Page History
...
| Code Block | ||||||||
|---|---|---|---|---|---|---|---|---|
| ||||||||
CREATE TABLE `group_info` (
`group_id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) COLLATE utf8_bin DEFAULT NULL,
PRIMARY KEY (`group_id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
CREATE TABLE `user` (
`user_id` int(11) NOT NULL AUTO_INCREMENT,
`email` varchar(255) COLLATE utf8_bin DEFAULT NULL,
`name` varchar(255) COLLATE utf8_bin DEFAULT NULL,
`group_id` int(11) DEFAULT NULL,
PRIMARY KEY (`user_id`),
KEY `FKa36i4ekojwk70bxen390i6tek` (`group_id`),
CONSTRAINT `FKa36i4ekojwk70bxen390i6tek` FOREIGN KEY (`group_id`) REFERENCES `group_info` (`group_id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8 COLLATE=utf8_bin; |
...
| Code Block | ||||||||
|---|---|---|---|---|---|---|---|---|
| ||||||||
@Autowired
private GroupRepository groupRepository;
@Autowired
private UserRepository userRepository;
GroupInfo newGroup = new GroupInfo();
newGroup.setName("학생");
groupRepository.save(newGroup);
// 사용자 생성
User addUser = new User();
addUser.setName("minsu");
addUser.setEmail("test@x.com");
addUser.setGroupInfo(newGroup);
userRepository.save(addUser);
/*
사용자 조회, select * from user join group_info 와 동일한조회효과를 누릴수 있습니다.
전통적인 처리 방법은 Insert쿼리를 실행하고 다시조회쿼리를 실행하고,그 데이터셋의 결과를 어플리케이션에 가지고와서
사용하기 과정까지 각각 다른 처리코드와 변환과정이 필요했을것입니다.( 테이블을 쿼리로 설계 <-> SQL <-> DataSet <-> Object <-> Json )
Json의 뷰단의 데이터가 하나만 바뀌어도 최대 5가지 수정 포인트에서 코드 수정이 이루어 졌을것입니다.
JPA를 통한 데이터모델링 정의및 데이터제어가 다소 익숙하지않고 SQL문의 자유롭고 복잡한
표현을 모두 표현하기에 어려울수도 있습니다. 현재로서는 일괄적인 단일지점( 객체지향 정의)에서
모두 가능하다란것정도 이해를 해두고 넘어갑시다.
*/
Iterable<User> userList = userRepository.findAll();
userList.forEach(item->System.out.println( String.format("Name:%s GroupName:%s", item.getName(),item.getGroupInfo().getName() ) ));
|
OneToMany
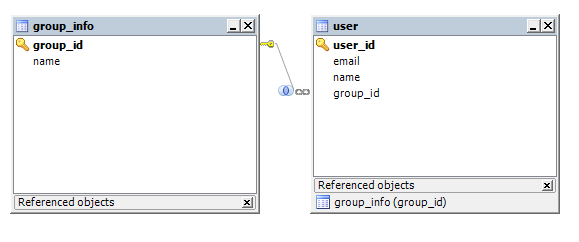
테이블구조는 변함이 없으며 접근 방식을 ManytoOne에서 OneToMany로 변경을 하여 객체지향접근방식으로
접근해보겠습니다. Group을 핸들링하고 User는 리스트처럼 사용하는것을 시도해보겠습니다.
SQL MODE
DB는 구조상, 하나의 테이블에서 서브 List형태의 데이터를 가질수가 없습니다.
각각의 테이블에서 그룹정보 / 사용자정보를 각각 입력해야하며 .. 조회시 Join을 통해
그룹정보가 사용자리스트를 가진것처럼 핸들링을 할수 있을뿐이며, 외래키를 통해
실제 이러한 구조에 무결성을 유지할수가 있습니다.
전통적인 방식에서는 대략 아래와같이, 처리하였을것입니다.
| Code Block | ||||||
|---|---|---|---|---|---|---|
| ||||||
-- 그룹을 추가한다.
INSERT INTO test.group_info(
group_id
,name
) VALUES (
NULL -- group_id - IN int(11)
,'' -- name - IN varchar(255)
)
-- 사용자를 추가할시 그룹을 지정하거나, 나중에 지정한다.
