Ensure the health and availability of your Reactive applications
Reactive applications require a new approach to monitoring that goes beyond traditional techniques. Among other things, you need to know how these distributed, asynchronous applications are designed, how their architectures change dynamically over time, what to monitor and the metrics that matter, and how to quickly troubleshoot any problems.
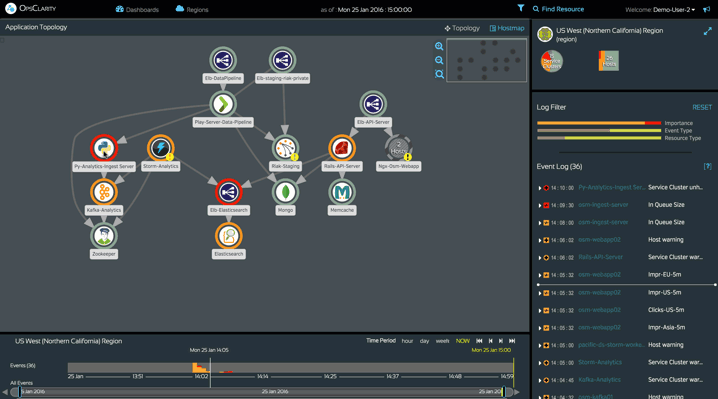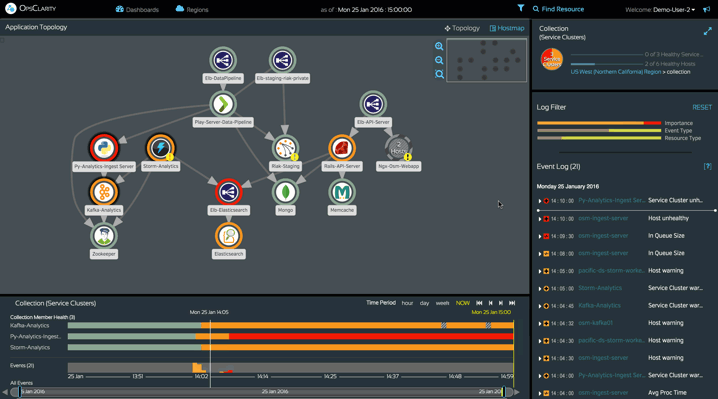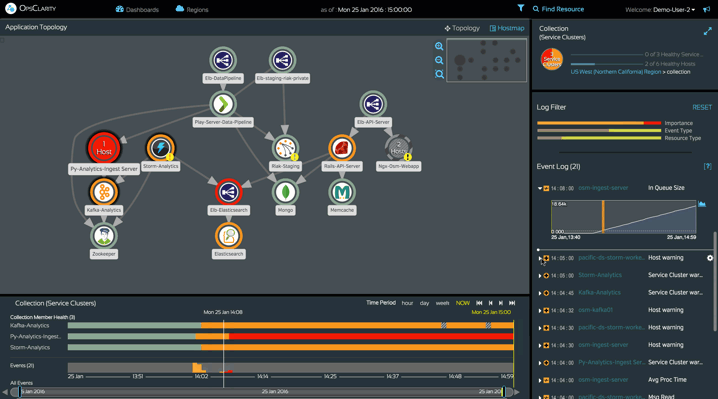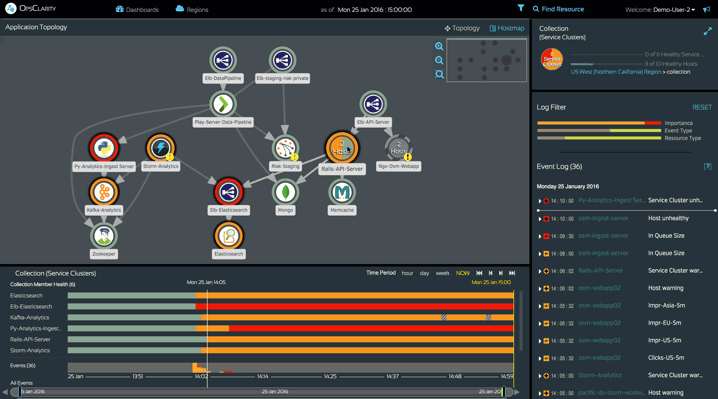
Lightbend Enterprise Suite’s Intelligent Monitoring features provide everything you need to monitor your Reactive applications, including comprehensive, high-quality telemetry, automated discovery and visualization, automated correlation and intelligent, machine learning-driven insights.
Taken together, these best-in-class features let you quickly, easily and continually ensure the health and availability of your Reactive applications.