Page History
데이터 파이프라인
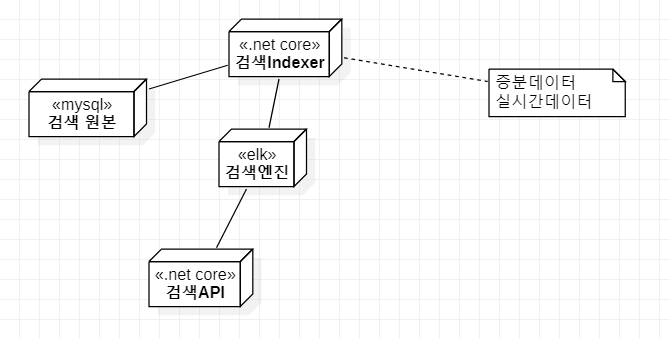
검색 데이터 파이프라인 을 , 원본 데이터는 RDB(mysql)에 유지하고 유지하고 ,검색 스키마(문서)를 엘라서틱서치와 동기화하여
사용자 레벨에서는 엘라서틱 서치의 고수준/ 고성능 검색기능을 활용할것이다.
데이터 파이프라인을 먼저 설명한 것은 검색 API를 만들기 위해 필요한 인프라는
RDB와 엘라서틱 서치이다의존 구성 인프라를 로컬에 모두 구성할수 있게, 도커 컴포져로 다음과 같이 구성하였습니다.
도커 컴포져로 구성하기
위치 : https://github.com/psmon/searchapi/tree/master/Infra
...
명령을 수행하면 검색 데이터 파이프라인에 필요한 구성요소가 모두 실행됩니다.
구성요소 요약:
- searchdb : 데이터 원본이 mysql에 저장되며 init.sql
...
- 을통해 최소 스키마셋팅및 기본 데이터가 적용됩니다.
- adminer : 웹환경에서 mysql의 데이터 조작이 가능하며, 테스터에게 다양한 데이터 조작기능 제공을 위한 툴입니다.
- elasticsearch : 엘라서틱 서치의 메인 엔진입니다.
- kibana : 엘라서틱 서치의 인덱스된 데이터를 시각화하고 관리할수 있는 툴입니다.
인덱싱 하기
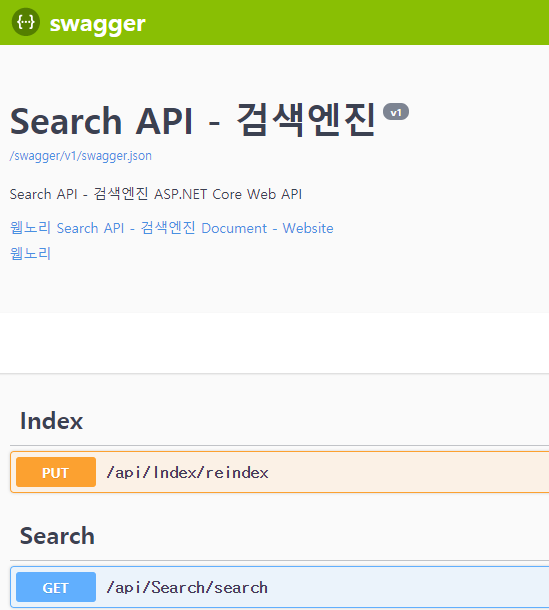
실행 : http://localhost:5000/swagger/index.html본 프로젝트는 Swagger로 모두 테스트및 싱행가능하며 ..., reindex를 하면 풀인덱싱처리를 합니다.
mysql의 스키마 데이터를 데이터를읽어와 엘라서틱 서치에 인덱싱처리를 합니다.
최초 버전은, 검색,풀인덱싱 두가지 기능만 존재하며
다음 검색에 필요한 주요기능을 고려하여 확장 개발 될 예정입니다.
