Page History
| Info |
|---|
AKKA System은 수많은 Router전략을 지원하지만 L7,Haproxy 를 대체하는 솔류션및 시스템이 아닙니다. 또한 고성능 Data 메모리 처리를 위해 메모리유지 기술을 지원하지만 Redis를 대체하는 시스템도 아닙니다.. 실시간 분산처리를 위해 Cluster-샤딩을 지원하지만 하둡을 대체하는 분산 저장 기술도 아닙니다. 다양한 통신메카니즘을 사용하지만 사용자에게 제공하는 RESTAPI 를 대체하는 프로토콜도 아닙니다. 도대체 이것을 어디다 쓸고? 고민을 해보겠습니다. 자신이 설계한 API가 10노드로 구성했다고 가정했을때 DB또는 외부 API만을 통해 사용자하고만 대화를 할수 있다란것은 아주 큰 개발 제약입니다. NODE1-API 에서 발생한 일을, 자신이 설계한 NODE2-API 또는 동료가 설계한 API와 DB의존없이 실시간으로 대화 할수있는것만으로 어떠한 부분에 대해서는 새로운 서비스를 창출할수가 있습니다. 이러한것을 구현하기위해 직접 커스텀한 로직을 작성해야하며, AKKA는 어떠한 서비스도 제공해주지 않습니다. 고성능 분산서비스 개발을 지원하며 ,주로 서비스내에 특화된 분산처리를 전송 지원하는 개발툴킷입니다. 쉽게 설명하면, 기존 서비스를 처음부터 설계할수도 있지만 동일 개발 프레임워크내에서(자바/C#) 탑재가가능합니다. |
간단한 AKKA 시스템 구성도
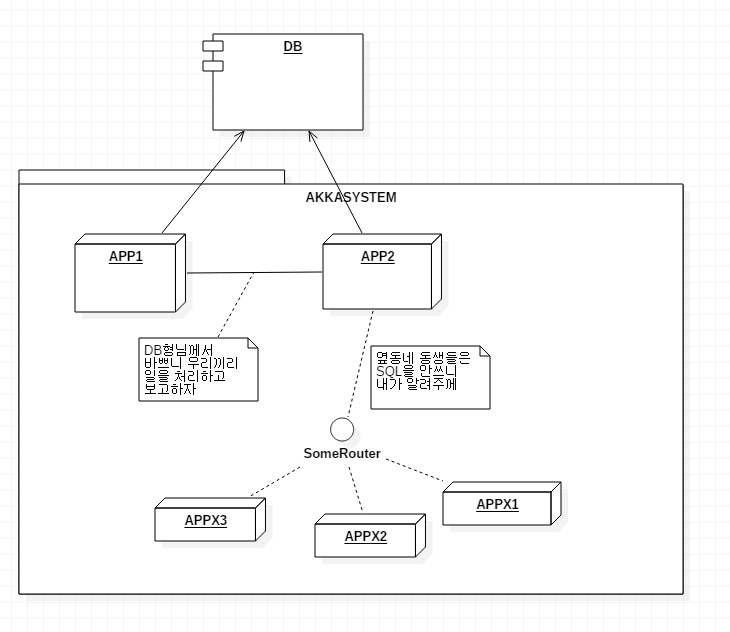
AKKA SYSTEM이란? : Actor를 통해 대화할수 있는 Node,또는 그것이 계층적으로 표현이되는 단위
고급 API 설계
Rest Model과 연동되어, 고급(스케일 업다운/클러스터) API를 설계를한 케이스입니다.
AKKA는 클러스터/분산처리를 단순화할수 있는 툴킷이지만,
무엇을 사용하던 낮은 복잡도와 높은유연성을 동시에 유지하면서 규모를 확장하는것은 어려운 일입니다.
이것은 AKKA의 문제가 아니라, 개발팀 내부에서 이미 고려하지 않거나 이미 포기한 문제일 가능성이 높습니다.
AKKA를 가지고 성공한 플래폼으로 만드는것은 불가능한것이아니라, 어떠한 툴킷을사용하더라도 어렵다는데 그의미가있습니다.
AKKA가 모든 서비스환경에서 만능 해결사가 될수없으나, 분산환경에서의 동시성 문제를 어떻게 풀려고하고 단순화 하는지?
제시한 제안 모델은 분명 다음 프레임워크에서도 좋은 모범사례가 될것입니다.
link:http://www.aaronstannard.com/markedup-akkadotnet/
장애처리 모델(Supervision)
try-catch는 메시지 전송및 구조적 모델에서 적합하지 않는 예외 처리모델입니다.
흐름을, 부자연스럽게 중단하기 때문이며, 실제 서비스코드의 복잡성이
증가하면 예외처리지점을 파악하기 힘들뿐더러, 예외처리코드가 서비스 코드를 역으로
복잡하게 만드는 결과를 가져옵니다.
Akka에서는 몇가지 예외에대한 일괄적인 장애 처리 모델을 지원하고 있습니다.
One-For-One Strategy vs. All-For-One Strategy
c1의 기능이 죽더라도, c2의 기능에의해 전체적인 기능에 문제가 없을시
c1을 다시 살릴지? 말지? 다시 살린다고하면 몇번을 시도할지? 설정화가 가능합니다.
c3에 문제가 있을시, b3 그룹기능에 문제가 있다고 하면.. c3를 살리려는 노력을
해야합니다. 이때 c3를 살리려는 노력이 실패로 돌아가면 b3를 재시작하는
복구전략을 설정화를 통해 복구 전략이 가능합니다. 이것이 아카에서 이야기하는
응용개발자가 복구전략을 직접 설계하게끔 하는 복구력입니다.
link : http://getakka.net/articles/concepts/supervision.html
다양한 라우팅 전략 사용가능
BroadCast
RoundRobin
ConsistentHashRouter
ScatterGatherFirstCompleted
SmallestMailBox Test
Persistence ( 유지성 )
메모리는 빠르지만, 저장용량의 한계와 휘발성의 문제로 중요한 서비스모델에해당하는 DATA를
오랫동안 가지고 있는상태에서 안정적으로 처리하는 모듈을 작성하기란 어렵습니다.
