
AKKA 액터모델은 JVM 기반에 작동하며 SCALA/JAVA뿐만아니라 Kotlin으로도 이용가능하며
TypedActor 액터모델을 활용해 Kotlin으로 작동시켜보는 샘플모음집입니다.
액터모델 러닝커버를 낮추기위해 Copilot를 통해 액터모델을 생성하고 개선해 가는 방법을 채택하였으며 코틀린으로 시작하는 개발팀과 함께 학습하기 위해 작성을 시작하였습니다.
- Copilot가 이해하기 쉬운 코드를 작성하고 설명하고 작동 코드를 유닛테스트를 통해 설명하는 방식 채택
목차:
- [Kotlin] HelloActor
- [Kotlin] HelloStateActor
- [Kotlin] HelloStateActor with Throttle
- [Kotlin] HelloStateActor with Timer
- [Kotlin] BulkProcessor Actor
- [Kotlin] SuperVisorActor
- [Kotlin] RouterActor
- [Kotlin] Actor With WebSocket
- [Kotlin] ActiveObject Pattern
- [Kotlin] PersistentDurableStateActor
- [Kotlin] Cluster Actor
- [Kotlin] Actor with R2DBC - Pekko
- [Kotlin] AkkaStream
- 분산처리 Reactive 웹소켓 by 액터모델
- Realtime event unit testing with Actor
GIT :
kotlin spring-boot-starter-webflux 템플릿으로 시작되었으며 akka 종속및 유닛테스트 종석은 다음을이용
의존성
val scalaVersion = "2.13"
val akkaVersion = "2.7.0"
dependencies {
// Akka
implementation(platform("com.typesafe.akka:akka-bom_$scalaVersion:$akkaVersion"))
// Akka UnTyped Actor
implementation("com.typesafe.akka:akka-actor_$scalaVersion:$akkaVersion")
implementation("com.typesafe.akka:akka-stream_$scalaVersion:$akkaVersion")
// Akka Typed Actor
implementation("com.typesafe.akka:akka-actor-typed_$scalaVersion:$akkaVersion")
testImplementation("com.typesafe.akka:akka-actor-testkit-typed_$scalaVersion:$akkaVersion")
// Logging
implementation("ch.qos.logback:logback-classic:1.4.12")
implementation("com.typesafe.akka:akka-slf4j_$scalaVersion:$akkaVersion")
// TestToolKit
testImplementation("com.typesafe.akka:akka-testkit_$scalaVersion:$akkaVersion")
// JUnit
testImplementation("org.springframework.boot:spring-boot-starter-test")
testImplementation("io.projectreactor:reactor-test")
testImplementation("org.jetbrains.kotlin:kotlin-test-junit5")
testRuntimeOnly("org.junit.platform:junit-platform-launcher")
testImplementation("org.junit.jupiter:junit-jupiter-api:5.9.3")
testRuntimeOnly("org.junit.jupiter:junit-jupiter-engine:5.9.3") }
- AKKA 공식 버전은 위와같지만 2.6.x 포팅된 오픈소스인 pekko로 변환할수도있습니다.
현대 시스템에 새로운 프로그래밍 모델이 필요한 이유
액터 모델은 수십 년 전 Carl Hewitt 가 고성능 네트워크에서 병렬 처리를 처리하는 방법으로 제안했습니다. 당시에는 사용할 수 없었던 환경이었습니다. 오늘날 하드웨어 및 인프라 기능은 Hewitt의 비전을 따라잡고 능가했습니다. 결과적으로 까다로운 요구 사항이 있는 분산 시스템을 구축하는 조직은 기존의 객체 지향 프로그래밍(OOP) 모델로는 완전히 해결할 수 없는 문제에 직면하지만 액터 모델에서는 이점을 얻을 수 있습니다.
오늘날 액터 모델은 매우 효과적인 솔루션으로 인정받을 뿐만 아니라 세계에서 가장 까다로운 애플리케이션 중 일부에 대한 프로덕션에서 입증되었습니다. 액터 모델이 해결하는 문제를 강조하기 위해 이 주제에서는 기존 프로그래밍 가정과 최신 멀티스레드, 멀티 CPU 아키텍처의 현실 간의 다음과 같은 불일치에 대해 설명합니다.
캡슐화의 과제¶
OOP의 핵심 기둥은 캡슐화 입니다 . 캡슐화는 객체의 내부 데이터가 외부에서 직접 접근할 수 없음을 지시합니다. 큐레이트된 메서드 집합을 호출하여서만 수정할 수 있습니다. 객체는 캡슐화된 데이터의 불변성을 보호하는 안전한 작업을 노출할 책임이 있습니다.
