Page History
데이터베이스는 지루하면 안된다라는 슬로건을 내건 모던 DB
전통 데이터베이스의 문제는 전문화된 기능을 각각 가지고 안정적으로 발전해온 그자체가 아니라 서비스가 확장되고 다양한 분석기능으로 확장되고
AI시대 특히 RAG를 강화 하기위해 다음과 같은 특화된 DB를 모두 필요로 하게됩니다.
- RDB
- Elastic Search
- Mongo Document DB
- Neo4J Graph DB
- Vector DB
전통적 DB를포함 특화된 NoSQL 모두 다뤄 필연적으로 발생하는 불가피한 작업을 Boring 이라 표현하는것같습니다.
다양한 DB를 관리함으로 발생하는 관리비용뿐만 아니라~ 데이터가 이동됨에 따른 가공과정의 파이프라이닝을 다루는 높은수준의 ETL 능력을 가진 팀을 필요로하게됩니다.
필요로하는 ETL 파이프라이닝
| Code Block | ||
|---|---|---|
| ||
[RDB / Mongo] [File Upload] [API]
│ │ │
▼ ▼ ▼
┌─────────┐ ┌──────────┐ ┌─────────────┐
│ Debezium│ │ Fluent Bit│ │ REST Events │
└─────────┘ └──────────┘ └─────────────┘
▼ ▼ ▼
┌─────────────────────┐
│ Apache Kafka │
└─────────────────────┘
▼
┌─────────────────────┐
│ Flink / Beam / NiFi│ ← 변환, 정제
└─────────────────────┘
▼ ▼ ▼ ▼
[Elastic] [Mongo] [Neo4j] [Vector DB]
|
데이터 엔지니어팀이 이미 존재하다면 이러한 파이프라인을 이미 구축하고 그 기반으로 성장을 가속화를 했을테지만
소규모로 구성된 스타트업은 핵심 서비스도 개발하면서 동시에 고도화된 데이터파이프라이닝을 구축할 여력이 없습니다.
대안으로 클라우드가 제공하는 파이프라인툴은 Nosql과 연동되어 ETL플랫폼을 제공하며 그 자체로 휼륭하지만
트래픽에 따른 인프비용 증가를 통제하기 쉽지 않습니다.
AI OPS 등장

AI 를 활용하는 AI OPS의 등장으로 MSA의 API GateWay는 Context Gateway로 전환을 준비하고 기중중심에서 문맥중심으로 활용해야할 DB와 인프라는 더 복잡해자고
활용 인프라아키텍처는 더 복잡해지고 더 많은 이벤트를 처리할것이 분명해 보입니다.
✅ 1. Next 아키텍처의 키워드
핵심 키워드 | 설명 |
|---|---|
| AI-Native | AI가 모든 서비스 흐름에 기본 내장됨 (예: 추천, 예측, 분류) |
| Context-Aware | 사용자, 시스템 상태에 따라 유동적으로 동작 (MCP 적용) |
| Event-Driven | 모든 변화가 이벤트로 감지/처리됨 (Kafka, NATS) |
| Composable | 기능을 블록처럼 재조립 (Low-code, Function as a Service) |
| Autonomous Ops | 스스로 모니터링, 복구, 확장하는 인프라 |
| Multi-Agent Collaboration | 여러 AI Agent가 분산되어 협력 작업 수행 |
전통RDB진영 또한 Nosql기능을 탑재해가며 발전해 나가겠지만~ 스몰비즈니스 개발팀이 각각 특화된 모든 DB를 다루고 복잡한 파이프라인을 다룰 역량을 가지기 까지
너무오랜 시간이 걸리기때문에 다양한 데이터베이스를 다룸으로 발생하는 복잡성및 비용을 줄이기위해 하루가 다르게 변화하는 AI의 인기에는 가려질수 있겠지만
조용하게 이용이 될것으로 예상해봅니다. ( 전통DB를 필수로 사용해야하다는 인식의 전환)
서론이 길었으며~ 다양한 하이브리드 모던 DB중 하나인 RavenDB의 특징과 사용법 그리고 Akka.net에서의 확장 사용법을 간단하게 알아보겠습니다.