INSERT INTO test.user(
user_id
,email
,name
,group_id
) VALUES (
NULL -- user_id - IN int(11)
,'' -- email - IN varchar(255)
,'' -- name - IN varchar(255)
,0 -- group_id - IN int(11)
)
-- 여러명을 등록할시 위 과정이 반복됩니다.
--학생인 사용자만 조회시..Join을 통해 해결
select * from user join group_info gi on gi.name='학생' |
JPA MODE
JPA에서의 목적은, 기존 SQL에서 처리하는 방식을 객체지향적으로 변경하는것입니다.
그리고 중요한것은 기존 데이터 모델의 관계(외래키관계)를 그대로 유지하는것입니다.
Join에서 해방되고, 외래키 설정같은것을 신경쓸필요가 없으나...
우리는 아래코드가 외래키도 설정도 실제로하고 Join명령을 통해 FindByname이 작동이 된다란
사실은 알고 있어야합니다.
| Code Block | ||||||||
|---|---|---|---|---|---|---|---|---|
| ||||||||
@Entity
public class GroupInfo {
@OneToMany(mappedBy = "groupInfo", cascade = {CascadeType.PERSIST},fetch=FetchType.EAGER)
private Set<User> users;
@Override
public String toString() {
String result = String.format(
"GroupInfo[id=%d, name='%s']%n",
id, name);
if (users != null) {
for(User user : users) {
result += String.format(
"User[id=%d, name='%s']%n",
user.getId(), user.getName());
}
}
return result;
}
}
public interface GroupRepository extends CrudRepository<GroupInfo, Long> {
public GroupInfo findByName(String name);
}
|
- cascade : 속성값에는 CascadeType라는 enum에 정의 되어 있으며 enum값에는 ALL, PERSIST, MERGE, REMOVE, REFRESH, DETACH가 있습니다.
- targetEntity : 관계를 맺을 Entity Class를 정의합니다.
- fetch : FetchType.EAGER, FetchType.LAZY로 전략을 변경 할 수 있습니다. 두 전략의 차이점은 EAGER인 경우 관계된 Entity의 정보를 미리 읽어오는 것이고 LAZY는 실제로 요청하는 순간 가져오는겁니다.
- mappedBy : 양방향 관계 설정시 관계의 주체가 되는 쪽에서 정의합니다.
- orphanRemoval : 관계 Entity에서 변경이 일어난 경우 DB 변경을 같이 할지 결정합니다. cascade와 다른것은 cascade는 JPA 레이어 수준이고 이것은 DB레이어에서 처리합니다. 기본은 false입니다.
| Code Block | ||||||||
|---|---|---|---|---|---|---|---|---|
| ||||||||
GroupInfo newGroupA = new GroupInfo("학생");
Set usersA = new HashSet<User>() {{
add(new User("minsu2","min2@x.com",newGroupA));
add(new User("minsu3","min3@x.com",newGroupA));
}};
newGroupA.setUsers(usersA);
GroupInfo newGroupB = new GroupInfo("선생");
Set usersB = new HashSet<User>() {{
add(new User("tom1","tom1@x.com",newGroupB));
add(new User("tom2","tom2@x.com",newGroupB));
}};
newGroupB.setUsers(usersB);
groupRepository.save(new HashSet<GroupInfo>() {{
add(newGroupA);
add(newGroupB);
}});
GroupInfo groupInfo = groupRepository.findByName("학생");
System.out.println( String.format("학생정보: %s", groupInfo.toString() ) ); |
위 테스트 코드는, 각각의 그룹을 생성을 하고 일괄적인 방법으로 사용자를 추가하였습니다.
마지막에는 Join문 필요없이 학생그룹의 사용자들의 목록을 읽어온는 함수를 실행하였습니다.
일반적으로 사용자에 반응을 하여 1건의 자료 처리가 되는 방식에서 위와같이 한꺼번에
데이터를 넣을 일은 없을것이나, Insert처리 조회처리를 일괄적이고 효과적인 방법으로 할수 있다란
예일뿐입니다.
| Info |
|---|
다른 진영(.net) 에서도 JPA와 유사하게 데이터를 제어하고 있습니다. Entity Framework |
...