액터모델의 메일박스로 통해 전달되는 이벤트들은 다양한 DB장치를 이용해 영속화가 가능하며 상태프로그래밍을 할수 있습니다.
RDB,MongoDB,ElasticSearch등 다양한 특징을 가진 전통강호 영속장치를 이용해 각각 특화된 기능을 이용할수 있겠지만
이러한 기능을 한방에 보편적으로 이용할수 있는 장치가 없을까 조사하다 발견한 DB로 Akka를 연구하는 NetCorelabs에 변종실험 대상으로 추가하였습니다.
데이터베이스는 지루하면 안된다라는 슬로건을 내건 모던 DB
AI OPS 등장

AI 를 활용하는 AI OPS의 등장으로 MSA의 API GateWay는 Context Gateway로 전환을 준비하고 기중중심에서 문맥중심으로 활용해야할 DB와 인프라는 더 복잡해자고
활용 해야할 DB는 더 늘어나고 복잡해지고 더 많은 스트림 이벤트를 처리하면서 인프라사용증가는 불가피할것으로 보여집니다.
🧠 AI 시대, 데이터베이스는 지루하지 않아야 한다
"데이터베이스는 지루하면 안 된다."
이것은 RavenDB가 내세운 모토입니다. 이 슬로건은 단순한 마케팅 문구가 아니라, AI와 데이터 중심의 시대에서 우리가 겪고 있는 복잡성에 대한 직설적인 반응입니다.
📈 복잡해지는 데이터 아키텍처
오늘날 AI 기반 서비스, 특히 RAG(Retrieval-Augmented Generation)를 구축하려면 단순히 전통적인 RDBMS만으로는 부족합니다. 보통 다음과 같은 데이터베이스들이 함께 필요해집니다:
✅ RDB: 정형화된 트랜잭션 데이터 저장
🔍 ElasticSearch: 실시간 검색 및 로그 분석
📄 MongoDB: 문서 기반의 유연한 저장
🔗 Neo4j: 그래프 기반의 관계 분석
🧠 Vector DB: 임베딩 기반의 유사도 검색
이 조합은 "기능 최적화"라는 이름으로 합리화되지만, 실상은 데이터 이동, 변환, 파이프라이닝이라는 복잡성을 끌어안게 됩니다. 이는 규모 있는 조직에는 ‘가능한 선택’일지 몰라도, 소규모 팀에게는 감당하기 어려운 난제입니다.
⚠️ 스타트업이 마주하는 현실
대기업은 이미 데이터 엔지니어링 팀과 ETL 파이프라인을 갖추고, 이를 기반으로 AI 역량을 확대해나갑니다. 그러나 스타트업은?
핵심 서비스를 개발하면서
데이터 ETL 파이프라인을 설계하고
각기 다른 DB와 연동하며
클라우드 인프라 비용을 관리하는 일까지
"모든 것을 동시에 잘하는 것"은 사실상 불가능합니다.
☁️ 클라우드로는 충분할까?
클라우드는 NoSQL 연동, ETL 도구, 매니지드 인프라까지 제공합니다. 하지만 서비스가 커질수록 사용량 기반 요금은 제어하기 어려운 비용 폭탄으로 돌아옵니다. 단순한 아키텍처가 아니라면, 복잡한 아키텍처를 클라우드에 옮긴다고 해서 복잡성이 줄어들지는 않습니다.
🧩 RavenDB가 주는 메시지
RavenDB는 전통 RDB와 NoSQL, 문서 저장, 분산처리를 아우르며 하나의 DB로 다중 기능을 흡수하려는 전략을 택했습니다. 이는 기술적으로도, 비즈니스 전략적으로도 다음을 의미합니다:
하나의 DB, 하나의 파이프라인
ETL 부담 최소화
AI 및 RAG 연계도 간단히 구성
운영 복잡도와 인프라 비용 절감
**“모든 기능을 외부에 위임하기보다, 핵심 기능은 내부로 끌어안자”**는 전략이자, 작지만 강력한 조직이 선택할 수 있는 현실적인 대안입니다.
🔮 AI-Native 아키텍처 시대, 데이터 전략은?