✅ RavenDB 특징
| 항목 | 설명 |
|---|---|
| Document Store | JSON 기반의 문서 저장 (MongoDB처럼) |
| Full-Text Search 내장 | Lucene 기반 검색엔진 포함 (Elasticsearch 대체 가능) |
| Graph-Like Traversal 지원 | Include, Load, RelatedDocuments 로 Graph traversal 흉내 가능 |
| 벡터 검색 (Vector Search) | 6.0 이상 버전에서 Vector search 지원 (Preview → Stable 예정) |
| ACID 트랜잭션 지원 | NoSQL 중 드물게 단일 DB 내 ACID 지원 |
| 자동 인덱싱/쿼리 최적화 | 쿼리 기반으로 자동 인덱싱 생성 |
| Change Vector / ETL 기능 내장 | 다른 Raven 클러스터 또는 외부 시스템으로 데이터 복제 가능 |
| 클라우드 + 온프렘 지원 | 다양한 배포 환경 대응 |
| Sharding + Replication | 분산 구조 대응 가능 (Sharded DB) |
✅ 기존 DB 구성 중 대체 가능한 역할
| 기존 시스템 | RavenDB로 대체 가능 여부 | 설명 |
|---|---|---|
| MongoDB (Document DB) | ✅ 완전 대체 | JSON 기반 문서 저장, 컬렉션 → 문서 분리 모델 |
| Elasticsearch | ✅ 부분 대체 | Full-text 검색 지원, 복잡한 분석쿼리는 제한적이나 일반 검색에는 충분 |
| Neo4j (Graph DB) | ⚠️ 간단한 관계 트래버설은 가능 | 명시적 Graph 모델링은 어려움 (복잡한 네트워크 분석에는 부적합) |
| Vector DB (예: Weaviate, Milvus) | ✅ 단순 벡터 검색은 대체 가능 | 다차원 벡터 검색 API 제공, 모델링+쿼리 결합 쉬움 |
| RDB (CRUD/정형) | ⚠️ 단순 CRUD는 가능, 복잡한 조인과 트랜잭션은 제한적 | 정형 테이블 기반보다는 문서 중심 모델 필요 |
| Code Block | ||
|---|---|---|
| ||
version: '3.8'
services:
ravendb:
image: ravendb/ravendb:ubuntu-latest
container_name: ravendb
ports:
- "9000:8080"
environment:
- RAVEN_Setup_Mode=None
- RAVEN_License_Eula_Accepted=true
volumes:
- ravendb_data:/ravendb/data
- ravendb_logs:/ravendb/logs
volumes:
ravendb_data:
ravendb_logs: |
IDE 환경
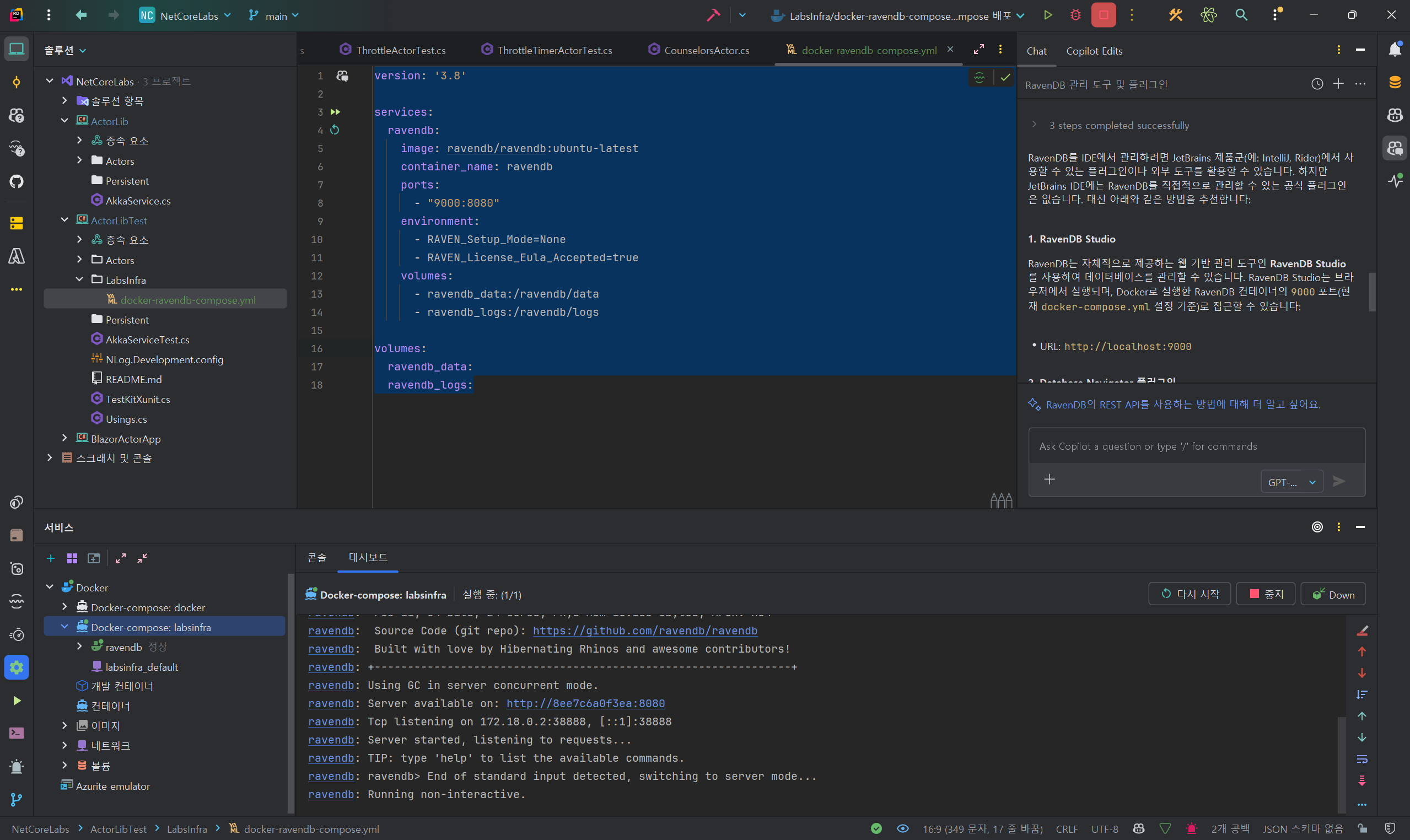
젯브레인 시리즈에서 지원하는 DataBase 연동 플러그인

- 클라우드 DB를 포함 다양한 전통DB를 연동해 IDE내에서 개발에서 활용가능 하지만~ RavenDB는 아쉽지만 아직 공식 플러그인은 찾지 못했습니다.