예를 들어, 정렬된 이진 트리 구현에 대한 연산은 트리 순서 불변성을 위반하는 것을 허용해서는 안 됩니다. 호출자는 순서가 그대로 유지되기를 기대하며 특정 데이터에 대해 트리를 쿼리할 때 이 제약 조건에 의존할 수 있어야 합니다.
OOP 런타임 동작을 분석할 때, 우리는 때때로 메서드 호출의 상호작용을 보여주는 메시지 시퀀스 차트를 그립니다. 예를 들어:

불행히도, 위의 다이어그램은 실행 중 인스턴스의 생명선을 정확하게 표현하지 못합니다 . 실제로 스레드는 이러한 모든 호출을 실행하고 불변식의 적용은 메서드가 호출된 동일한 스레드에서 발생합니다. 실행 스레드로 다이어그램을 업데이트하면 다음과 같습니다.

여러 스레드 에서 무슨 일이 일어나는지 모델링하려고 하면 이 설명의 중요성이 명확해집니다 . 갑자기 깔끔하게 그린 다이어그램이 부족해집니다. 여러 스레드가 같은 인스턴스에 액세스하는 것을 보여드리려고 할 수 있습니다.
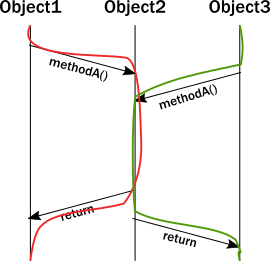
두 스레드가 동일한 메서드에 들어가는 실행 섹션이 있습니다. 불행히도 객체의 캡슐화 모델은 해당 섹션에서 발생하는 일에 대해 아무것도 보장하지 않습니다. 두 호출의 명령어는 임의의 방식으로 끼워넣을 수 있으며, 이는 두 스레드 간의 어떤 유형의 조정 없이 불변성을 그대로 유지할 수 있는 희망을 제거합니다. 이제 이 문제가 많은 스레드의 존재로 인해 더 복잡해진다고 상상해 보세요.
이 문제를 해결하는 일반적인 방법은 이러한 메서드 주위에 잠금을 추가하는 것입니다. 이렇게 하면 주어진 시간에 최대 하나의 스레드만 메서드에 진입할 수 있지만, 이는 매우 비용이 많이 드는 전략입니다.
- 잠금은 동시성을 심각하게 제한하며 , 최신 CPU 아키텍처에서는 비용이 많이 들고, 스레드를 일시 중단하고 나중에 복원하기 위해 운영 체제에서 많은 작업을 해야 합니다.
- 호출자 스레드는 이제 차단되어 다른 의미 있는 작업을 수행할 수 없습니다. 데스크톱 애플리케이션에서도 이는 용납할 수 없으며, 긴 백그라운드 작업이 실행 중일 때에도 애플리케이션의 사용자 중심 부분(UI)이 반응하도록 유지해야 합니다. 백엔드에서 차단은 완전히 낭비입니다. 새 스레드를 시작하면 이를 보상할 수 있다고 생각할 수 있지만 스레드는 비용이 많이 드는 추상화이기도 합니다.
- 잠금 장치는 교착 상태라는 새로운 위협을 초래합니다.
이러한 현실은 서로 이길 수 없는 상황을 초래합니다.
- 충분한 잠금장치가 없으면 국가가 손상됩니다.
- 많은 잠금장치가 있으면 성능이 저하되고 교착 상태가 매우 쉽게 발생합니다.
또한 잠금은 실제로 로컬에서만 잘 작동합니다. 여러 머신에서 조정하는 경우 유일한 대안은 분산 잠금입니다. 불행히도 분산 잠금은 로컬 잠금보다 몇 배나 덜 효율적이며 일반적으로 확장에 대한 엄격한 제한을 부과합니다. 분산 잠금 프로토콜은 여러 머신에서 네트워크를 통해 여러 번의 통신 왕복이 필요하므로 대기 시간이 엄청나게 늘어납니다.
객체 지향 언어에서 우리는 일반적으로 스레드나 선형 실행 경로에 대해 거의 생각하지 않습니다. 우리는 종종 시스템을 메서드 호출에 반응하고, 내부 상태를 수정한 다음 메서드 호출을 통해 서로 통신하여 전체 애플리케이션 상태를 앞으로 구동하는 객체 인스턴스의 네트워크로 생각합니다.

그러나 멀티스레드 분산 환경에서 실제로 일어나는 일은 스레드가 메서드 호출을 따라 객체 인스턴스의 네트워크를 "횡단"한다는 것입니다. 결과적으로 스레드가 실제로 실행을 주도합니다.
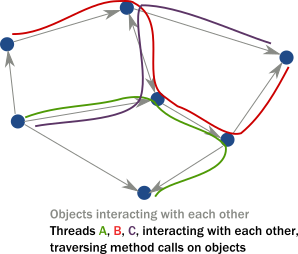
요약하면 :
- 객체는 단일 스레드 액세스에 직면해서만 캡슐화(불변성 보호)를 보장할 수 있고, 멀티 스레드 실행은 거의 항상 손상된 내부 상태로 이어진다. 모든 불변성은 동일한 코드 세그먼트에 두 개의 경쟁 스레드가 있으면 위반될 수 있다.