다가오는 AI-Native 아키텍처에서는 다음과 같은 키워드들이 중심이 됩니다:
| 키워드 | 설명 |
|---|---|
| AI-Native | AI가 모든 서비스의 기본 흐름을 주도 |
| Context-Aware | 사용자와 상황에 따른 반응적 설계 (MCP 등) |
| Event-Driven | 모든 변화가 이벤트로 감지 및 처리됨 |
| Composable | 기능을 블록처럼 유연하게 조립 |
| Autonomous Ops | 자동화된 인프라 운영 및 복구 |
| Multi-Agent | 분산된 AI 에이전트들의 협업 |
이런 시대에 데이터 인프라는 더욱 **문맥 중심(Context-Aware)과 이벤트 중심(Event-Driven)**으로 진화합니다. 그리고 그것은 더 많은 DB, 더 많은 이벤트, 더 복잡한 흐름을 의미합니다.
✅ 우리는 모든 것을 다룰 필요는 없다
전통 RDB가 계속해서 NoSQL 기능을 흡수하고 진화하고 있듯이, 모든 DB를 조합해 구축하는 시대는 AI처럼 빠르게 지나갈 수 있습니다.
AI 기술의 대중화는 인프라 복잡성을 가리는 화려한 조명이지만, 지속 가능한 아키텍처는 단순함에서 출발해야 합니다.
하나의 DB로 문서, 트랜잭션, 검색, 분석, 분산처리까지 아우를 수 있다면?
복잡성은 줄고, 핵심 서비스에 집중할 수 있습니다.
그리고 그것이 AI 시대, 지루하지 않은 데이터베이스가 가져다주는 진짜 가치입니다.
전통적 DB가 왜 지루하지? 의미분석과정중 GPT가 생성해낸 글이긴하지만 복잡한 DB를 모두 알아야했고ETL 파이프라인을 구축하는데 많은시간과 힘을빼기도 했습니다.
본론으로 들어가 RavenDB의 특징과 사용법 그리고 Akka.net에서의 확장 사용법을 간단하게 알아보겠습니다.
✅ RavenDB 특징
| 항목 | 설명 |
|---|---|
| Document Store | JSON 기반의 문서 저장 (MongoDB처럼) |
| Full-Text Search 내장 | Lucene 기반 검색엔진 포함 (Elasticsearch 대체 가능) |
| Graph-Like Traversal 지원 | Include, Load, RelatedDocuments 로 Graph traversal 흉내 가능 |
| 벡터 검색 (Vector Search) | 6.0 이상 버전에서 Vector search 지원 (Preview → Stable 예정) |
| ACID 트랜잭션 지원 | NoSQL 중 드물게 단일 DB 내 ACID 지원 |
| 자동 인덱싱/쿼리 최적화 | 쿼리 기반으로 자동 인덱싱 생성 |
| Change Vector / ETL 기능 내장 | 다른 Raven 클러스터 또는 외부 시스템으로 데이터 복제 가능 |
| 클라우드 + 온프렘 지원 | 다양한 배포 환경 대응 |
| Sharding + Replication | 분산 구조 대응 가능 (Sharded DB) |
✅ 기존 DB 구성 중 대체 가능한 역할
| 기존 시스템 | RavenDB로 대체 가능 여부 | 설명 |
|---|---|---|
| MongoDB (Document DB) | ✅ 완전 대체 | JSON 기반 문서 저장, 컬렉션 → 문서 분리 모델 |
| Elasticsearch | ✅ 부분 대체 | Full-text 검색 지원, 복잡한 분석쿼리는 제한적이나 일반 검색에는 충분 |
| Neo4j (Graph DB) | ⚠️ 간단한 관계 트래버설은 가능 | 명시적 Graph 모델링은 어려움 (복잡한 네트워크 분석에는 부적합) |
| Vector DB (예: Weaviate, Milvus) | ✅ 단순 벡터 검색은 대체 가능 | 다차원 벡터 검색 API 제공, 모델링+쿼리 결합 쉬움 |
| RDB (CRUD/정형) | ⚠️ 단순 CRUD는 가능, 복잡한 조인과 트랜잭션은 제한적 | 정형 테이블 기반보다는 문서 중심 모델 필요 |
RabenDB Docker StandAlone 구동
version: '3.8'
services:
ravendb:
image: ravendb/ravendb:ubuntu-latest
container_name: ravendb
ports:
- "9000:8080"
environment:
- RAVEN_Setup_Mode=None
- RAVEN_License_Eula_Accepted=true
volumes:
- ravendb_data:/ravendb/data
- ravendb_logs:/ravendb/logs
volumes:
ravendb_data:
ravendb_logs:
- 클라우드로도 이용가능하며~ 로컬또는 온프레미스로도 운영가능합니다.