검색처리를 위한 간단한 주요 용어정리:
- 인덱스 : 빠른 탐색을 위해 분류 정리가 된 상태
- 인덱싱 : 인덱스를 처리하고 있는 상태
- 풀 인덱싱 : 전체 자료를 다시 정리하고 있는 상태
- 증분업데이트 : 인덱스된 데이터의 문서를 부분 수정함
- 검색 : 인덱스 된 자료를 활용하여 빠르게 검색 하는 행위
검색 문서를 키바나에 연동
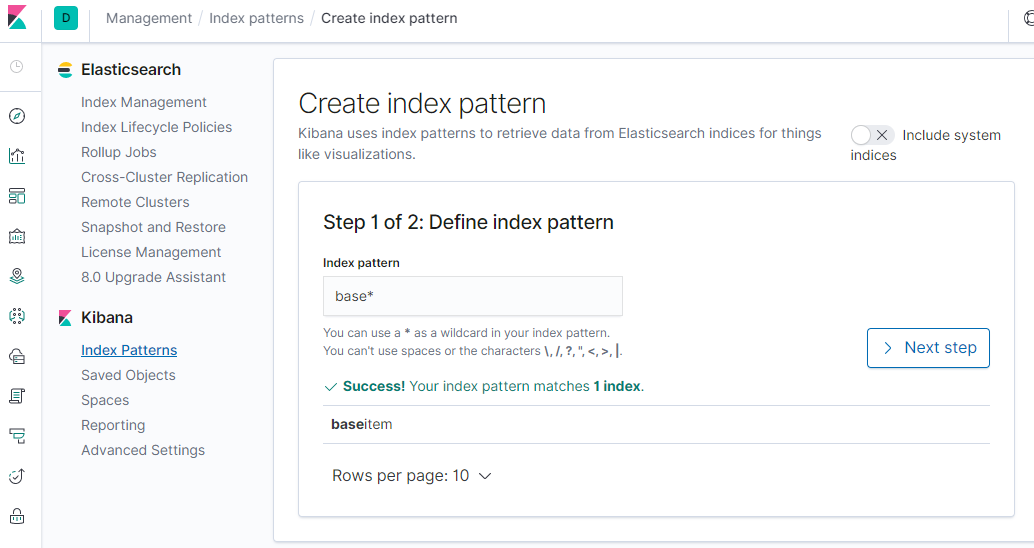
실행 : http://localhost:5601/app/kibana
...
키바나에 검색 인덱스 데이터를 연결하면 , 검색 데이터를 시각화할수 있으며
인덱스를 효율적으로 관리할수 있습니다.
키바나를 이용한검색
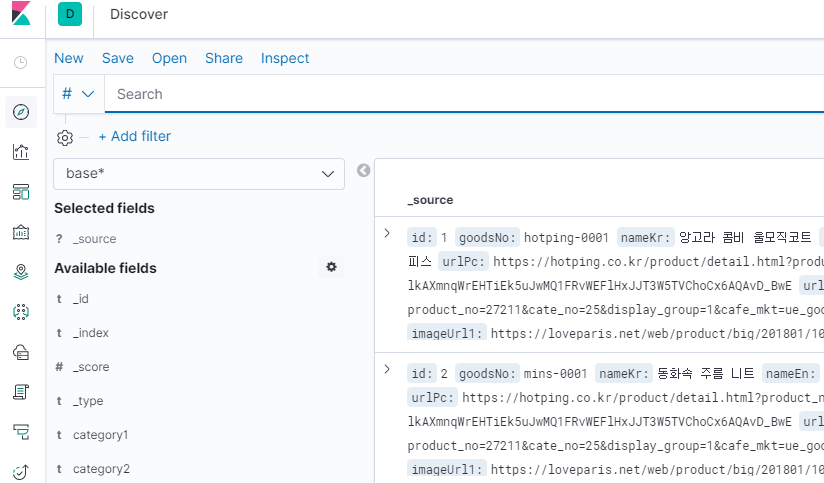
검색 문서가 키바나를 통해 검색이 되면.... 검색 API를 만들기 위한 인프라 준비가 완료되었습니다.
검색 API에서는 엘라서틱 서치가 제공하는 API를 활용하여 커스텀한 검색 API제작이 진행될 예정입니다.