- 잠금은 여러 스레드로 캡슐화를 유지하는 자연스러운 대책처럼 보이지만 실제로는 비효율적이며 실제 규모의 모든 애플리케이션에서 쉽게 교착 상태로 이어집니다.
- 잠금장치는 지역적으로 작동하며, 분산시키려는 시도도 있지만 확장 가능성이 제한적입니다.
현대 컴퓨터 아키텍처에서의 공유 메모리의 환상¶
80~90년대의 프로그래밍 모델은 변수에 쓰는 것이 메모리 위치에 직접 쓰는 것을 의미한다고 개념화했습니다(로컬 변수가 레지스터에만 존재할 수 있다는 사실을 다소 흐리게 만듭니다). 현대 아키텍처에서 - 사물을 조금 단순화하면 - CPU는 메모리에 직접 쓰는 대신 캐시 라인 에 씁니다 . 이러한 캐시의 대부분은 CPU 코어에 로컬합니다. 즉, 한 코어의 쓰기는 다른 코어에서 볼 수 없습니다. 로컬 변경 사항을 다른 코어, 그리고 다른 스레드에서 볼 수 있도록 하려면 캐시 라인을 다른 코어의 캐시로 전송해야 합니다.
JVM에서 우리는 휘발성 마커나 Atomic래퍼를 사용하여 스레드 간에 공유할 메모리 위치를 명시적으로 표시해야 합니다. 그렇지 않으면 잠긴 섹션에서만 액세스할 수 있습니다. 왜 모든 변수를 휘발성으로 표시하지 않을까요? 코어 간에 캐시 라인을 전송하는 것은 매우 비용이 많이 드는 작업이기 때문입니다! 그렇게 하면 관련 코어가 추가 작업을 수행하지 못하게 암묵적으로 지연되고 캐시 일관성 프로토콜(CPU가 주 메모리와 다른 CPU 간에 캐시 라인을 전송하는 데 사용하는 프로토콜)에 병목 현상이 발생합니다. 그 결과 속도가 엄청나게 느려집니다.
이런 상황을 알고 있는 개발자라도 어떤 메모리 위치를 휘발성으로 표시해야 할지, 어떤 원자 구조를 사용해야 할지 파악하는 것은 어려운 일입니다.
요약하면 :
- 더 이상 실제 공유 메모리는 없으며, CPU 코어는 네트워크의 컴퓨터가 하는 것처럼 데이터 덩어리(캐시 라인)를 서로에게 명시적으로 전달합니다. CPU 간 통신과 네트워크 통신은 많은 사람이 깨닫는 것보다 공통점이 많습니다. 메시지 전달은 이제 CPU나 네트워크 컴퓨터 간에 표준이 되었습니다.
- 공유로 표시된 변수를 사용하거나 원자적 데이터 구조를 사용하여 메시지 전달 측면을 숨기는 대신, 더욱 규율 있고 원칙적인 접근 방식은 상태를 동시 엔터티에 국한시키고 메시지를 통해 동시 엔터티 간에 데이터나 이벤트를 명시적으로 전파하는 것입니다.
호출 스택의 환상¶
오늘날 우리는 종종 호출 스택을 당연하게 여깁니다. 하지만, 호출 스택은 다중 CPU 시스템이 일반적이지 않았기 때문에 동시 프로그래밍이 그렇게 중요하지 않았던 시대에 발명되었습니다. 호출 스택은 스레드를 교차하지 않으므로 비동기 호출 체인을 모델링하지 않습니다.
문제는 스레드가 작업을 "백그라운드"에 위임하려고 할 때 발생합니다. 실제로 이는 다른 스레드에 위임하는 것을 의미합니다. 이는 호출이 스레드에 엄격하게 로컬하기 때문에 간단한 메서드/함수 호출이 될 수 없습니다. 일반적으로 발생하는 일은 "호출자"가 작업자 스레드("호출 대상")가 공유하는 메모리 위치에 객체를 넣고, 그러면 해당 스레드가 어떤 이벤트 루프에서 객체를 집어올리는 것입니다. 이를 통해 "호출자" 스레드는 계속 진행하여 다른 작업을 수행할 수 있습니다.
첫 번째 문제는 "호출자"에게 작업 완료를 어떻게 알릴 수 있는가입니다. 하지만 더 심각한 문제는 작업이 예외로 실패할 때 발생합니다. 예외는 어디로 전파될까요? 실제 "호출자"가 누구인지 전혀 무시한 채 작업자 스레드의 예외 처리기로 전파됩니다.