IDE 환경
- Docker와 통합된 IDE환경으로 RavenDB 구동
RavenDB 웹관리툴
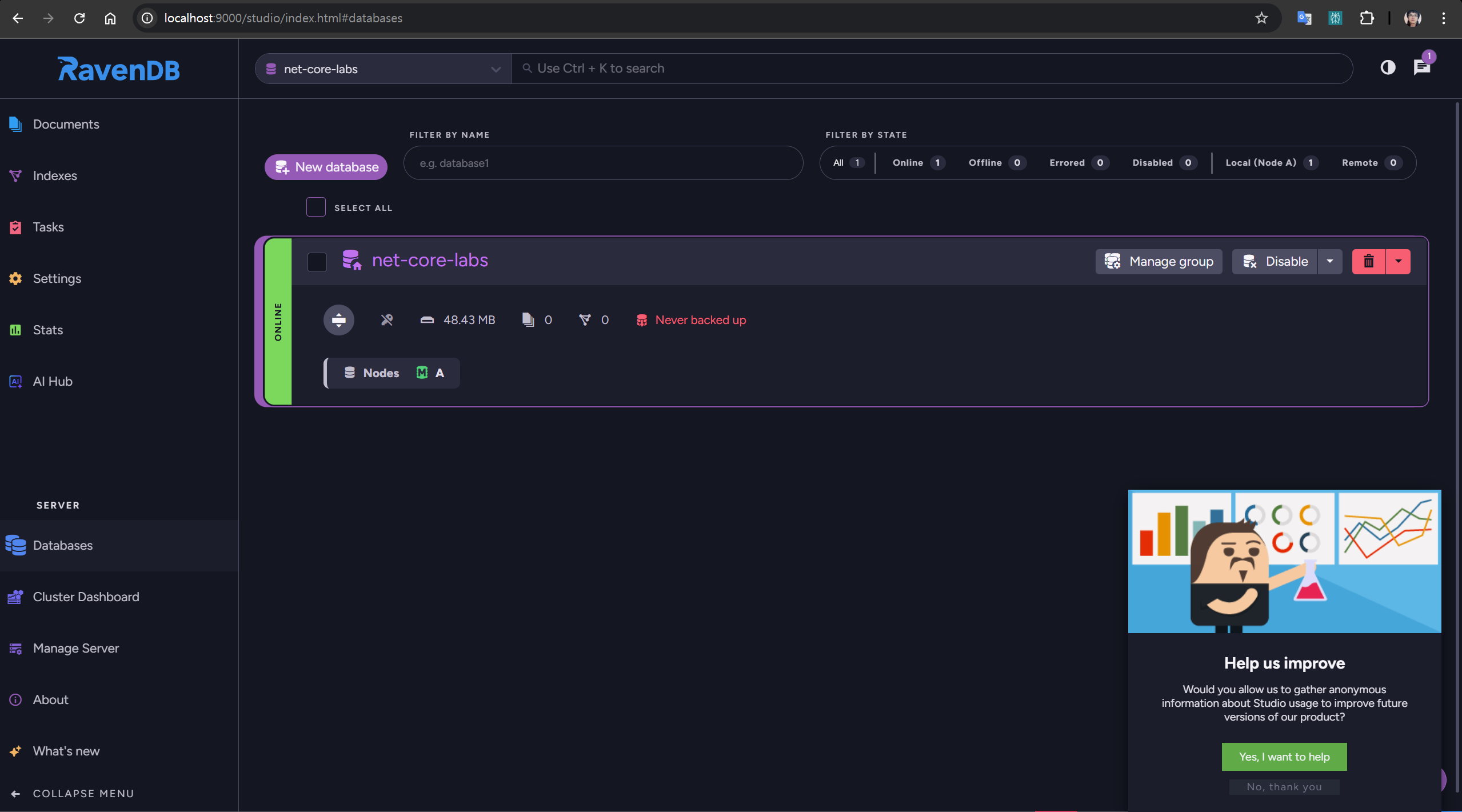
- DB를 관리할 웹툴을 포함하며 기본적인 관리가 가능합니다.
