이 됩니다. ( ClickLog→ User )
- 데이터 베이스는 Join문을 통해 양방향 접근이 가능합니다.( User ↔ ClickLog )
- 프로그래밍 모델에서는 상속의 개념이 있지만, 데이터베이스 에서는 존재하지 않습니다.
이와같은 차이를 극복하고, 데이터베이스의 Table을 객체지향적 인 모델로 변경을 하려면 JPA에서 지원하는
관계(Relation)을 형성(Join)하는 몇가지 키워드의 의미를 알아야합니다.
- ManyToOne : 다대일 관계 매칭정보
- JoinColumn : 외래키를 매핑때 사용함
- mappedBy : 연관관계설정시 주인이 아님을 설정
- OneToMany : 일대다 관계 매핑정보
- OneToOne : 일대일 관계 매칭정보, 어느곳이나 외래키를 가짐
- ManyToMany : 다대다 관계매칭정보, 맵핑테이블을 만들어서 사용하기를 권장
- 연관관계주인 : 외래키가 있는곳이 주인이며 주인만이 수정가능 아닌경우 조회만가능
ManyToOne ( 다대일 )
위 샘플에서 사용자(User) 데이터 모델링에서, 사용자가 속한 그룹을 표한하는 테이블을 추가해보겠습니다.
여러명의 사용자는 한개의 그룹에 속할수 있기때문에, 사용자의 입장에서 다대일 입니다.
즉 사용자의 모델링에서만.., 다대일 설정을 그룹 정보와 맺어주면됩니다.
SQL MODE
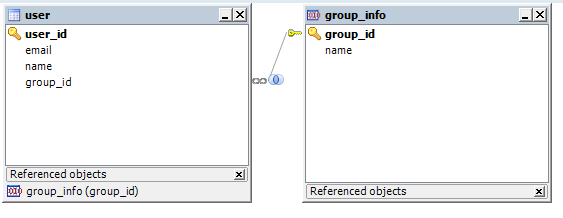

우리가 원하는 테이블 모델링은 위와같을 모습이며, user테이블에 group_id가 외래키로 설정이 되어있습니다.
어플리케이션에서 레거시한 제어를 모두한다고 하면, 이러한 외래키 설정이 필요없을수도 있으나
데이터 무결성의 입장에서 중요한 설정이며, JPA 사용시 외래키를 직접 지정하지는 않지만
JPA에서 Relation을 사용하면, 상황에따라 외래키설정이 자동으로 됩니다.
JPA MODE
OneToMany
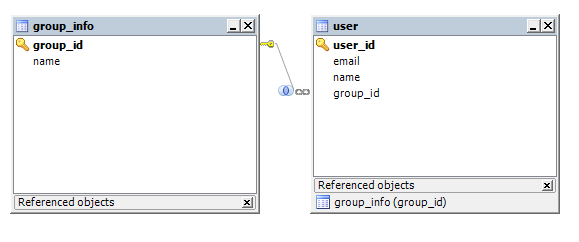
테이블구조는 변함이 없으며 접근 방식을 ManytoOne에서 OneToMany로 변경을 하여 객체지향접근방식으로
접근해보겠습니다. Group을 핸들링하고 User는 리스트처럼 사용하는것을 시도해보겠습니다.
SQL MODE
DB는 구조상, 하나의 테이블에서 서브 List형태의 데이터를 가질수가 없습니다.
각각의 테이블에서 그룹정보 / 사용자정보를 각각 입력해야하며 .. 조회시 Join을 통해
그룹정보가 사용자리스트를 가진것처럼 핸들링을 할수 있을뿐이며, 외래키를 통해
실제 이러한 구조에 무결성을 유지할수가 있습니다.
전통적인 방식에서는 대략 아래와같이, 처리하였을것입니다.
JPA MODE
JPA에서의 목적은, 기존 SQL에서 처리하는 방식을 객체지향적으로 변경하는것입니다.
그리고 중요한것은 기존 데이터 모델의 관계(외래키관계)를 그대로 유지하는것입니다.
Join에서 해방되고, 외래키 설정같은것을 신경쓸필요가 없으나...
우리는 아래코드가 외래키도 설정도 실제로하고 Join명령을 통해 FindByname이 작동이 된다란
사실은 알고 있어야합니다.
- cascade : 속성값에는 CascadeType라는 enum에 정의 되어 있으며 enum값에는 ALL, PERSIST, MERGE, REMOVE, REFRESH, DETACH가 있습니다.
- targetEntity : 관계를 맺을 Entity Class를 정의합니다.
- fetch : FetchType.EAGER, FetchType.LAZY로 전략을 변경 할 수 있습니다. 두 전략의 차이점은 EAGER인 경우 관계된 Entity의 정보를 미리 읽어오는 것이고 LAZY는 실제로 요청하는 순간 가져오는겁니다.
- mappedBy : 양방향 관계 설정시 관계의 주체가 되는 쪽에서 정의합니다.
- orphanRemoval : 관계 Entity에서 변경이 일어난 경우 DB 변경을 같이 할지 결정합니다. cascade와 다른것은 cascade는 JPA 레이어 수준이고 이것은 DB레이어에서 처리합니다. 기본은 false입니다.
위 테스트 코드는, 각각의 그룹을 생성을 하고 일괄적인 방법으로 사용자를 추가하였습니다.
마지막에는 Join문 필요없이 학생그룹의 사용자들의 목록을 읽어온는 함수를 실행하였습니다.
일반적으로 사용자에 반응을 하여 1건의 자료 처리가 되는 방식에서 위와같이 한꺼번에
데이터를 넣을 일은 없을것이나, Insert처리 조회처리를 일괄적이고 효과적인 방법으로 할수 있다란
예일뿐입니다.