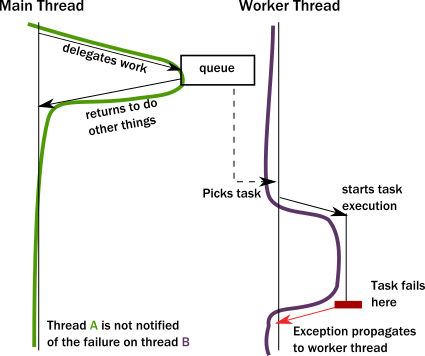
심각한 문제입니다. 워커 스레드는 이 상황을 어떻게 처리할까요? 실패한 작업의 목적을 일반적으로 알지 못하기 때문에 문제를 해결할 수 없을 가능성이 큽니다. "호출자" 스레드는 어떻게든 알림을 받아야 하지만 예외로 풀릴 호출 스택이 없습니다. 실패 알림은 사이드 채널을 통해서만 수행할 수 있습니다. 예를 들어 "호출자" 스레드가 준비가 되면 결과를 기대하는 곳에 오류 코드를 넣는 것입니다. 이 알림이 없으면 "호출자"는 실패 알림을 받지 못하고 작업이 손실됩니다! 이는 네트워크 시스템이 작동하는 방식과 놀랍게도 비슷합니다. 여기서 메시지/요청은 아무런 알림 없이 손실되거나 실패할 수 있습니다.
이런 나쁜 상황은 상황이 정말 잘못되어 스레드에 의해 지원되는 작업자가 버그를 만나 복구할 수 없는 상황에 처하면 더욱 악화됩니다. 예를 들어, 버그로 인해 발생한 내부 예외가 스레드의 루트까지 버블링되어 스레드가 종료됩니다. 그러면 스레드가 호스팅하는 서비스의 정상적인 작동을 누가 다시 시작해야 하며, 알려진 양호한 상태로 어떻게 복원해야 하는지에 대한 의문이 즉시 제기됩니다. 언뜻 보기에 이는 관리하기 쉬운 것처럼 보일 수 있지만 갑자기 새롭고 예상치 못한 현상에 직면하게 됩니다. 스레드가 현재 작업하고 있던 실제 작업이 더 이상 작업을 가져오는 공유 메모리 위치(일반적으로 대기열)에 없습니다. 사실, 예외가 맨 위에 도달하여 모든 호출 스택을 풀었기 때문에 작업 상태가 완전히 손실됩니다! 네트워킹이 관련되지 않은 로컬 통신(메시지 손실이 예상됨)임에도 불구하고 메시지를 잃었습니다.
요약하면:
- 현재 시스템에서 의미 있는 동시성과 성능을 달성하려면 스레드가 차단 없이 효율적인 방식으로 서로 작업을 위임해야 합니다. 이러한 작업 위임 동시성 스타일(그리고 네트워크/분산 컴퓨팅의 경우 더욱 그렇습니다)에서는 호출 스택 기반 오류 처리가 중단되고 새롭고 명시적인 오류 신호 메커니즘을 도입해야 합니다. 실패는 도메인 모델의 일부가 됩니다.
- 작업 위임이 있는 동시 시스템은 서비스 오류를 처리하고 이를 복구할 수 있는 원칙적인 수단을 가져야 합니다. 이러한 서비스의 클라이언트는 재시작 중에 작업/메시지가 손실될 수 있다는 사실을 알고 있어야 합니다. 손실이 발생하지 않더라도 이전에 대기열에 추가된 작업(긴 대기열), 가비지 수집으로 인한 지연 등으로 인해 응답이 임의로 지연될 수 있습니다. 이러한 상황에 직면하여 동시 시스템은 네트워크/분산 시스템과 마찬가지로 타임아웃 형태로 응답 마감일을 처리해야 합니다.
다음으로, 액터 모델을 사용하여 이러한 과제를 어떻게 극복할 수 있는지 살펴보겠습니다.
Next :
AKKA 액터플랫폼을 활용하는 기업들
AKKA 액터모델이 국내활용 사례가 잘없어 인기있는것은 아니지만 리액티브 스트림이 활발한 글로벌 기업의 경우 많은 활용사례가 있습니다.
액터모델은 언어/플랫폼 종속적이지 않는 개발모델로, 자바진영으로 한정 없이 활용 Case는 더 많을것으로 추정합니다.
- 라인 - https://engineering.linecorp.com/ko/blog/the-architecture-behind-chatting-on-line-live
- 유노믹 - https://www.aitimes.kr/news/articleView.html?idxno=20569
- 테슬라 - https://akka.io/blog/external/2020/03/24/external-tesla-virtual-power-plant
- WallMart - https://www.lightbend.com/case-studies/walmart-boosts-conversions-by-20-with-lightbend-reactive-platform
- more :