- IDE내에서 연동돠는 플러그인은 아직 없어보입니다.
- Postgres 호환플러그인을 지원하니 BI툴및 IDE내 기본조회연동은 가능할듯
언어별 지원 클라이언트

- Akka.net을 연계해 사용예정이기때문에 .NET 기반실험이 진행되었습니다.
RabenClient for .NET
- 설치된 서버 Mazor버전과 맞춰서 패키지 설치
Database생성
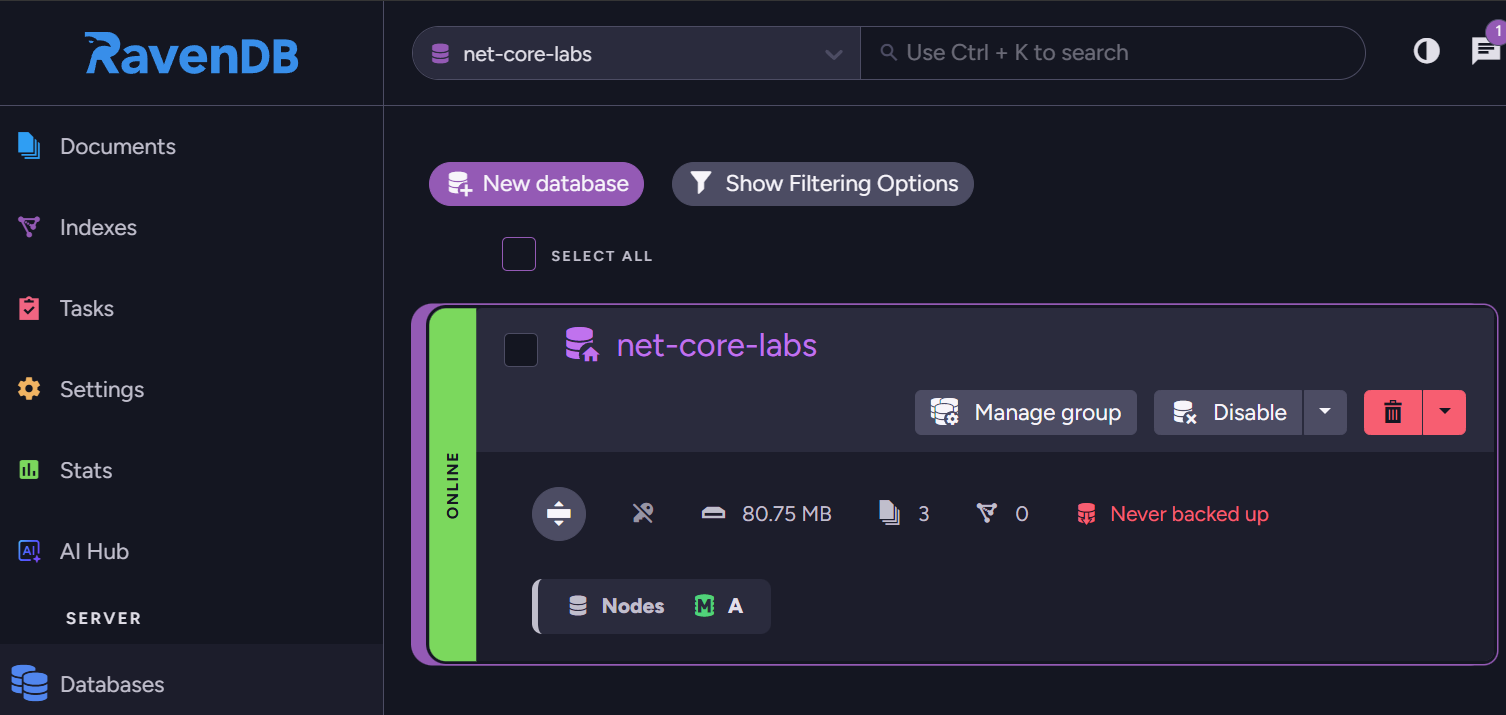
몽고DB와 유사하게 스키마리스 DB이기때문에 DDL코드가 필요로 하지 않습니다.
Repository 코드
public class Member
{
public string Id { get; set; } // RavenDB는 기본적으로 Id를 문서 키로 사용
public string Name { get; set; }
public string Email { get; set; }
public int Age { get; set; }
}
public class MemberRepository
{
private readonly IDocumentStore _store;
public MemberRepository(IDocumentStore store)
{
_store = store ?? throw new ArgumentNullException(nameof(store));
}
public void AddMember(Member member)
{
using (var session = _store.OpenSession())
{
session.Store(member);
session.SaveChanges();
}
}
public Member GetMemberById(string id)
{
using (var session = _store.OpenSession())
{
return session.Load<Member>(id);
}
}
public void UpdateMember(Member member)
{
using (var session = _store.OpenSession())
{
var existingMember = session.Load<Member>(member.Id);
if (existingMember != null)
{
existingMember.Name = member.Name;
existingMember.Email = member.Email;