Persistence모듈은 고성능 유지 처리를 위해 Actor의 상태를 메모리에서 변경하고 유지하는 모듈로
메모리DB인 Redis와 목적이 유사하지만 , 단순하게 key base(NO SQL) 로 접근하고 저장하는 기술은 아닙니다.
데이터의 상태를 좀더 추상적(FSM디자인패턴)으로 관리하고 유지함으로,
서비스 특화된 고성능 서비스 모델을 설계 할수가 있습니다.
활용사례 : http://getakka.net/articles/persistence/persistent-fsm.html
역활별 저장 지원 모듈
In-memory journal plugin. -메모리 저장공간(고성능 Data상태 처리 목적)
In-memory snapshot store plugin. -메모리 스냅샷을 관리(복구력)
Local file system snapshot store plugin. -메모리의 휘발성에 대비(업데이트 포함 서버다운 대응,임시백업)
Cluster-sharding
Data를 실시간 분산처리 할수가 있습니다.
-스케일아웃을 위한 분산 메시지 전송 기술로, 클러스터 설정과, 메시지에서 분산 해시키를 지정하여 간단하게 이용가능합니다.
-맵리듀스를 통해 DB화되나? 하둡과 같은 순수 분산 저장기술이 아니며,영구적인 저장이 필요하면
로컬저장소를 작성하고 모두 설계 가능하나, DB저장기술은 AKKA의 스펙이아니며 보통 잘 연동하는데 집중하는것이 좋습니다.
참고 : https://krishnasblog.com/2012/11/11/scalatest-a-mapreduce-using-akka/
link : https://petabridge.com/blog/introduction-to-cluster-sharding-akkadotnet/
고성능실시간 이기종통신(타 개발플래폼과 데이터교환)
이기종과 통신기능은 AKKA의 스펙에 없습니다.
다만 어떠한 외부 인터페이스에 Actor와의 연결을통해 이기종통신(상호작용)
가능하며, Akka Stream을 통해 고성능 통신도 가능합니다.
Restapi 폴링방식은 일반적으로 가능한 시나리오이지만, 상대 플랫폼이 스트리밍을 지원하면
미들웨에서 성능문제로 가급적 사용을 안하는게 좋습니다. RestAPI와 Actor 연동부분은 별도로 다룰 예정입니다.AKKA는 이기종통신을 지원하지 않습니다.
대부분 고성능 메시지 처리설계는 AKKA.net 자체 에서 가능 합니다. 하지만 다음과 같은 시나리오를 생각해봅시다.
- A: .net을 이용중이지만, 쓸만한 형태소 분석기는 JAVA에만 있다.
- B: kafka / rabitmq 같은 메시지 처리기를 ,부가적인 기능으로 사용하고 싶다.
A: JAVA 로 직접 작성하고 웹소켓을 제공합니다. 사용처인 .net에서는 WevsocketActor 를 연결하여 형태소분석기를 사용합니다.
B : 각 솔류션이 제공하는 실시간 스트리밍 클라이언트 모듈을 Actor와 연결하여 사용합니다.
관련된 몇가지 참고자료
타 개발 플랫폼간 메시지 전송:
- Websocket을 Actor와 연결하여 Websocket을 제공 (https://www.playframework.com/documentation/2.6.x/ScalaWebSockets)
- JAVA JNI를 통해 JAVA ↔ CLR 연결
- JNBridge를 Actor와 연결 ( https://jnbridge.com/)
- 또는 이기종통신에 특화된 어떠한 메시지큐 서비스를 사용함
Actor Stream을 통해 : 상대 플래폼에 대한 스트리밍 방식을 이해하고 설계가능
- kafka - http://doc.akka.io/docs/akka-stream-kafka/current/home.html
- rabitmq - https://blog.scalac.io/2014/06/23/akka-streams-and-rabbitmq.html
필자가 SCALA로 작성한 웹소켓을 통한 형태소 분석기(with 꼬꼬마)
Akka를 이용한 머신러닝으로 확장
| Info |
|---|
AKKA는 텐서플로우 대체 플랫폼도 아니며 AI전용 플랫폼도아닙니다. AKKA가 제공하는 기능으로, 어떻게 머신러닝으로 확장가능한지? 심화학습을 하는데 목적이 있습니다. 수학적 지식이 필요한 머신러닝 자체는 이문서의 범위를 벗어나나 어떻게 분산컴퓨터를 이용해서 복잡한 연산을 분담하여 처리하는지? 순수하게 네트워크관점에서 분산처리방법은 AKKA가 추구하는 목적과 동일합니다. 이정도 이용가능한 수준이 되면 AKKA MASTER가 되었다고 볼수 있습니다. ( 필자도 그 단계에 못다가감)
|
link : http://getakka.net/articles/streams/workingwithgraphs.html (고성능 네트워크 데이터 전송및 연산 실현을 위해,AkkaStreams/Graphs로 확장이됩니다.)
link : http://www.cakesolutions.net/teamblogs/lifting-machine-learning-into-akka-streams
그외 Akka를 이용한 개인진행 저장소 : https://github.com/psmon/psmonSearch/blob/master/README.md