RavenDB 웹관리툴
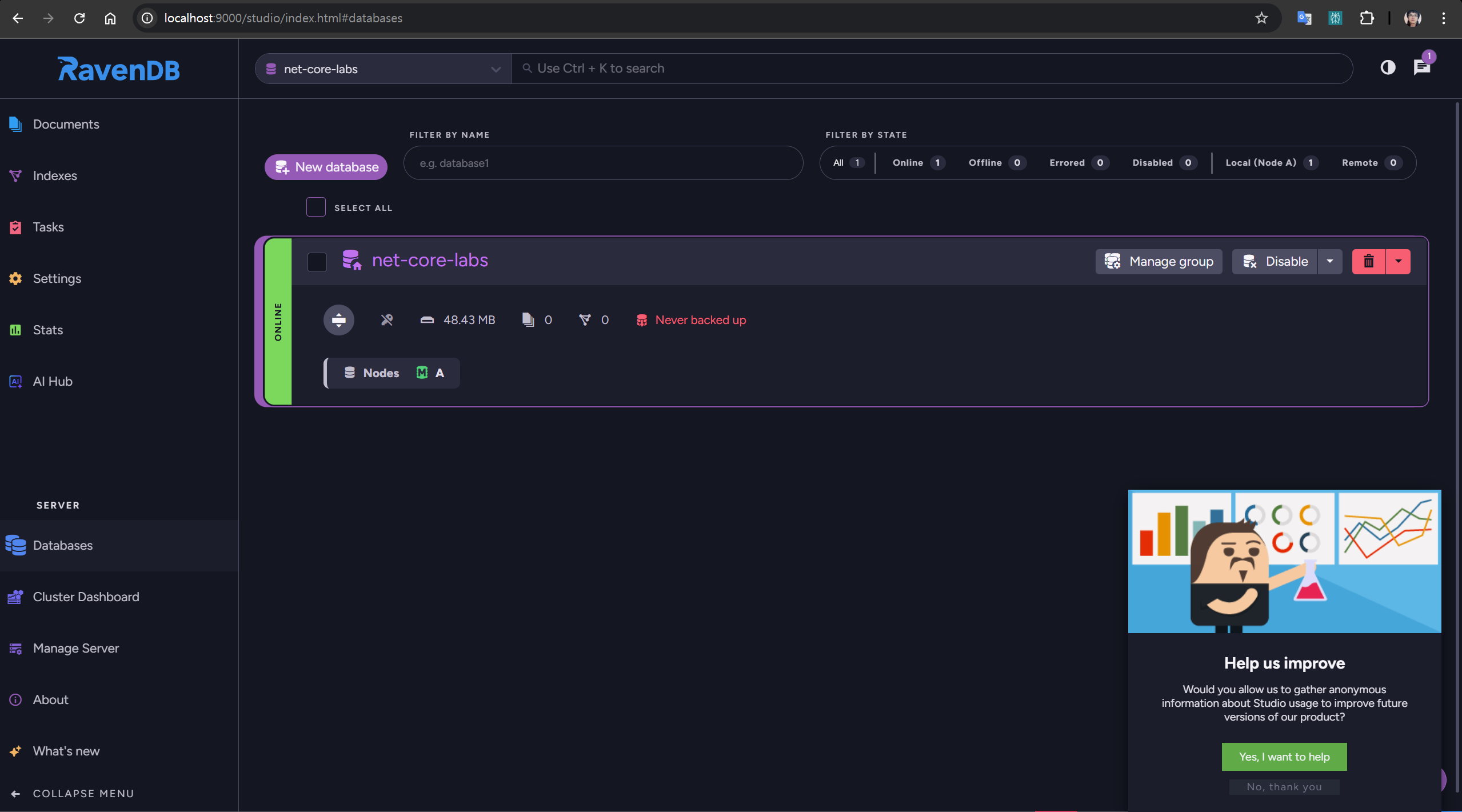
- DB를 관리할 웹툴을 포함 기본제공하기 때문에