existingMember.Age = member.Age;
session.SaveChanges();
}
}
}
public void DeleteMember(string id)
{
using (var session = _store.OpenSession())
{
var member = session.Load<Member>(id);
if (member != null)
{
session.Delete(member);
session.SaveChanges();
}
}
}
}
CRUD TEST 코드
public class MemberRepositoryTest : TestKitXunit
{
private readonly IDocumentStore _store;
private readonly MemberRepository _repository;
public MemberRepositoryTest(ITestOutputHelper output) : base(output)
{
// RavenDB 임베디드 서버 초기화
_store = new DocumentStore
{
Urls = new[] { "http://localhost:9000" }, // 로컬 RavenDB URL
Database = "net-core-labs"
};
_store.Initialize();
// MemberRepository 초기화
_repository = new MemberRepository(_store);
}
[Fact]
public void AddMember_ShouldAddMemberSuccessfully()
{
// Arrange
var member = new Member
{
Name = "John Doe",
Email = "john.doe@example.com",
Age = 30
};
// Act
_repository.AddMember(member);
// Assert
var retrievedMember = _repository.GetMemberById(member.Id);
Assert.NotNull(retrievedMember);
Assert.Equal("John Doe", retrievedMember.Name);
}
[Fact]
public void UpdateMember_ShouldUpdateMemberSuccessfully()
{
// Arrange
var member = new Member
{
Name = "Jane Doe",
Email = "jane.doe@example.com",
Age = 25
};
_repository.AddMember(member);
// Act
member.Age = 26;
_repository.UpdateMember(member);
// Assert
var updatedMember = _repository.GetMemberById(member.Id);
Assert.NotNull(updatedMember);
Assert.Equal(26, updatedMember.Age);
}
[Fact]
public void DeleteMember_ShouldDeleteMemberSuccessfully()
{
// Arrange
var member = new Member
{
Name = "Mark Smith",
Email = "mark.smith@example.com",
Age = 40
};
_repository.AddMember(member);
// Act
_repository.DeleteMember(member.Id);
// Assert
var deletedMember = _repository.GetMemberById(member.Id);
Assert.Null(deletedMember);
}
}
- 처음 사용하는 DB사용 자체를 연구하고 테스트하는 코드이기때문에 Mocking을 이용하지 않고 로컬구축 DB직접 Access방식이용
테스트 수행및 확인
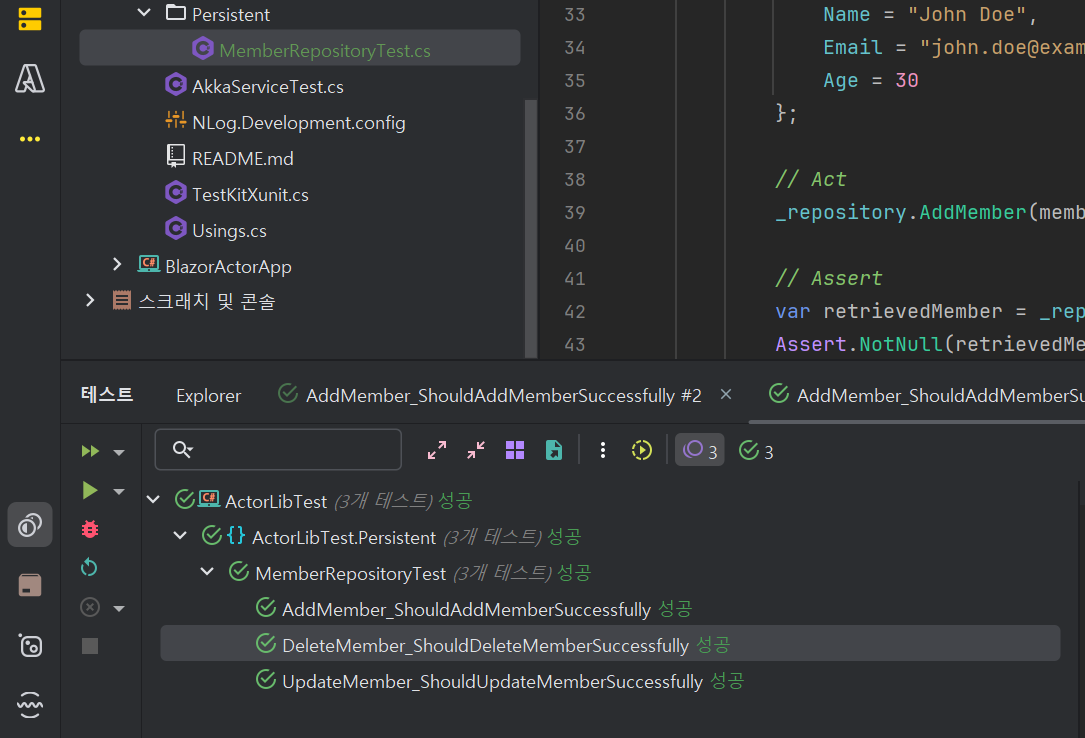

- 비교적 심플한 코드작성으로 CRUD 테스트 수행이 완료되었습니다.
Next - 이벤트드리븐 CQRS로의 여정
ActorModel에 Persist는 CRUD만 파악되면 커스텀하게 디벨롭할수도 있겠지만, akka.net진영과 콜라보로 공식 지원을 합니다.
- https://ravendb.net/docs/article-page/7.0/csharp/integrations/akka.net-persistence/integrating-with-akka-persistence - RavenDB with Akka.net
- https://github.com/psmon/NetCoreLabs - 이 아티컬에서 실험코드를 확인및 수행할수 있으며, RavenDB를 통해 CQRS변종실험을 이어갈예정입니다.